はじめに
現在、MAMADAYSのWebチームでは昨年発表されたCore Web Vitalsを中心としたパフォーマンス改善に注力しています。 今回はパフォーマンス改善でも重要な計測部分について、MAMADAYSではどのようにCore Web Vitalsのデータを定点観測する環境を整えているのかをご紹介したいと思います。
Core Web Vitalsとは
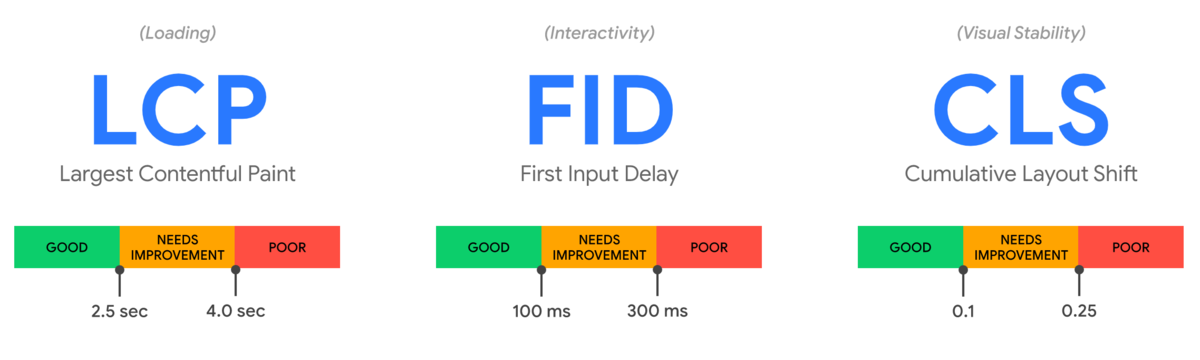
Core Web Vitalsとは、全てのサイトにおいて共通してユーザー体験をよくするために重要な、Google社が提唱するパフォーマンス指標のことです。本記事ではCore Web Vitalsの解説を目的としないため、詳細な説明は割愛しますが、Core Web VitalsにはLCP・FID・CLSという3つの具体的なパフォーマンス指標があり、将来的にはGoogle検索のランキング要因にも組み込まれると言われています。
LabデータとFieldデータ
パフォーマンス改善をする際に重要になってくるのがパフォーマンスの定点観測ですが、計測データは大きく分けて以下の2種類があります。それぞれにメリットとデメリットがあるので、両方をうまく使い分けながらサイトのパフォーマンス観測を行っていくことが大切になります。
Labデータ: Googleが開発するLighthouseなど特定の環境下で収集されたパフォーマンスデータのことです。特定の環境下で行うことにより再現可能なデータを提供でき、パフォーマンス観測もしやすいのがメリットですが、実際の利用者との実行環境の差異がある可能性があります。
Fieldデータ: 利用者の実際の環境下で収集されたパフォーマンスデータのことです。実際の利用環境のパフォーマンスが収集できることがメリットですが、収集するデータにはばらつきがあるためFieldデータに比べると観測がしにくいです。
参考: https://web.dev/how-to-measure-speed/#lab-data-vs-field-data
計測環境の検討
計測環境の検討にあたっては有料の計測サービスの SpeedCurve やNext.jsでVercelを使っていればNext.js製の Analytics も候補に出ると思います。ただ、MAMADAYSではBIツールとしてMetabase、分析データの保存先としてBigQueryを使っているのでうまく既存のアセットを生かした形でコストをかけずに実現する方法を模索していました。
Labデータの計測
Labデータの計測にあたっては、PageSpeed Insights API を利用してLabデータの収集を行っています。PageSpeed Insights はブラウザでサイトのパフォーマンスを確認できるツールとして便利ですが、APIも用意されており、簡単に同じデータを取得することができます。
// PageSpeed Insights APIのレスポンスの一部抜粋 { "lighthouseResult": { "audits": { "largest-contentful-paint": { "id": "largest-contentful-paint", "title": "Largest Contentful Paint", "description": "Largest Contentful Paint marks the time at which the largest text or image is painted. [Learn more](https://web.dev/lighthouse-largest-contentful-paint/)", "score": 0.92, "scoreDisplayMode": "numeric", "displayValue": "1.1 s", "numericValue": 1110 }, "total-blocking-time": { "id": "total-blocking-time", "title": "Total Blocking Time", "description": "Sum of all time periods between FCP and Time to Interactive, when task length exceeded 50ms, expressed in milliseconds. [Learn more](https://web.dev/lighthouse-total-blocking-time/).", "score": 0.97, "scoreDisplayMode": "numeric", "displayValue": "110 ms", "numericValue": 105 }, "cumulative-layout-shift": { "id": "cumulative-layout-shift", "title": "Cumulative Layout Shift", "description": "Cumulative Layout Shift measures the movement of visible elements within the viewport. [Learn more](https://web.dev/cls/).", "score": 1, "scoreDisplayMode": "numeric", "displayValue": "0", "details": { "items": [ { "finalLayoutShiftTraceEventFound": true } ], "type": "debugdata" }, "numericValue": 0.00018970055161544525 } } } }
注意点として公式でも記載されていますが、Lighthouseのように特定の環境下でユーザーなしにパフォーマンス計測をする場合にFIDは計測できません。したがって、LabデータでFIDの計測を行いたい場合は代替手段としてFIDと相関のあるTotal Blocking Time (TBT)を見るようにします。
MAMADAYSではこちらのAPIを利用して、複数ページを2時間おきにデータを収集し、BigQueryに転送しています。1回のみ特定のページを毎日計測する方法だとパフォーマンスデータとしてはあまりにも信憑性に欠けてしまうので複数のページで頻繁にデータを取得するようにしています。
Fieldデータの計測
パフォーマンス改善に取り組み始めた当初、前述したLabデータの観測のみを行っていました。ただ、Labデータのみだと実際の環境下でのパフォーマンスデータが観測できないことが課題としてあり、Fieldデータの計測方法を検討しました。
