はじめに
DELISH KITCHEN のデータベースについて紹介します。
サービスやバックエンドシステムの全体像については DELISH KITCHEN のサービスとバックエンドシステムのお話 - every Engineering Blog で紹介しています。よろしければご覧ください。
概観
DELISH KITCHEN ではサービスの大半のデータの保存に Amazon RDS を使用しており、データベースエンジンとしては主に MySQL を使用しています。サーバーがいくつかに分かれておりデータベースもそれぞれにありますが、今回はレシピやユーザーの情報の入ったメインのデータベースの話をします。
DELISH KITCHEN は規模としては月間総利用者数※ 5200 万人のサービスです。
※ DELISH KITCHEN のアプリ、Web、SNS、サイネージなど全ての提供内容における総利用者数のこと。
オンメモリキャッシュ
レシピなどのマスタ系のデータについては、更新頻度が低いことからサーバーアプリ内にオンメモリキャッシュを持ち、定期的に更新するというアプローチを取っています。管理画面外からのアクセスにはそのキャッシュを利用しており、トランザクション系のデータの読み書きについてはキャッシュは行わずサーバーから RDB へ読み書きを行っています。
RDB 負荷分散
MySQL レプリケーションを利用して複数のインスタンスへ負荷を分散しています。また、マスタ系とトランザクション系の DB インスタンスを分けており、トランザクション系の方の RDS インスタンスタイプを大きめにしています。
Amazon Aurora の導入
最近読み込み頻度が高く、レコード量が将来的に数千〜億単位になることが見込まれ、かつ読み書きのレイテンシがアプリの初期描画速度に影響するために相応に低いことが求められるデータの保存方法を考える機会がありました。 書き込みは素直なテーブル構造にするとランダムインサートとなり、通常の RDS ではレコード量増加に伴って書き込みのレイテンシは増えていくことが想定されました。
そこで、レコード量が増加しても I/O が低下しにくい Amazon Aurora MySQL を導入しました。導入にあたり簡単な負荷試験をして RDS (MySQL) との比較を行いましたのでその概要を紹介します。
Aurora と非 Aurora RDS の負荷試験による比較
ランダムインサートを行う下記のような簡素な Go のコードを実行し、レコード量増加に伴った INSERT のスループットの変化を確認しました。
func main() {
insertedCount := int64(0)
insertStart := time.Now()
countMutex := sync.RWMutex{}
wg := &sync.WaitGroup{}
for i := 0; i < 8; i++ {
wg.Add(1)
go func() {
sess := getSession() // DB セッションを作成
for insertedCount < 10000000 {
// 主キーをランダムに発行した適当なレコードを INSERT
record := genNewRecord()
if _, err := sess.InsertInto("test_table").Columns("col_a", "col_b").Record(record).Exec(); err != nil {
panic(err)
}
countMutex.Lock()
insertedCount++
if insertedCount%100000 == 0 { // 100000 レコードごとに経過時間を出力
fmt.Println(insertedCount, time.Now().Sub(insertStart))
}
countMutex.Unlock()
}
wg.Done()
}()
}
wg.Wait()
os.Exit(0)
}
結果的に、レコード量が増えても Aurora ではまるでスループットは一定でしたが、非 Aurora では対数的ではありますが顕著な増加が見られました。(グラフはイメージです)
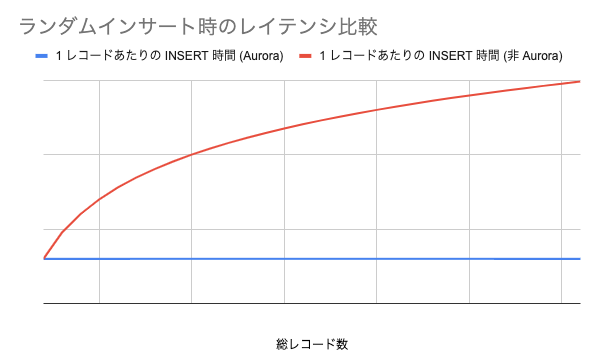
導入決定〜使用開始まで
Aurora RDS インスタンスの作成、サーバーアプリからの接続までについては非 Aurora のそれとあまり変わりませんでした。DB インスタンスがたとえ 1 つのみでも Aurora クラスターが作成され、Web コンソールの DB 一覧を見るとクラスタ配下にインスタンスがあると表示されます。
MySQL 互換なので、接続後は通常の MySQL エンジンと(完全ではないようですが)同じように使用できます。導入後のパフォーマンスについてはまだレコード数が多くないのであまり大きなことは言えませんが、期待通り動作しています。
Aurora を監視する
Aurora は非 Aurora の RDS と比べて取れるメトリクスが変わってきます。How to Collect Aurora Metrics | Datadog に非常にわかりやすくまとまっていたので、参考にして以下の項目に合致するメトリクスをモニタリングしています。
- Query throughput
- Query performance
- Resource utilization
- Connections
- Read replica metrics
最後に
DELISH KITCHEN のデータベースについての紹介でした。DELISH KITCHEN ではレシピ動画サービスの安定稼働に向けて改善を続けています。お読みいただきありがとうございました。