はじめまして。DELISH KITCHEN開発部の桝村です。DELISH KITCHENのWEBフロントやAPIサーバーの開発等に携わっています。 突然ですが、みなさんは本日もPull Requestを使ってレビュー依頼しましたか?もしくは、誰かからレビュー依頼を受けましたか? チーム開発におけるコードレビューというものは、プロダクトの品質向上やチーム内での知見共有に貢献しているものの、チームがコードレビューに対して相当な時間や労力をかけているのも事実かと思います。 加えて、レビュー対象の実体でもあるPull Requestの品質は、作り手である実装者に大きく依存しており、コミットから説明文まで自由に作れる反面、レビューしやすいPull Requestを作成しないと、より一層自身やチームに大きな負担がかかる可能性があります。 そこで、今回はレビュワー目線に焦点を当てて、レビューしやすいPull Requestをつくるために自分が心がけていることを紹介させて頂きます。
簡単かつすぐに改善できるポイントをまとめたので、ぜひ参考にして頂けると幸いです。 WhyとWhatが不十分な場合、レビュワーはそれらをコードから想像せざるを得なかったり、実装者へ直接確認する手間が生じて、大きな負担になる可能性があります。また、WhyとWhatが区別されず混合している場合も、実装内容の難易度や複雑性により、実装者とレビュワーの認識に齟齬が生じ得ます。 WhyとWhatをそれぞれきちんと記載することで、レビュワーは、本来のレビュー内容である、仕様通りかどうか、改善の余地はあるか等の確認作業に集中でき、よりコードレビューをしやすくなります。 また、Pul Request自体が履歴的な情報としてリポジトリ内に残り続ける点で、実装に関するドキュメントとしての役割も担います。よって、WhyとWhatをきちんと記載することは、長期的に見てもチームにとって非常に貴重な財産になります。 加えて、以下のような情報があると、実装内容の正当性を容易に検証できたり、アウトプットがひと目で分かる点で、よりレビュワーが実装概要を理解しやすくなります。 説明文が各項目について整理されず文章のみで構成されている場合、読み手であるレビュワーは実装内容の要点を理解するのに時間がかかり、大きな負担になる可能性があります。 説明文では以下のようにマークダウン記法を使用できるので、見出しや箇条書き、コード埋め込み等のスタイルを利用することで、レビュワーは、実装概要をひと目で理解でき、よりコードレビューをしやすくなります。 参考: Basic writing and formatting syntax また、Pull Request TemplatesというPull Requestの説明文に対して開発者に含めて欲しい情報をカスタマイズし、標準化できる機能があり、これを使用すると、レビュワーにとって見やすい説明文になるだけでなく、実装者にとっても構造化する手間がなくなったり、何を記載すれば良いか明確になる点で導入するメリットが非常に大きいです。 参考: Creating a pull request template for your repository コミットの粒度がバラバラであったり複数の変更が入った曖昧なコミットである場合、レビュワーはどんな変更をしているのか把握しづらく、大きな負担がかかる可能性があります。 機能実装やバグ修正、リファクタ等、まずは単一の課題や目的を単位としてコミットすることで、レビュワーは、変更概要や意図を正確かつ容易に理解でき、よりコードレビューをしやすくなります。 加えて、以下のようにコミットメッセージにPrefix (テキストの先頭につける文字) をつけると、どのカテゴリの修正をしたのか、プロダクションコードに影響があるコードかがひと目でわかるようになり、よりコードレビューをしやすくなると思います。 Pull Requestが大きすぎる場合、レビュワーは単純に時間や労力がかかるだけでなく、既存のコードへの影響範囲が大きくなるゆえに問題点の発見も困難になり、大きな負担がかかる可能性があります。 適切な大きさに分割すると、レビュワーは、影響範囲もより限定的になるため、レビューが楽になったり、その精度も上がり、よりコードレビューをしやすくなります。