昨今のコロナウィルス感染拡大に伴う対応として弊社ではリモートワーク中心の働き方に変化し1年ほどが経過しました。 働き方が大きく変わっていった状況の中で、滞りなくチーム開発が進められた要因の1つが毎週開催している振り返り会にあったのではないかと私は考えています。 今回は、以前私が所属していたDELISH KITCHENのバックエンド開発のチームとプロダクトマネージャーとの間ではどのように振り返り会を実践してきたのかを紹介させていただきます。 計画して実行した結果に対して「何が良かったのか?何が悪かったのか?次はどうするのか」を考える、いわゆるPDCAサイクルを回すことの有意性については今更議論する必要がないと思います。 PDCAサイクルによる改善活動は、個人で行う仕事であれば自分がやったことを見直し次に活かせば良いので簡単に実現できるのですが、チームで行う仕事の場合は誰か1人の力だけで行うのは非常に困難です。 リーダーが1人でチームの改善活動を行う場合、リーダーの力量以上にチームが成長することは難しいでしょう。それはリーダーの視点から気付ける課題や改善策に限定されてしまうからです。 リーダーからすると取るに足らない些細な課題が実は複数のメンバーが感じている重要な課題かもしれませんし、ある課題に対してリーダーが考えつかないような改善策が他のメンバーから提案されるかもしれません。 基点となる1人のフィルターを通してしまうと、その人の考えに大きく依存してしまいチームはいずれうまく動かなくなることが予想されます。 振り返り会では様々な課題をチームの課題として捉え、メンバーが相互作用しながら解決に導くことでチームのPDCAサイクルを回します。 また、プラクティスの共有や課題についての議論を行う対話の場ができることによって「協調するチーム」作りに寄与する重要な機会になると考えています。 チームで行っている振り返り会は、週に1回/半期に1回行う定期的なものとプロジェクトごとに行う不定期なものがありますが、今回は週に1回定期的に開催しているやり方について取り上げたいと思います。 やり方はKPTをベースにいくつかのオリジナリティを加えており、参加メンバーはPdMとエンジニアの4-6人ほどで開催しています。
全体は以下のような流れになっています。 振り返り会の進行を行うファシリテーターは職種によらず参加メンバー全員の持ち回りで進行しています。これはメンバーそれぞれがやり方を工夫する余地を持たせるためです。 最適な振り返りの方法はチームや状況によって変わるため自分がファシリテーターの時には自由にアレンジすることが許されており、振り返り自体をより良くするための案として採用しています。 また、ファシリテーターを固定してしまうとどうしても参加させられてる感・他人事感が出てきてしまうと考えているため、持ち回りにすることで自分たちのために開催しているという当事者意識を持ちやすくする効果があります。 振り返り会で最初にやるべきことは、何について振り返るのか認識を合わせることです。 1週間を振り返るという抽象的なテーマで始めると出てくるトピックの粒度にばらつきが生じ時間配分がとても難しくなるでしょう。 振り返りの勘所がわかっているチームであれば問題ありませんが、多くのチームでは具体的なテーマを決めて何について話すかを明確にした方がスムーズに進行できるでしょう。 多くの問題を抱えたチームが自由に問題点を列挙するような振り返り会の場合、広く浅く問題について話したことで満足してしまい結局何も解決されていないなんてことは良くあるのではないでしょうか。 定期開催している場合1回の振り返り会にかける時間は短いでしょうし、次の振り返り会までに取り組めるアクションは限られるため一度に多くの問題を解決しようとせず、まずは問題の1つをテーマとして取り上げて確実に改善に取り組んでいくのが良いと思います。 と、書きましたが実際にチームでは特にテーマを決めずに1週間を振り返っています。 これは1年以上毎週振り返り会を続けており、チームの中で共通のナレッジになっているものやすでに解決した課題が大半で抽象的なテーマでもうまく進められる状態になっているからです。 2回目以降の振り返り会の場合、まずは前回の振り返り会を確認するところから始めます。 前回決めたアクションに取り組むことができた場合結果はどうだったのか、継続していくべきかを話し合います。取り組んでみた結果効果がなければ他にやってみたい案を考えます。 取り組むことができなかった場合、なぜできなかったかを考えます。時間がなかっただけなのか何か問題があるのかを明らかにします。何度も時間がないことが理由になる場合、そのアクションは重要ではないことが多いため思い切ってやめてしまうこともあります。 前回あがった問題の中でまだ解決できていない問題についてもここで確認します。何か進展があれば議論し、解決のためにやってみたいことがあれば案を出し合います。 大きな問題は1回の振り返り会で解決できないことがあるため、このように次回に持ち越していき少しずつ解決のために取り組んでいきます。 今週やったこと・良かったことをできるだけ多くあげていきます。 これはYWTという振り返り手法におけるY(やったこと)とKPTにおけるKEEP(今後も続けたいことや良かったこと)を融合させたフェーズです。 Y(やったこと)もあげるのは今週起きたことを全員で思い出すためと、話しているうちに良かったことや課題が見つかることがあるためです。 また、良かったことのみとすると素晴らしい出来事をあげなくてはいけない気がして、全く出てこなくなってしまうことを避けるためです。 良かったこととしてあげるほどでもないことを、やったこととしてならば言いやすいこともあります。 例えば「〇〇の機能を無事リリースしました!」などです。スケジュール通り問題なくリリースできたならば良かったこととして捉えられますが、人によっては当然のことと考えるかもしれません。 