Next.jsとGoogle Analyticsを利用した計測基盤の構築
まずはWeb側のデータ収集方法ですが、MAMADAYSのWebではNext.jsを採用しており、Next.jsはバージョン9.4から標準機能としてCore Web Vitalsの計測を行えるようになったのでその機能を使って公式のガイドを参考に実装しました。また、収集したパフォーマンスログはすでに連携済みだったGoogle Analyticsのイベントとして保存することで継続してパフォーマンス推移を観測できる環境を作りました。
// pages/_app.js // googleAnalyticsのイベントとしてパフォーマンスデータを保存 function performanceMetricsEvent({ id, name, label, value }) { const eventValue = Math.round(name === 'CLS' ? value * 1000 : value); window.gtag('event', name, { event_category: 'パフォーマンス', value: eventValue, event_label: id, non_interaction: true, }) } // Next.jsの標準機能 reportWebVitalsを定義する export function reportWebVitals(metrics) { performanceMetricsEvent(metrics); }
参考: https://nextjs.org/docs/advanced-features/measuring-performance
直面した問題点
しかし数週間こちらの計測方法で検証していたところ、送っているイベントのラベルがページロードごとのユニークな値にしているため、ラベル数が上限に達してしまい他のイベントに影響を及ぼしてしまう問題がGoogle Analyticsのアラートから発覚しました。

その時点で対応するのであれば、全体の利用者の何割かに絞って計測をすることで上記の問題は解決できそうでしたが、今後利用者の増加を考慮して計測基盤の見直しを行いました。
計測方法の改善
計測基盤を見直すにあたって、MAMADAYSでは分析にBigQueryを使用しているためBigQueryへの転送を考えました。
また大量のパフォーマンスログのデータ転送をアプリケーションとは切り離して行うために、サーバー側はパフォーマンスのログ出力のみを行い、fluentdでBigQueryへのストリーミング挿入し、dailyでシャーディングテーブルを作るように変更しました。fluentdでは fluent-plugin-bigquery というgemを使うことによって簡単にfluentdでのBigQueryへのストリーミング挿入が実現できます。
ログの出力形式
{"id":"1618905791407-4433185739018","label":"web-vital","level":"INFO","name":"LCP","path":"/articles/999","time":"2021-04-20T08:03:11.870117321Z","type":"WEB_PERFORMANCE","value":"1500"}
fluentdでのinsert部分の設定
<label @web-performance-log>
<filter **>
@type grep
<regexp>
key $.parsed_log.type
pattern ^WEB_PERFORMANCE$
</regexp>
</filter>
<filter>
@type record_transformer
renew_record
enable_ruby
<record>
id ${record["parsed_log"]["id"]}
time ${record["parsed_log"]["time"]}
label ${record["parsed_log"]["label"]}
name ${record["parsed_log"]["name"]}
path ${record["parsed_log"]["path"]}
value ${record["parsed_log"]["value"]}
</record>
</filter>
<match **>
@type bigquery_insert
auth_method json_key
json_key /etc/secrets/google-credentials/fluentd-to-bq.json
project "#{ENV['BQ_PROJECT']}"
dataset "#{ENV['BQ_DATASET']}"
table web_performance_%Y%m%d
auto_create_table true
<buffer time>
@type file
flush_interval 30s
path /var/log/fluentd-buffers/bq-event.buffer
timekey 1d
</buffer>
schema [
{"name": "id", "type": "STRING"},
{"name": "time", "type": "STRING"},
{"name": "label", "type": "STRING"},
{"name": "name", "type": "STRING"},
{"name": "path", "type": "STRING"},
{"name": "value", "type": "STRING"}
]
</match>
</label>
この改善により、BigQueryのストリーミング挿入でコストが多少掛かってしまいましたが、他の分析への影響を与えずにFieldデータの継続的な観測を実現できました。また、Google Analyticsへのデータ保存時にはMetabaseというBIツールで計測結果が見れるようにBigQueryへのデータの加工と転送を自前で別途行う必要がありましたが、直接BigQueryに転送できたことでその手間も省ける結果となりました。
まとめ
今回はWebパフォーマンスの計測でCore Web Vitalsをどう計測しているのかについて話しました。パフォーマンス改善において、憶測ではなく現状のボトルネックなどを正しく理解して改善する上でもパフォーマンスの継続的な計測は重要になってくると思います。計測方法やGoogle Analyticsでの問題に関して同じような課題に直面されている方の参考になれば幸いです。
MAMADAYSのWEBチームではパフォーマンス改善に注力しており、改善結果も出ているので実施した改善内容についても今後お話していきたいと思います。