Pull Requestの粒度としては、自分の場合、スコープ、つまり機能セットを絞り込み、1つのPull Requestで解決するタスクを減らすことを意識しています。 特定のコードについて説明が必要な場合があると思います。例えば、実装したものの自信がなく注意深くレビューをお願いしたい時やコードのみで実装の意図が伝わりにくい時、知見を共有したい時などです。そういった場合、インラインコメントを記載すると、レビュワーは、自ずとコメント周りのコードを注意深く確認したり、早期に問題提起・解決策の話し合いができ、よりコードレビューをしやすくなります。 参考: Adding line comments to a pull request また、実装者が躊躇せず積極的に発信することが、有意義な議論やコミュニケーションが生み、結果的にチームの成長や開発効率の向上に繋がると思います。 テストがない場合、レビュワーは実装内容の仕様をソースコードのみから読み取る必要があり、大きな負担がかかる可能性があります。 テストがきちんと書かれていると、ただソフトウェアの品質を向上させるだけでなく、ソースコードの仕様(期待する処理結果)に関するドキュメントとしての役割も担うため、レビュワーは、その仕様や振る舞いを容易に読み取ることができ、よりコードレビューをしやすくなります。 コードレビューにて実装者のレスポンスが遅い場合、レビュワーは返信が無くて気になったり、コメント内容を忘れる等により、レビューの効率を下げ、大きな負担がかかる可能性があります。 そこで、実装者が簡単かつ最初にできることは、レビュワーによるコメントにいち早く気づくことです。Slackとの連携機能を使用することで、レビュワーによるコメントやレビューを任意のチャンネルへ通知させることができ、少しでも早く返信できるようになります。 今回は、チーム開発において、レビュワーに優しいPull Requestをつくるポイントをまとめてみました。
冒頭でお話ししたとおり、チーム開発ではコードレビューは結構な時間と労力がかかります。裏を返せば、メンバー一人一人がレビューしやすいPull Requestの作成を心がけることで、チームの開発速度が大きく改善する可能性があると思います。 今回紹介させて頂いたポイントを実際の開発現場で試して頂けると嬉しいです。 ここまでお読みいただき、ありがとうございました。
はじめに
今すぐできるレビュワーに優しいPull Requestをつくる7つのポイント
1. WhyとWhatをそれぞれ記載する
2. 説明文は構造化する
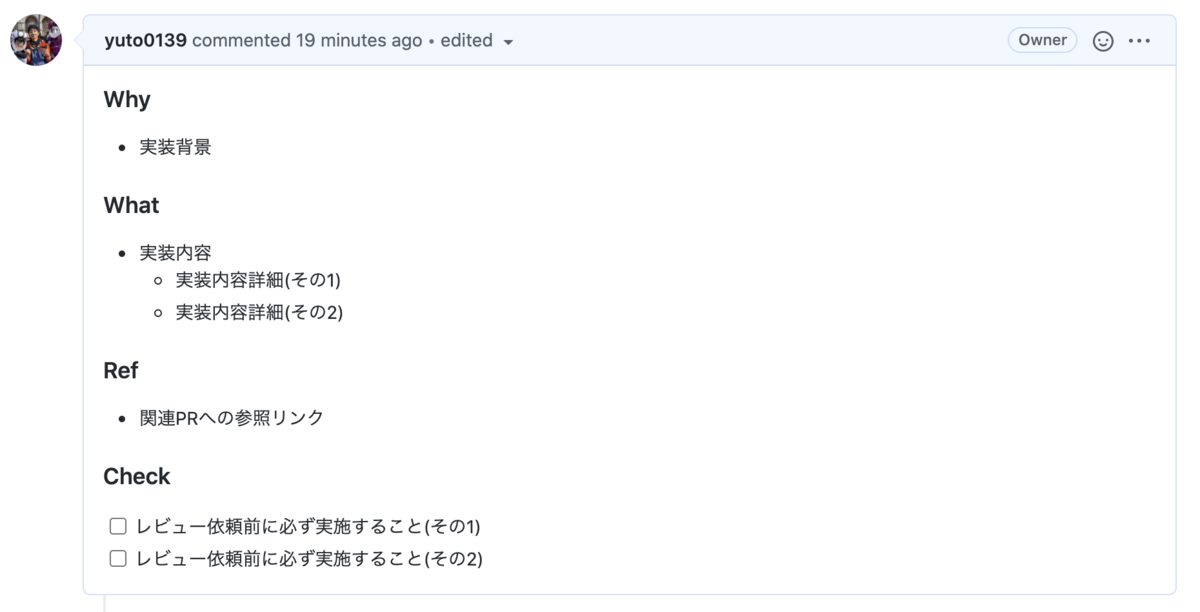
### Why
- 実装背景
### What
- 実装内容
- 実装内容詳細(その1)
- 実装内容詳細(その2)
### Ref
- 関連PRへの参照リンク
### Check
- [ ] レビュー依頼前に必ず実施すること(その1)
- [ ] レビュー依頼前に必ず実施すること(その2)
3. コミットは課題を解決した単位で行う
4. Pull Requestは適切な大きさに分割する
5. 個別説明が必要な箇所は積極的にコメントをつける
6. テストを書く
7. Pull Requestでのコメントを Slack に通知させる
さいごに
In-App Review APIの導入について

はじめに
はじめまして。普段はMAMADAYSでiOSエンジニアをしている國吉です。
iOSエンジニアではありますが、アプリのストアレビュー改善企画も兼務で行っているため、時にはAndroidの実装を担当することもあります。
そこで今回は2020年8月頃にGoogleから提供されたIn-App Review APIをMAMADAYSのAndroidアプリに導入し、実際レビュー評価にどのような変化を及ぼしたのかをお話していきます。
In-App Review APIとは
アプリから離脱することなく、アプリのレビューを行うことができるAPIです。
APIレベルは21以上(Android5.0)がサポートされています。
これまでの課題
ストアのレビュー評価はアプリのインストールに大きく関わってきます。
ただ、MAMADAYSではこれまで”独自ポップアップを実装し、Google Play Storeに遷移させレビューを行ってもらう”というフローだったため、レビューまで手間がかかってしまいユーザーの離脱が多かったです。