深掘りしてみると実はスケジュール通り進めるために様々な工夫しており、チームのナレッジにすべきことが隠れているかもしれません。 ここで重要なのは「問題点」ではなく「もっと良くできそうなこと」を洗い出すことです。 「問題点」としてしまうと現在発生している問題にのみフォーカスしてしまい、今後問題になりそうなことやなんとなくモヤモヤしていることについて話す場がなくなってしまいます。 問題になっていない些細なことを共有するのは非常に大切です。 誰も気付いていない今後大きな問題になる可能性に気づくことができるかもしれませんし、話してみた結果問題ではないことを知ることができるかもしれません。 いずれにせよ周りのメンバーが事象に対してどのように捉えているかを知れる機会になり、チーム内の相互理解を促進させてくれるはずです。 実際の振り返り会で「プルリクエストのレビュー依頼が多く出ていたので優先的に進めるべきだった」という意見がありました。 当事者としてはレビューを溜めてしまったことに問題を感じて出した意見だと思いますが、チームとしては限られたリソースの中でレビューを回しており、差し込みの対応依頼などもあったため妥当な対応で問題ではなかったという着地になりました。 「問題ではなかった」という結論を導くための対話を通じて、チーム内にこのような状況であれば「レビューが溜まることがある」という共通認識が生まれています。 今後同じ状況になった時レビューする側は必要以上に焦ってレビューせずにすみますし、レビューされる側も時間がかかりそうということを事前に認識することができます。 このように振り返り会では問題を解決するだけでなく、共通認識を作ることができるという点でも効果的な機会となっています。 このフェーズでは問題を起こした誰かを責めるのではなく、チームとしてもっと良くできそうなことを考えるというポジティブな議論指向が重要なポイントだと思います。 他のフェーズにも共通して言えることですが意見を出すハードルを下げることが大切で、課題感はあるけど自分が責められそうだからやめておこう、、、とならない雰囲気づくりを心がける必要があります。 「もっと良くできそうなこと」のためにやってみたいことや、新しい試みとしてやってみたいことをあげます。 このフェーズではやってみたいことをできるだけ多く考えるブレスト形式であることを重視しています。 突拍子もないアイディアから素晴らしい改善策を思いつくかもしれませんし、現実的ではない理想論から妥当な策に落ち着かせることができるかもしれません。 問題の逆を実行する改善案があげられることがあります。「〇〇ができていなかった」という問題に対し「〇〇をやる」というようなものです。 例えば「レビュー依頼を溜めてしまった」という問題に対し「溜めないようにする」といった改善案です。大抵の場合このような案は精神論になり解決に導くことはできないでしょう。 そのためにとるべきアプローチとして「レビュー依頼を溜めてしまった」ことでどこに支障をきたしているのか、何が要因なのかを整理しましょう。 「レビュー依頼を溜めてしまった」のならば「レビューがボトルネックになりリードタイムが長くなる」ことが実質的な問題点で、要因は「レビューに時間がかかる」「レビュー依頼されていることを忘れていた」「レビュアーが1人しかいない」など様々考えられるでしょう。 要因によって改善策は大きく変わるため、ファシリテーターを中心に分析を行ってからやってみたいことを考えるようにするとスムーズに進行できます。 やってみたいことをブレストした後、このフェーズで次の振り返り会までに取り組むアクションを決めます。 たくさんの案が出ているはずなので、実際に実行できる粒度・内容に整理する必要があります。 あまり多くのアクションを決定しても実行できないため、いくつか選択するのが良いでしょう。選択の仕方は効果的なものを選んでもいいですし、投票でもいいです。 チームでは、やるべきことを決めたらタスク管理ツールで管理するようにしており、必要であれば担当者のアサインや期限までその場で決めてしまいます。 以上、チームで実際に行っている振り返り会のやり方を紹介させていただきました。 私の考えが多分に含まれているためチームメイトは違う考えを持って振り返りをしているかもしれません。 チームや状況によって適したやり方は異なるため上記の方法では上手くいかないこともあると思います。また、最初から効果的な振り返り会を行うのは難しいかもしれません。 しかしながら振り返り会自体の改善を行ったり、チームの問題を解決していくプロセスは「協調するチーム」作りに大きく寄与すると思いますので、是非継続して振り返り会を開催してみてください。 これから振り返り会をやってみようという方、やり方を模索している方の参考になれば幸いです。
はじめに
振り返り会の意義
振り返り会のやり方
ファシリテーターを誰が担当するのか
何について振り返るのか
前回の振り返り会を確認する
やったこと・良かったことを洗い出す
もっと良くできそうなことを洗い出す
共通認識を生み出す
批判する会ではない
やってみたいことを考える
よくあるNGパターン
やることを決める
おわりに
Delta LakeとLakehouseプラットフォームによるデータウェアハウス設計

こんにちは。ビッグデータ処理基盤の物理レイヤーから論理レイヤーの設計実装、データエンジニアやデータサイエンティストのタスク管理全般を担当している、Data/AI部門の何でも屋マネージャの @smdmts です。
この記事は、弊社のデータ基盤の大部分を支えるDelta LakeとLakehouseプラットフォームによるデータウェアハウス設計の紹介です。 Databricks社が主体となり開発しているDelta Lakeをご存じでしょうか?