そのためレビュー評価4.0から全く上がらないのが課題でした。
導入してみた結果
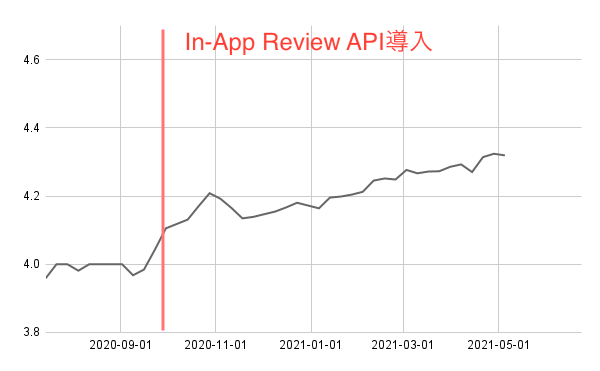
In-App Review APIを導入し約8ヶ月程経過しましたが、徐々にレビュー評価の件数が上がってきています。
もちろんその8ヶ月間でアプリ自体に様々な機能を追加しており、利便性が向上していることも影響してると思いますが、アプリ内でレビュー完結できることがレビューという行為のハードルを下げています。
導入前と比較すると0.3程度上がり、レビュー評価は4.3~4.4程度にまで成長しました。
レビュー要求を表示するタイミング
レビュー要求は表示するタイミングが重要です。
MAMADAYSでは、ユーザーが何かを達成した時(例えば記事をお気に入りした。育児記録を登録した。など)に下記の公式リファレンスに記載されている事項を考慮しレビュー要求を表示しています。
- ユーザーがアプリやゲームを十分体験してから、アプリ内レビューのフローを開始してください
- ユーザーに過度にレビューを求めないでください
- 評価ボタンや評価カードを表示する前または表示中に質問をしないでください(「アプリを気に入りましたか?」といったユーザーの意見に関する質問など)
実装方法
In-App Review APIはPlay Core SDKの一部なので、gradleファイルにCoreライブラリ1.8.0以上を追加します。
dependencies {
implementation 'com.google.android.play:core:1.8.2'
}
様々な画面でレビュー要求を表示したいので、In-App Review APIをリクエストして表示する処理を共通関数として作成していきます。
ただし、公式リファレンスにも注意書きされていますが勝手に表示されるViewのデザインやサイズ、背景色等のカスタマイズは一切行わないようにしてください。
import com.google.android.play.core.review.ReviewManagerFactory ... fun showInAppReview(activity: Activity) { val manager = ReviewManagerFactory.create(activity) val request = manager.requestReviewFlow() request.addOnCompleteListener { if (it.isSuccessful) { manager.launchReviewFlow(activity, it.result) } else { // error } } }

最後に
Googleから提供されているAPIのため実装が比較的簡単であり、レビュー評価の向上にも繋がるためまだ導入されていない方は是非導入してはいかがでしょうか。
ただ、In-App Review APIをリクエストした際、必ずレビュー要求が表示されるわけではないので、絶対にレビュー要求を表示したい画面は”独自のポップアップ”を表示するように切り分けて使っていくのもいいかもしれません。
ここまで読んでいただき、ありがとうございました。
UITableViewDiffableDataSourceを使ってクラッシュ率を改善しました

はじめに
iOSでTableviewやCollectionViewを扱っていると、UIとデータとの間で不整合が起きた際に NSInternalInconsistencyException というエラーを吐いてアプリが落ちるというのはよくある話だと思います。
TableViewに関してはiOS13から UITableViewDiffableDataSource が追加され、Apple曰くこの問題を回避できるらしいので、DELISH KITCHENのiOSアプリで採用してみました。
導入方法
Hashable化
セクションやアイテムに対応するオブジェクトがHashableに適合している必要があります。 今回は対象となるオブジェクトがユニークなIDを既に持っていたので簡単でした。