Delta Lakeは、Apache Sparkを利用したLakehouseプラットフォームを実装可能とするオープンソースです。 Lakehouseプラットフォームの詳細は、こちらの論文に記載されています。 Lakehouseプラットフォームとは、一つのデータレイクのプラットフォームにETL処理、BI、レポート、データサイエンス、マシンラーニングを搭載することで、性能面やコスト面・仕様変更に強いなど、多方面で有利に働くとされます。
Delta Lakeとは
Delta Lakeは、以下の公式サイトのdelta.io の図にあるとおり、S3やGCSなどのストレージレイヤーに機械学習や目的別に特化したデータ構造のアーキテクチャパターンです。 Delta Lakeは主にApache SparkからのRead/Writeをサポートしていますが、制約つきでPresto/Athenaによる読込もできます。
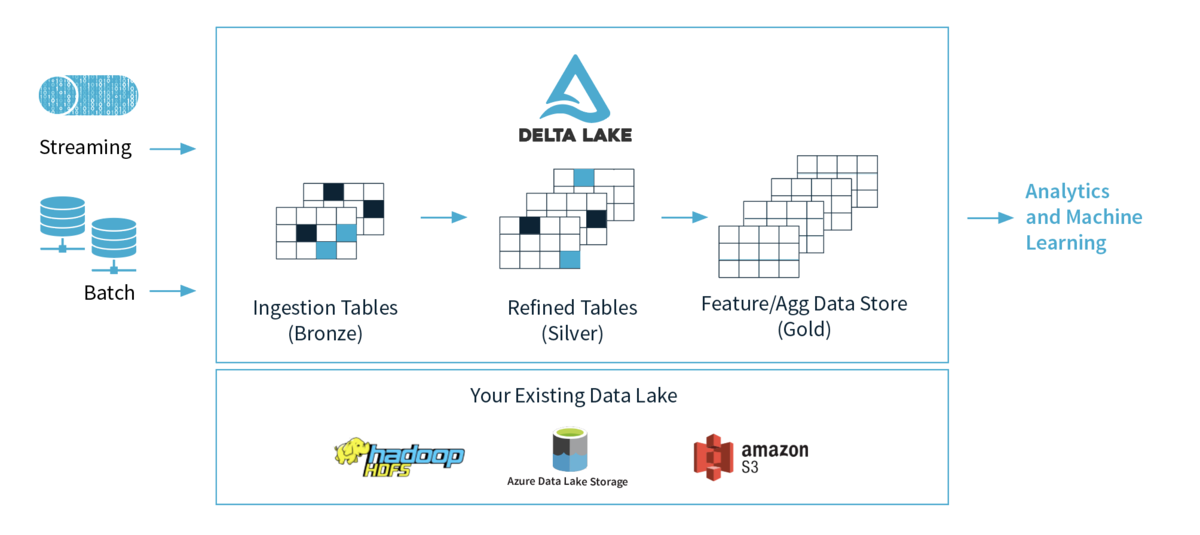
公式サイトで紹介されている以下の動画によると、Delta Lakeを利用した場合のデータ構造を、以下のように、Bronze、Silver、Goldと定義される三段階に構造を分離すると、より信頼性の高いデータレイクの構築可能にするとされます。
| ステージ | データの内容 |
|---|---|
| Bronze | Ingestion Tablesと呼ばれる、生ログを保存するステージ |
| Silver | Refined Tablesと呼ばれる、Bronzeテーブルをクレンジングした中間テーブル |
| Gold | Feature/Aggregation Data Storeと呼ばれる、目的別に特化したテーブル |
Delta LakeとLakehouseプラットフォーム
Delta Lakeに関わらずデータレイクで何らかのデータを取り扱う場合、アプリケーションのドメイン知識の考慮が必要です。 一般的なアプリケーションでは、ドメイン知識の原料となるユビギタス言語を元にデータモデルの設計がされますが、イベントソーシングを利用しない限り、ドメインモデルが出力するデータモデルの変更は可能です。 たとえば、DELISH KITCHENは、レシピ動画を視聴出来るサービスですが、「動画」と「レシピ」などのコアとなるドメインモデルがある事に対して、仕様変更などで「レシピ」に何らかの新しい付加情報となるデータモデルの変更や追加は可能です。
一方でデータ基盤におけるドメイン知識とは、KPIやKGIなどの観測したい対象を指します。 たとえば、動画におけるデータ分析のドメイン知識では「視聴数」や「視聴維持率」などがその対象となります。
データウェアハウスで管理されるイベントログは、基本的に過去に保存したデータモデルの変更は許されず、将来仕様変更が発生した場合でも、データ構造はKPIなどの観測したい事象に追随する必要があります。 そのため、以下のように各ステージ毎の領域別でドメイン知識の保有などの考慮が必要となります。
- Bronzeステージ(生ログ)
- データソースから発生するデータ構造を極力変更しないデータ領域
- 基本的に生ログで最小限の構文解析のみ行いドメイン知識を有さない
- Silverステージ(クレンジング/一次集計テーブル)
- データ構造の仕様変更などに追随するバッファーとなるデータ領域
- BronzeステージとSilverステージのデータを集計対象とする
- 生ログからイベント毎に分割するなど最小のドメイン知識を有する
- Goldステージ(最終集計テーブル)
- ビジネス上の価値が観測できる多くのドメイン知識を有するデータ領域
- SparkやPrestoなどから読み込まれる
- BIツールやMLなどから利用し、エンドユーザーの知識や知恵となり得る
このように各ステージ毎にデータが持つ役割を明確にすると、観測対象となるドメイン知識の全てがGoldステージに集約されます。 また、ドメイン知識の原料となるデータとして、SilverステージとBronzeステージにデータが保存されると明文化されます。
Bronzeステージには生ログが保存され、Silverステージにはイベント毎などで分割された最小限の粒度となるドメイン知識を有するデータが保存されます。 データが保持する情報の抽象度はBronze、Silver、Goldの順番に上がり、最終的にビジネスに何らかの役に立つドメイン知識となる情報がGoldステージで参照可能となります。
Lakehouseプラットフォームのアーキテクチャは以下の図の通り、データレイクに対して一つのエンドポイントでさまざまなデータを参照可能とする仕組みです。 データレイク内のデータをドメイン知識の保有の有無など抽象度の異なるデータをBronze、Silver、Goldと分離すると、データガバナンスに良い影響をもたらす事が期待できます。

Delta Lakeと関心の分離
ビッグデータの処理基盤は入力元となるデータ源泉は多種多様でカオスになりがちですが、Lakehouseプラットフォーム内のデータ構造をBronze、Silver、Goldの各ステージでデータを蒸留すると、関心の分離が促進されます。 関心の分離はSoC(Separation of Concerns)とも呼ばれ、オブジェクト指向設計やモジュール設計で重要とされる「凝集度」や「結合度」の観点から重要な概念です。
Delta Lake内の各データ領域を利用者別に分類すると、以下のように分離できます。
Bronzeステージ(生ログ)
- データ入力部分を処理担当するインフラエンジニア