/// TableViewの各セルに対応するオブジェクト struct Item: Hashable { let id: Int ... /// 追加1 static func == (lhs: MessageDetailRowItem, rhs: MessageDetailRowItem) -> Bool { return lhs.id == rhs.message.id } /// 追加2 func hash(into hasher: inout Hasher) { hasher.combine(id) } }
UITableViewDataSourceをUITableViewDiffableDataSourceに変更する
struct Section { let items: [Item] }
このようなセクションがあると仮定して
class SomeClass: UITableViewDataSource { let sections: [Section] func numberOfSections(in tableView: UITableView) -> Int { return sections.count } func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int { return sections[section].items.count } func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell { /// cellをデキューして加工して返す処理 } }
というUITableViewDataSourceの実装があった場合の変更点を示します。
まず、Section をHashableに適合させます。
次に、UITableViewDataSourceの代わりにUITableViewDiffableDataSourceを使うように変更します。
class SomeClass { private var dataSource: UITableViewDiffableDataSource<Section, Item>? func setupDataSource(tableView: UITableView) { dataSource = UITableViewDiffableDataSource<Section, Item>(tableView: tableView, cellProvider: { [weak self] (tableView, indexPath, item) -> UITableViewCell? in /// func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCellと一緒の内容 } } func setupSnapshot() { var snapShot = NSDiffableDataSourceSnapshot<Section, Item>() let sections: [Section] = /// 省略 snapShot.appendSections(sections) sections.forEach { snapShot.appendItems($0.items, toSection: $0) } dataSource.apply(snapShot) } }
setupDataSourceはViewControllerのViewDidLoad、setupSnapshotはsetupDataSourceより後でデータが取得できたタイミングで実行すれば良いと思います。
また、変更がある場合は現在のスナップショットをdataSourceから取得できるので、それに対して変更を加えて再度applyするだけで良いです。
performBatchUpdateなどの処理
dataSourceにapplyしたらTableViewにも反映されるので不要になります。
結果
日に数件エラーが出ていたのですが、0件になりました。
今回はTableViewに対しての改善でしたがCollectionViewにも同様のAPIが存在するので、そちらも改善していきたいと考えています。
参考
Appleが提供しているサンプルプロジェクトです。
2021年3月18日時点では WiFiSettingsViewController や TableViewEditingViewController がUITableViewDiffableDataSourceを使っているので参考になると思います!
API Serverの新規開発時に導入してみて良かった事
DELISH KITCHEN開発部の福山です。 社内向けシステムとしてAPI Serverを新規に構築する機会がありました。新規開発にあたり導入してみて良かった事をいくつかご紹介したいと思います。 新規GitHubリポジトリを用意してREST APIをGoで実装する。Webフレームワークはechoを採用。インフラはAWS ECS、RDSを利用。ログ情報はfluentd経由でS3やTreasuredataに格納しています。SentryやDatadogによる監視も行っています。 『DELISH KITCHEN』のメインAPI Serverの方で途中から採用された内容とほぼ同じ内容となります。今回は実装初期段階でpre-commit を導入しました。
pre-commitを使えばローカルでのGit commit時に任意のスクリプトを実行出来ます。 以下の処理が行われる様に設定されています。 主に実装内容の静的解析を行っておりcommit前にルールから外れたコードを発見し修正を促します。
その他go generate契機でmockファイルの作成や wire でDIコードの生成処理(*後述)を実行しています。 コードレビュー時にレビュアーがコードフォーマットや生成ファイルの有無等の指摘をする必要が無くなり、仕様やバグのチェックに集中出来る様になりました。 自動テストは導入しているのですが、更に実装初期段階からGithub Actionsにて reviewdog/golangci-lint を導入しました。
golangci-lintには 様々なLinter が用意されておりプロジェクト状況に合わせて任意のLinterを利用出来ます。 今回の開発では以下のLintチェックを有効化しています。 pushした内容に指摘対象のコードが存在する時にGithub上で以下の様に表示してくれます。
既存のシステムでMVC的な構成で苦労する場面が有りました。Goで ざっくり過ぎる図解なのですが以下の様なパッケージ構成となっております。(→は依存方向)
最低限下記は意識しつつ、ルールに拘り過ぎて工数が掛かり過ぎない様に状況に応じて詳細実装を進めました。 handlerパッケージから wire で生成されたコードでDependency Injectionされる構成となっております。
動作のポイントとしては 一般的に言われている事ですがテスタブルになりました。
MVC構成だと要件ロジックのユニットテストを書く時も依存するデータベース情報等を実際に用意する必要が有りました。しかし抽象に依存しつつパッケージレイヤーを切った事により、例えば 単一パッケージにほぼ全てのロジックを詰める様な形だと肥大したり処理の責務等は考えなくなってしまう可能性が高いのですが、
要件ロジックをどのパッケージレイヤーに書くべきかを個人的にもチーム内でも意識する様になりました。
実際にPRレビューの時にチームメンバーと議論する事が有り、結果として当初より見通しの良いコードになる事が有りました。
この部分は個々人の解釈の違いも有るので工数が膨らみ過ぎないバランスで進める様にしています。 新規開発を行うタイミングで導入して良かった事として
はじめに
前提技術スタック
pre-commit、CIでのLintチェック、パッケージをクリーンアーキテクチャ構成にする
pre-commit
- go generate
- go vet
- gofmt
- goimports
- golint
- wire
良かった事
CIでのLintチェック
- bodyclose
- deadcode
- depguard
- errcheck
- goconst
- gocritic
- gofmt
- goimports
- gosec
- gosimple
- govet
- ineffassign
- interfacer
- misspell
- nakedret
- noctx
- prealloc
- scopelint
- staticcheck
- structcheck
- typecheck
- unconvert
- unparam
- unused
- varcheck

良かった事
pre-commitと同じなのですがレビュアーに指摘される前に自動チェックが行われる為、コードレビュー時に仕様やバグのチェックに集中出来る様になりました。
具体的にはgosecでセキュリティ面での指定が有ったり、gosimpleでシンプルなコードの書き方に気付かされたりとコードの品質向上のきっかけとなります。
特に実装初期段階から導入した事によりほぼ全てのコードが随時チェックされている事になるので途中から採用するよりオススメです。パッケージをクリーンアーキテクチャ構成にする
domain/model的なパッケージとデータの永続化処理は切り離したいと考え今回はクリーンアーキテクチャ構成で実装する事にしました。
(色々なクリーンアーキテクチャの詳細解釈が存在するのであくまで一例とお考え下さい。)