- SaaSによる外部入力データ連係を担当するデータエンジニア
Silverステージ(クレンジング/一次集計テーブル)
- ドメインモデルを構築するデータエンジニア
- 自分が担当したアプリ成果を確認するアプリケーションエンジニア
- 探索的データ分析を行うデータサイエンティスト
- 目的となるKPIの検討を行うプロダクトマネージャ
Goldステージ(最終集計テーブル)
- 機械学習のモデル精度をチューニングするデータサイエンティストや機械学習エンジニア
- 対顧客や経営層へのレポーティングを行うデータアナリスト
- 日々のKPIを観測する事業責任者や経営者、プロダクトマネージャ
データ領域における関心の分離は、各ステージのデータ設計や最終的な可視化対象の選定に当たる洞察に良い影響を与えます。 たとえば、アプリケーション開発者が開発した機能の状況を把握するためにはSilverステージを参照すれば、機能が正常に動作しているかを把握できます。 また、達成されるべきKGIに因果関係があるKPIがはっきりしない場合は、Silverステージのデータから探索的データ分析によりKPIの検討が可能です。
データが保持する抽象度がBronze、Silver、Goldと順番に上がることの裏返すと、Gold、Silver、Bronzeの順番にデータ量が増え探索可能となる情報が増えるということです。 一度集計してしまうと集計前のデータが欠落してしまうことから、新たな洞察を得たい時にはSilverステージより前のデータを利用したい場合もあります。 Goldステージのデータは特定の目的以外のデータは保持しないことからデータの持つ柔軟性は低いです。 観測したいKPIが未知の場合は、前ステージのSilverステージやBronzeステージのデータを集計し、Goldステージに昇格させるべきか検討する必要があります。
実際のアプリケーション運営の現場ではLTVなどのKGIに因果関係があるKPIを試行錯誤して発見に至るケースも多く、しばらくの間はBIツールからはSilverステージのテーブルをスキャンする事も珍しくありません。 一方でSilverステージはGoldステージと比較してデータ量が多くなることから、計算量や処理コストの観点では不利に働きます。 そのためSilverステージのスキャンで観測したいKPI決まると、Goldステージのデータを作成するバッチを作成し、BIツールからはGoldステージのテーブルを参照するようになります。
このように、データが保持する主な情報を各ステージ毎に分離すると、データ軸でも利用者毎の関心の分離が促されます。 「システムを設計する組織は、その構造をそっくりまねた設計を生み出してしまう」とコンウェイの法則の有名な一説がありますが、データ構造とその配置を定義するだけで、利用者毎の関心が綺麗に分離するのは興味深い事例ではないでしょうか。
Delta Lakeがデータレイクにもたらす恩恵
今回はDelta Lakeの機能詳細に触れませんでしたが、Delta LakeにはUpsertを可能とするMerge文、過去に保存した時点のデータに巻き戻すTime Travelなど様々な便利な機能が実装されており、Bronze、Silver、GoldのステージのETL処理を強力にサポートします。 たとえば、Bronzeステージは生ログのためアプリケーションの実装の都合で頻繁にカラム追加などのデータ構造が変更されますが、自動的にスキーマの変更を検出してマージするスキーマオートマージ機能は非常に便利です。
私が所属するデータ/AI部門のデータ基盤では、一部の機能をDelta Lakeを利用したLakehouseプラットフォームで実装していますが、仕様変更が頻繁に発生するデータ領域でもアジリティ高く即日〜三営業日程度で観測したいKPIを追加できる状況が実現できています。
データ構造をBronze、Silver、Goldとステージを分解するだけでも、データ利用者の関心の分離を促し、データガバナンスにも数多くの恩恵をもたらすため、データウェアハウス設計の参考にして頂ければ幸いです。
ここまでお読みくださり、ありがとうございました。
データ分析する前に知っておきたい因果関係と相関関係

はじめに
エブリーでデータアナリストをしている近藤と申します。 元々サーバーエンジニアでGoを書いていましたが、昨年7月からデータアナリストとして働いています。 普段はデータガバナンスの整備やredashによるデータ提供、データによる営業支援といった業務を行っています。
因果関係と相関関係の理解
データ分析を行う意義は、データの規則性を見つけて活用し、ビジネスをドライブさせることです。 しかし、見つけた規則性の解釈を誤るとビジネスに役立たず、貴重なリソースを浪費してしまいます。 規則性を見つけて終わりではなく、見つけた規則性が一体何を意味するのかを常に考えなければいけません。
特に相関関係と因果関係の混同はよく起こりうる問題です。相関関係だけをみて因果関係があると判断すると、おそらく効果のある施策を打つことはできないでしょう。 因果関係と相関関係の違いの理解はデータ分析をする上では必須と言えます。
そこで、因果関係と相関関係を理解してデータ分析をするための考え方をまとめたスライドを作成しました。 テックブログなのにSEO最悪なのでCTOに怒られそうですが、自分が伝えたいことはスライドのほうが伝わるのでスライドにしました。 是非ご覧いただければ幸いです。
まとめ
相関関係を見つけると因果関係がどのように存在しているのかを考え、仮説を立ててリサーチデザインを決め、データを収集・分析し、因果関係に迫っていく必要があります。 相関関係と因果関係を混同しないように気をつけましょう!!
運用していたAPI Serverが気づいたら異常終了するようになっていた話

はじめに
今回は運用していたAPI Serverが気づいたら異常終了するようになっており、原因の特定と対策をした話をしようと思います。
発生していた障害
今回発生していた障害の詳細は以下になります。
- ECS上で運用していたAPI Serverが異常終了するようになっていた
- タスクの終了ステータスを監視するスクリプトを動かし始めたタイミングで発覚
ExitCode 2でタスクが終了している
- 異常終了は発生する日としない日がある
- 同一の日に複数回発生はしていない
- 異常終了が発生するのは12時から13時の間
- タスク数は2で起動していたが、2つのタスクが同日に異常終了することはなかった
- 異常終了する直前のメトリクスに通常時と異なる箇所は見られなかった
外形監視はしていたのですが、タスクの終了ステータスは監視していなかったため発見が遅れました。 また、発見が遅れたためどの変更が原因でいつから異常終了するようになっていたのかがわからない状態でした。
原因調査
調査1 : コードの更新
まず最初にExitCode 2でタスクが終了していることからpanicが発生しているのではないかと考えました。
今回異常終了していたAPI Serverは、同一のdocker imageを使用し、環境変数によって内部向け・外部向けを変更する構成になっており、外部向けの方でのみ異常終了は発生していました。
外部向けのAPI Serverに関しては、自動デプロイの対象になっておらず直近でデプロイも行われていなかったため、内部向けAPI Serverと差分が発生している状態でした。
差分が発生し、外部向けAPI Serverでのみ異常終了が発生していたため、差分に原因があるのではないかと考え差分をなくすためにデプロイを実施しました。
しかし、差分がなくなった状態でも状況に変化はなく、外部向けAPI Serverでのみ異常終了は発生し続けました。
調査2 : アクセスに起因したものではないか
調査1にて内部向けとの差分をなくしても状況に変化がなかったで、次は特定のリクエストによって発生しているのではないかと考えました。
API Serverではアクセスログを出力していたのですが、このアクセスログはレスポンスを返すタイミングで出力していたため、処理の途中で異常終了してしまった場合にはログは出力されていません。
そこで、調査のために処理の途中でも適宜ログを出力するようにして、処理途中で異常終了した場合にもどんなリクエストが来ていたかわかるよう変更を加えました。
しかし、異常終了が発生した後にログを確認したところ、該当の時間に処理を行っているログは出力されていませんでした。
調査3 : システム系を疑う
調査2によって、リクエストによって発生しているわけではないことがわかったので、API Serverのコード以外の要素で異常終了する理由がないかと考え調査を続けていました。
異常終了が発生するのは12時から13時の間だけのため、この時間帯に何かしらの処理が動いて、それが原因なのではないかと考えました。
API Serverのコンテナが動いているインスタンスにて該当の時間帯に動いている処理を確認したところ、ログローテートの処理がありました。
ログローテートの設定は下記のようになっていました。
{
missingok
notifempty
compress
delaycompress
daily
rotate 7
postrotate
docker container kill -s HUP `docker ps | grep <image-name> | awk '{print $1}'` 2> /dev/null || true
endscript
sharedscripts
}
ログローテート後に、ログの出力先ファイルを変更するために条件に合致するコンテナに対してSIGHUPシグナルを送っていました。
ここではシグナルを送る先としてgrep <image-name>で対象のコンテナをしぼっています。
調査1にて記載していますが、異常終了していたAPI Serverは同一のdocker imageを使用し、環境変数で内部向け・外部向けを変更するようになっています。
そのため、内部向けと外部向けのAPI Serverが同一のインスタンスに存在した場合、実際にはログローテートをしていない方のAPI Serverにもシグナルが送られるようになっていました。
どちらのAPI ServerでもSIGHUPをハンドリングするようになっている場合には問題はないのですが、外向けのAPI ServerではSIGHUPのハンドリングをするようになっていませんでした。
確認のため、検証環境にて外向けのAPI Serverに対してSIGHUPシグナルを送ってみると異常終了することが確認できました。
行った対応
原因の特定ができたので、対応策を考えます。
今回候補に上がった対応策は下記の3つになります。
- SIGHUPを送る先の抽出条件を修正する
- 内向けと外向けのimage名を分離する
- シグナルをハンドリングする
本来でしたら3つすべて実施したほうがいいのですが、 まずは応急処置として実装工数が一番少なく済むと判断した、シグナルハンドリングの修正を行うことにしました。
DELISH KITCHENではGoでAPI Serverの実装を行っており、Goではシグナルハンドリングos/signageパッケージに定義されているIgnoreメソッドを使えばできます。