- 依存方向を守る(domainは他に依存しない)
- 抽象に依存する(interfaceに依存する)
domain/repositoryで定義されたinterfaceの詳細実装はinfrastructureに存在しており、注入された内容として実行される様になっています。
他にはWebフレームワークの固有処理もhandler内に閉じておりusecase以降には影響しない様になっています。良かった事
usecaseでのユニットテスト時にパッケージ内で扱う永続化処理に対してmockを利用し任意の結果が返却出来る事になります。
従ってテスト対象パッケージ以外の状態に悩まされる事無く確認したい要件ロジックに集中してユニットテストを行う事が出来る様になりました。
まとめ
pre-commit、CIでのLintチェック、パッケージをクリーンアーキテクチャ構成にするをご紹介しました。
工数面のバランスや未経験な技術要素を導入するリスクも有りますが開発工程初期に開発効率を向上させる仕組みを用意するメリットは大きいと考えています。
まだ開発は続きますので良い仕組みを活かして効率良くアウトプットしていきたいと思います。
Core Web Vitalsの計測環境を整える

はじめに
現在、MAMADAYSのWebチームでは昨年発表されたCore Web Vitalsを中心としたパフォーマンス改善に注力しています。 今回はパフォーマンス改善でも重要な計測部分について、MAMADAYSではどのようにCore Web Vitalsのデータを定点観測する環境を整えているのかをご紹介したいと思います。
Core Web Vitalsとは
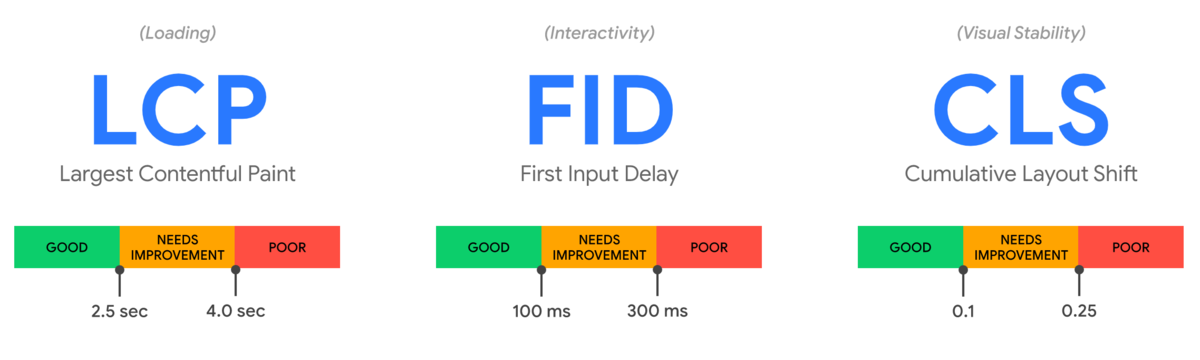
Core Web Vitalsとは、全てのサイトにおいて共通してユーザー体験をよくするために重要な、Google社が提唱するパフォーマンス指標のことです。本記事ではCore Web Vitalsの解説を目的としないため、詳細な説明は割愛しますが、Core Web VitalsにはLCP・FID・CLSという3つの具体的なパフォーマンス指標があり、将来的にはGoogle検索のランキング要因にも組み込まれると言われています。
LabデータとFieldデータ
パフォーマンス改善をする際に重要になってくるのがパフォーマンスの定点観測ですが、計測データは大きく分けて以下の2種類があります。それぞれにメリットとデメリットがあるので、両方をうまく使い分けながらサイトのパフォーマンス観測を行っていくことが大切になります。
Labデータ: Googleが開発するLighthouseなど特定の環境下で収集されたパフォーマンスデータのことです。特定の環境下で行うことにより再現可能なデータを提供でき、パフォーマンス観測もしやすいのがメリットですが、実際の利用者との実行環境の差異がある可能性があります。
Fieldデータ: 利用者の実際の環境下で収集されたパフォーマンスデータのことです。実際の利用環境のパフォーマンスが収集できることがメリットですが、収集するデータにはばらつきがあるためFieldデータに比べると観測がしにくいです。
参考: https://web.dev/how-to-measure-speed/#lab-data-vs-field-data
計測環境の検討
計測環境の検討にあたっては有料の計測サービスの SpeedCurve やNext.jsでVercelを使っていればNext.js製の Analytics も候補に出ると思います。ただ、MAMADAYSではBIツールとしてMetabase、分析データの保存先としてBigQueryを使っているのでうまく既存のアセットを生かした形でコストをかけずに実現する方法を模索していました。
Labデータの計測
Labデータの計測にあたっては、PageSpeed Insights API を利用してLabデータの収集を行っています。PageSpeed Insights はブラウザでサイトのパフォーマンスを確認できるツールとして便利ですが、APIも用意されており、簡単に同じデータを取得することができます。
// PageSpeed Insights APIのレスポンスの一部抜粋 { "lighthouseResult": { "audits": { "largest-contentful-paint": { "id": "largest-contentful-paint", "title": "Largest Contentful Paint", "description": "Largest Contentful Paint marks the time at which the largest text or image is painted. [Learn more](https://web.dev/lighthouse-largest-contentful-paint/)", "score": 