https://golang.org/pkg/os/signal/#Ignore
実際に追加した処理は下記になります。
signal.Ignore(syscall.SIGHUP)
上記の対応を実施したあと、検証環境にて外向けのAPI ServerにSIGHUPを送ったところ問題なく稼働し続けていることが確認できました。
振り返り
今回はExitCode 2でAPI Serverが終了していたという情報と障害が発生していた時間から原因を想像して、対処をすることができました。
対応後にチーム内にて簡単に振り返りを実施してみたところ、トレースを実施することでより詳しい情報が取得でき、原因の特定がスムーズにできたのではないかという意見がありました。
トレースする対象としてはシステムコール・パケット・ブロックIO等が考えられます。
今回の障害の場合、システムコールをトレースしてみればSIGHUPが送られて来ていたことがわかったはずです。
実際にシステムコールをトレースしてみた例を下記に示します。
今回障害が発生していたAPI ServerはGoで記述したものをdocker上で動かしており、dockerを動かしているホスト及びAPI Serverが起動しているコンテナ内にstraceがインストールされていないため、PID名前空間を共有したコンテナを起動し、起動したコンテナ内でstraceを実行しています。
echo -e 'FROM alpine\nRUN apk add --no-cache strace' \ | docker build -t debug -f - . \ && docker run -it --rm --pid container:<containe_id> --cap-add sys_ptrace debug strace -fp 1
docekrで動かしているコンテナに対して、別のコンテナからstraceを動かす方法については、下記のサイトを参考にさせていただきました。
straceをした状態でSIGHUPを受信するした時のログは下記になります。
[pid 6] nanosleep({tv_sec=0, tv_nsec=20000}, <unfinished ...>
[pid 13] <... futex resumed>) = 0
[pid 13] futex(0xc000211d48, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
[pid 6] <... nanosleep resumed>NULL) = 0
[pid 6] futex(0x17c4e78, FUTEX_WAIT_PRIVATE, 0, {tv_sec=59, tv_nsec=137259289} <unfinished ...>
[pid 10] <... epoll_pwait resumed>[], 128, 1, NULL, 0) = 0
[pid 10] epoll_pwait(3, [], 128, 0, NULL, 2) = 0
[pid 10] epoll_pwait(3, <unfinished ...>
[pid 1] <... futex resumed>) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
[pid 1] --- SIGHUP {si_signo=SIGHUP, si_code=SI_USER, si_pid=0, si_uid=0} ---
[pid 1] futex(0x17efbc0, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
[pid 10] <... epoll_pwait resumed>[{EPOLLIN, {u32=4118929128, u64=140509679050472}}], 128, 59136, NULL, 0) = 1
[pid 10] futex(0x17c4e78, FUTEX_WAKE_PRIVATE, 1) = 1
[pid 6] <... futex resumed>) = 0
障害が起こっているAPI Serverに対してstraceを実行し上記のようなログがでていることを確認できていれば、どこからかSIGHUPが送られてきていることがわかり、調査をスムーズに進めることができたと思いました。
しかし、トレースを実施すると何かしらオーバヘッド等が発生するため、なるべくなら検証環境などで不具合を再現し、その環境でトレースを行うことが望ましいです。
ですが、今回のように再現が困難な場合にはオーバーヘッドが発生することを考慮にいれ、本番環境でトレースを行うことも1つの方法としてあったと思います。
さいごに
今回は実際に起こった障害の事例を元にどういったことを考え調べていったのかについて話しました。
障害の調査をする時には、想像力を働かせて色々な原因を考えて一つ一つ確認していくことになると思います。
その時今回のように気づくのが遅れてしまうと、考えうる原因が増え対応の時間が長引くだけでなく難易度もあがってしまいます。
こうならないためにも、適切な監視を設定することが大事だと改めて感じることができました。
今回のような失敗談を記事にすることで、みなさんの障害調査の時の手助けや監視設定を見直すきっかけになれば幸いです。
Jetpack Compose のbeta版を触ってみた

はじめに