0.92, "scoreDisplayMode": "numeric", "displayValue": "1.1 s", "numericValue": 1110 }, "total-blocking-time": { "id": "total-blocking-time", "title": "Total Blocking Time", "description": "Sum of all time periods between FCP and Time to Interactive, when task length exceeded 50ms, expressed in milliseconds. [Learn more](https://web.dev/lighthouse-total-blocking-time/).", "score": 0.97, "scoreDisplayMode": "numeric", "displayValue": "110 ms", "numericValue": 105 }, "cumulative-layout-shift": { "id": "cumulative-layout-shift", "title": "Cumulative Layout Shift", "description": "Cumulative Layout Shift measures the movement of visible elements within the viewport. [Learn more](https://web.dev/cls/).", "score": 1, "scoreDisplayMode": "numeric", "displayValue": "0", "details": { "items": [ { "finalLayoutShiftTraceEventFound": true } ], "type": "debugdata" }, "numericValue": 0.00018970055161544525 } } } }
注意点として公式でも記載されていますが、Lighthouseのように特定の環境下でユーザーなしにパフォーマンス計測をする場合にFIDは計測できません。したがって、LabデータでFIDの計測を行いたい場合は代替手段としてFIDと相関のあるTotal Blocking Time (TBT)を見るようにします。
MAMADAYSではこちらのAPIを利用して、複数ページを2時間おきにデータを収集し、BigQueryに転送しています。1回のみ特定のページを毎日計測する方法だとパフォーマンスデータとしてはあまりにも信憑性に欠けてしまうので複数のページで頻繁にデータを取得するようにしています。
Fieldデータの計測
パフォーマンス改善に取り組み始めた当初、前述したLabデータの観測のみを行っていました。ただ、Labデータのみだと実際の環境下でのパフォーマンスデータが観測できないことが課題としてあり、Fieldデータの計測方法を検討しました。
Next.jsとGoogle Analyticsを利用した計測基盤の構築
まずはWeb側のデータ収集方法ですが、MAMADAYSのWebではNext.jsを採用しており、Next.jsはバージョン9.4から標準機能としてCore Web Vitalsの計測を行えるようになったのでその機能を使って公式のガイドを参考に実装しました。また、収集したパフォーマンスログはすでに連携済みだったGoogle Analyticsのイベントとして保存することで継続してパフォーマンス推移を観測できる環境を作りました。
// pages/_app.js // googleAnalyticsのイベントとしてパフォーマンスデータを保存 function performanceMetricsEvent({ id, name, label, value }) { const eventValue = Math.round(name === 'CLS' ? value * 1000 : value); window.gtag('event', name, { event_category: 'パフォーマンス', value: eventValue, event_label: id, non_interaction: true, }) } // Next.jsの標準機能 reportWebVitalsを定義する export function reportWebVitals(metrics) { performanceMetricsEvent(metrics); }
参考: https://nextjs.org/docs/advanced-features/measuring-performance
直面した問題点