日本時間の2021年2月25日に Jetpack Compose のbeta版がリリースされました。APIも固まってきたようですので触ってみた範囲のうち、導入的なところをコードで示しつつ、感想を述べていきます。
使用環境
使用した環境は以下の通りです。他にもandroidx.activityなどにcomposeがありますが、いずれも2021年3月15日時点で最新のバージョンを使用しました。
バージョンはJetpackのLibraries(*1)から調べることができます。
- Android Studio Arctic Fox | 2020.3.1 Canary 9
- androidx.compose 1.0.0-beta02
最初につくるもの
トップレベルの関数に @Composable を指定することで、その関数内にてComposeを使用したレイアウトを組めます。合わせて @Preview を指定すればAndroid Studio上でプレビューもできます。
このプレビューは同時に複数表示可能なので、プレビュー用の関数を複数作成すればダークテーマ対応有り/無しの表示を同時に確認できます。
@Composable
fun MyScreen() {
// ここでComposeを使用して表示を組む
}
@Preview
@Composable
fun PreviewMyScreen() {
// MyScreenで組んだ表示がAndroid Studio上にプレビューされる
MyScreen()
}
レイアウトたち
Box、Column、Rowがそれぞれ従来のFrameLayoutやinearLayoutに相当しています。
Box {
// 重なる
Text("hoge")
Text("piyo")
}
Column {
// 縦に並ぶ
Text("hoge")
Text("piyo")
}
Row {
// 横に並ぶ
Text("hoge")
Text("piyo")
}
他に、gradleファイルに指定を追加することでCompose版のConstraintLayoutも使えますが、公式Document中のConstraintLayoutの補足(*2)を読むと無理して使わなくても良さそうです。
// テキスト2つを縦に並べる
ConstraintLayout {
val (text1, text2) = createRefs()
Text(
"hoge",
modifier = Modifier.constrainAs(text1) {
linkTo(
parent.start, parent.top, parent.end, text2.top,
0.dp, 0.dp, 0.dp, 8.dp
)
}
)
Text(
"piyo",
modifier = Modifier.constrainAs(text2) {
linkTo(
parent.start, text1.bottom, parent.end, parent.bottom,
0.dp, 0.dp, 0.dp, 0.dp
)
}
)
}
表示のパーツたち
Text、Button、Image、Cardなど多くの表示が揃っています。Spacerなるものもあり、わかりやすくmarginを仕込めます。
ただ、RecyclerView(ListView)相当がLazyColumn(or LazyRow)という名称であったりと、一部は従来の名前から大きく変わっている点に注意が必要です。
val items = (0 until 100).map { "item $it" }
LazyColumn(
// 項目の間隔を空ける
verticalArrangement = Arrangement.spacedBy(8.dp)
) {
item {
// リストの一番上に横スクロールのリストを入れる
LazyRow(
horizontalArrangement = Arrangement.spacedBy(8.dp)
) {
items(items) { Text(it) }
}
}
items(items) {
// 縦スクロールのリストの項目としてテキストとボタンを横に並べる
Row {
Text(it)
Spacer(modifier = Modifier.width(8.dp))
Button(onClick = {
// ボタンクリック時の処理
}) {
Text("button")
}
}
}
}
ものが多すぎるので使いたいものを公式Reference(*3)から頑張って探す必要があります。androidx.composeパッケージ関連を漁れば色々と見つかります。
表示の設定を変更する
これまでレイアウトのxmlで指定していたlayout_widthやpaddingなどは Modifier というobjectを通して設定します。
Modifierにサイズやpaddingを設定する拡張関数があり、ものによってはColumnなどのscope限定で使える拡張関数が存在していることもあります。
Box(
// 縦横とも画面一杯に広げてpaddingを設ける
modifier = Modifier
.fillMaxSize()
.padding(16.dp)
) {
Text(
"hoge",
// 背景を赤色かつ角に丸みを与え、中央に配置する
modifier = Modifier
.background(Color.Red, shape = RoundedCornerShape(8.dp))
.align(Alignment.Center)
)
}
表示の操作として行えることはModifierの関数だけなのでわかりやすいです。
ガワを作る