しかし数週間こちらの計測方法で検証していたところ、送っているイベントのラベルがページロードごとのユニークな値にしているため、ラベル数が上限に達してしまい他のイベントに影響を及ぼしてしまう問題がGoogle Analyticsのアラートから発覚しました。

その時点で対応するのであれば、全体の利用者の何割かに絞って計測をすることで上記の問題は解決できそうでしたが、今後利用者の増加を考慮して計測基盤の見直しを行いました。
計測方法の改善
計測基盤を見直すにあたって、MAMADAYSでは分析にBigQueryを使用しているためBigQueryへの転送を考えました。
また大量のパフォーマンスログのデータ転送をアプリケーションとは切り離して行うために、サーバー側はパフォーマンスのログ出力のみを行い、fluentdでBigQueryへのストリーミング挿入し、dailyでシャーディングテーブルを作るように変更しました。fluentdでは fluent-plugin-bigquery というgemを使うことによって簡単にfluentdでのBigQueryへのストリーミング挿入が実現できます。
ログの出力形式
{"id":"1618905791407-4433185739018","label":"web-vital","level":"INFO","name":"LCP","path":"/articles/999","time":"2021-04-20T08:03:11.870117321Z","type":"WEB_PERFORMANCE","value":"1500"}
fluentdでのinsert部分の設定
<label @web-performance-log>
<filter **>
@type grep
<regexp>
key $.parsed_log.type
pattern ^WEB_PERFORMANCE$
</regexp>
</filter>
<filter>
@type record_transformer
renew_record
enable_ruby
<record>
id ${record["parsed_log"]["id"]}
time ${record["parsed_log"]["time"]}
label ${record["parsed_log"]["label"]}
name ${record["parsed_log"]["name"]}
path ${record["parsed_log"]["path"]}
value ${record["parsed_log"]["value"]}
</record>
</filter>
<match **>
@type bigquery_insert
auth_method json_key
json_key /etc/secrets/google-credentials/fluentd-to-bq.json
project "#{ENV['BQ_PROJECT']}"
dataset "#{ENV['BQ_DATASET']}"
table web_performance_%Y%m%d
auto_create_table true
<buffer time>
@type file
flush_interval 30s
path /var/log/fluentd-buffers/bq-event.buffer
timekey 1d
</buffer>
schema [
{"name": "id", "type": "STRING"},
{"name": "time", "type": "STRING"},
{"name": "label", "type": "STRING"},
{"name": "name", "type": "STRING"},
{"name": "path", "type": "STRING"},
{"name": "value", "type": "STRING"}
]
</match>
</label>
この改善により、BigQueryのストリーミング挿入でコストが多少掛かってしまいましたが、他の分析への影響を与えずにFieldデータの継続的な観測を実現できました。また、Google Analyticsへのデータ保存時にはMetabaseというBIツールで計測結果が見れるようにBigQueryへのデータの加工と転送を自前で別途行う必要がありましたが、直接BigQueryに転送できたことでその手間も省ける結果となりました。
まとめ
今回はWebパフォーマンスの計測でCore Web Vitalsをどう計測しているのかについて話しました。パフォーマンス改善において、憶測ではなく現状のボトルネックなどを正しく理解して改善する上でもパフォーマンスの継続的な計測は重要になってくると思います。計測方法やGoogle Analyticsでの問題に関して同じような課題に直面されている方の参考になれば幸いです。
MAMADAYSのWEBチームではパフォーマンス改善に注力しており、改善結果も出ているので実施した改善内容についても今後お話していきたいと思います。