Scaffold() でMaterial Designに則った画面を簡単に構築できます。各種AppBarやFABを設定できる口があるので、従って作るだけでそれらしい画面になります。
Scaffold(
// 他にもbottomBarやfloatingActionButtonなどを設定できる口がある
topBar = {
TopAppBar(
title = { Text("title") },
actions = {
IconButton(onClick = {
// メニュークリック時の処理
}) {
Icon(
imageVector = Icons.Default.ImageSearch,
contentDescription = "search"
)
}
}
)
},
content = {
// ここで画面の表示を作る
MyContentScreen()
}
)
その他
viewModelを viewModel() で取得できたり、Navigationによる表示切り替えも行えるため、やりたいことは一通り行えそうであることが感じとれます。
また、これまでに作成した既存のViewは AndroidView なるものを使用することでComposeの世界に引き込んだりもできます。
他にCompose独自に覚えることとして、remember系の関数で値を保持したり、表示更新の契機としてStateを操作したりと従来にはなかった考え方を覚えて行く必要があります。
このあたりはReactのComponentで表示を作るときに近いものを感じました。
ハマったところ
Android StudioがCanaryであったり、Composeがbetaであるためか、いくつかハマったところがありました。
- viewModel()を使うとプレビューが表示されない
- viewModel()を使わずにViewModelの実体を渡すか、あるいはViewModelから取得した値だけをComposableな関数へ渡す
- プレビューを使わず、エミュレータや実機で確認するだけなら問題なし
- 自動importがよきに行われないものがあるため毎回手動でimportを書くことになるものがあった
- viewModel()を使うための
import androidx.lifecycle.viewmodel.compose.viewModel var value by remember { mutableStateOf("") }などと by を使ってStateのvalueへのシンタックスシュガーを利用する場合のimport androidx.compose.runtime.getValue / setValue- stackoverflowの回答(*4)に助けられました
- (3/29追記)
by xxx.observeAsStateを使用した場合のgetValue(※7)やby rememberを使用した場合のsetValueのimportなど、一部に対応されたようです
- viewModel()を使うための
- BottomSheetやSnackbarの使い方のベストプラクティスがわからない
- Textなどと同じように作ることでとりあえず表示は行えるが、BottomSheetScaffoldやSnackbarHostなるものがあるため、よりよい使い方があると思われる
さいごに
今回の記事は公式Document(*5)を一通り読んでその中のおおよそを触ったものの一部です。Composeの情報は多いため覚えきることも紹介しきることも難しいですが、触ってみた範囲ではxmlで組むより簡単に表示を構築できる印象がありました。
対応されたAndroid Strudioとともにstable版になる日が楽しみです。
Jetpack Composeを使ったチャレンジとして Android Dev Challenge (*6) なるものも開催されているので、挑んでみるのも良いと思います。
参照
*1
JetpackのLibraries
https://developer.android.com/jetpack/androidx/explorer
*2
公式Document中のConstraintLayoutの補足
https://developer.android.com/jetpack/compose/layout#contraintlayout のNote部分
*3
公式Reference
https://developer.android.com/reference/kotlin/androidx/compose/material/package-summary
*4
stackoverflowの回答
https://stackoverflow.com/questions/64951605/var-value-by-remember-mutablestateofdefault-produce-error-why
*5
公式Document
https://developer.android.com/jetpack/compose
*6
Android Dev Challenge
こちらは最終チャレンジのWeek 4
https://android-developers.googleblog.com/2021/03/android-dev-challenge-4.html
※7
Android Studio Arctic Fox Canary 12のFixes
https://androidstudio.googleblog.com/2021/03/android-studio-arctic-fox-canary-12.html