はじめに
はじめまして。2021年4月にエブリーに入社した山西と申します。
A/Bテストについて
DELISH KITCHENのアプリでは機能の改善に向けたUIやアプリ内動線等の変更を定期的に実施しております。A/Bテスト によりそれらの効果を事前検証することで、変更を施すべきか否かの意思決定への還元を行っています。
A/Bテスト は、文字通りAパターン(変更前)とBパターン(変更後)の結果を比較する手法です。一部ユーザー(テスト群)のみに介入した結果の効果を、変更を施さなかったユーザー(コントロール群)と比べて検証する手法 とも言い換えられます。
A/Bテストの流れ
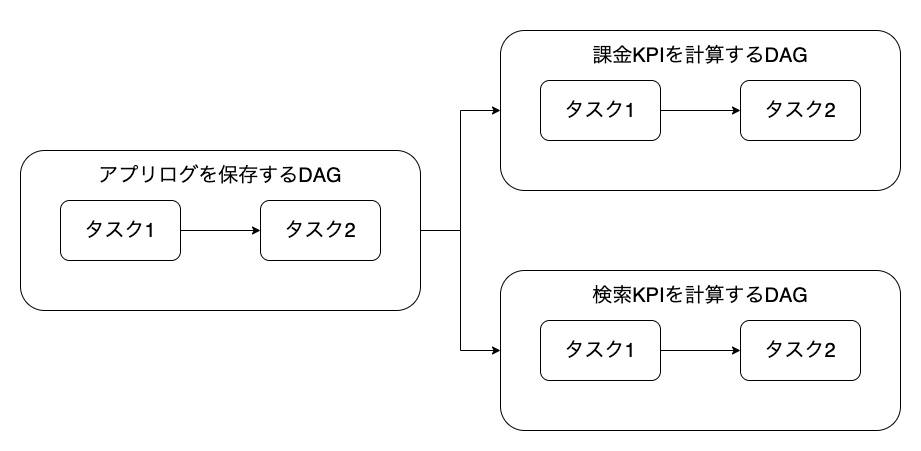
プロダクトマネージャー、データサイエンティストが連携しつつ実施することとなります。
A/Bテストの流れ
1. 施策の企画
2. 評価指標の選定
3. 対象ユーザーの抽出
4. 施策の実施
5. 結果の集計
6. 結果の報告
7. 意思決定
本記事では以後、2.の評価指標を選定するプロセスについて掘り下げていきます。
評価指標の選定
前述の通り、施策の効果による「良し悪し」をA/Bテストによって見極めるためには、その目的にあった評価指標を設定する必要があります。
指標の分類
これらの分類は書籍『A/Bテスト実践ガイド』 にて提唱されているものです。
ゴール指標
ビジネスにおける最終的な目標を直接反映した指標。
施策に携わるステークホルダー間で広く受け入れられるようなシンプルなものであるのが望ましい。
ドライバー指標
ユーザー体験等を元にした、ビジネス目標を間接的に表現する指標。
短期的に観察することが出来、その変動が捉えやすいという特徴を持つ。
ゴール指標の代理指標としての役割も担う。
ガードレール指標
施策が問題なく進行しているか確認するための指標
予期せぬバグ等でユーザー体験が悪化してないかを確認する指標
また、優れたオンライン実験を設計するためには各指標が『短期的(実験期間内で)に測定可能であり、計算可能であり、十分に敏感(分析感度)で即時的(即時性)に反応するものでなければならない。』ことが書籍『A/Bテスト実践ガイド』で指摘されています。
指標の実装
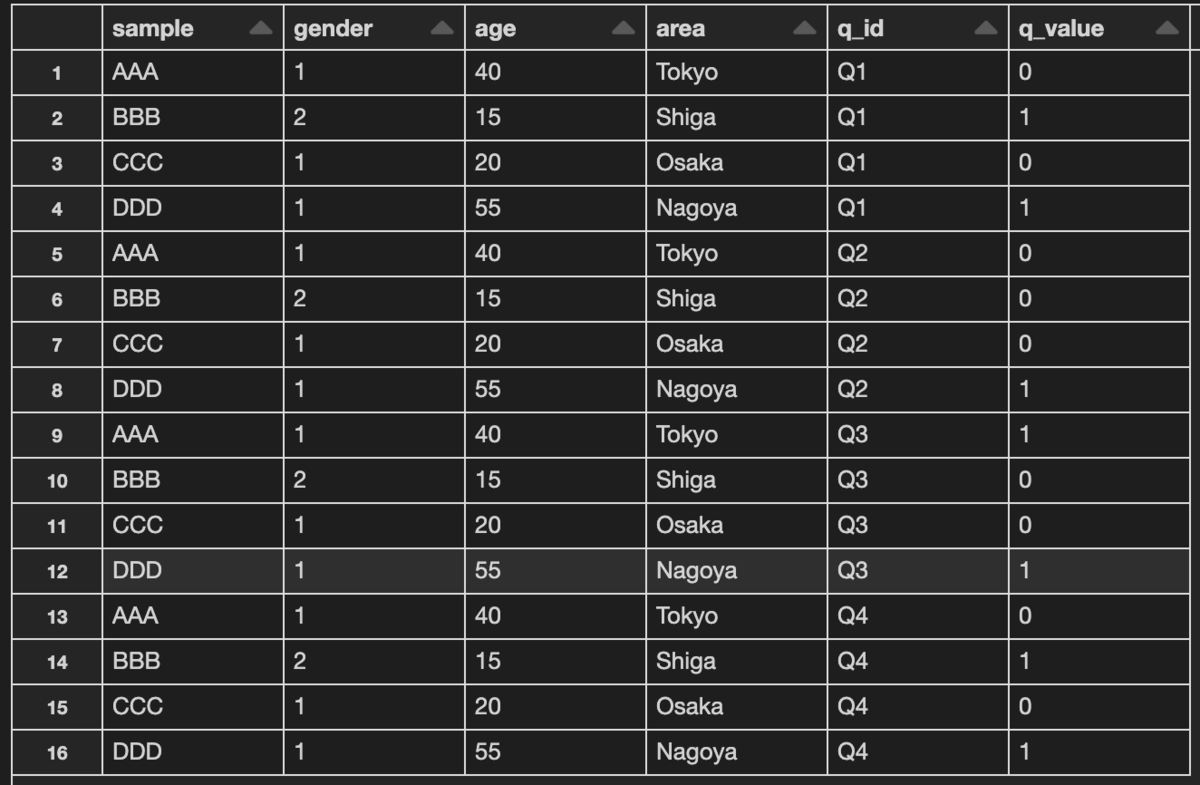
施策の目的と指標分類のフレームワークを照らし合わせながら評価指標を洗い出し、それらが集計可能であること(元となるログが存在していること)を確認した後は、各々の評価指標を集計するためのSQLクエリを作成します。
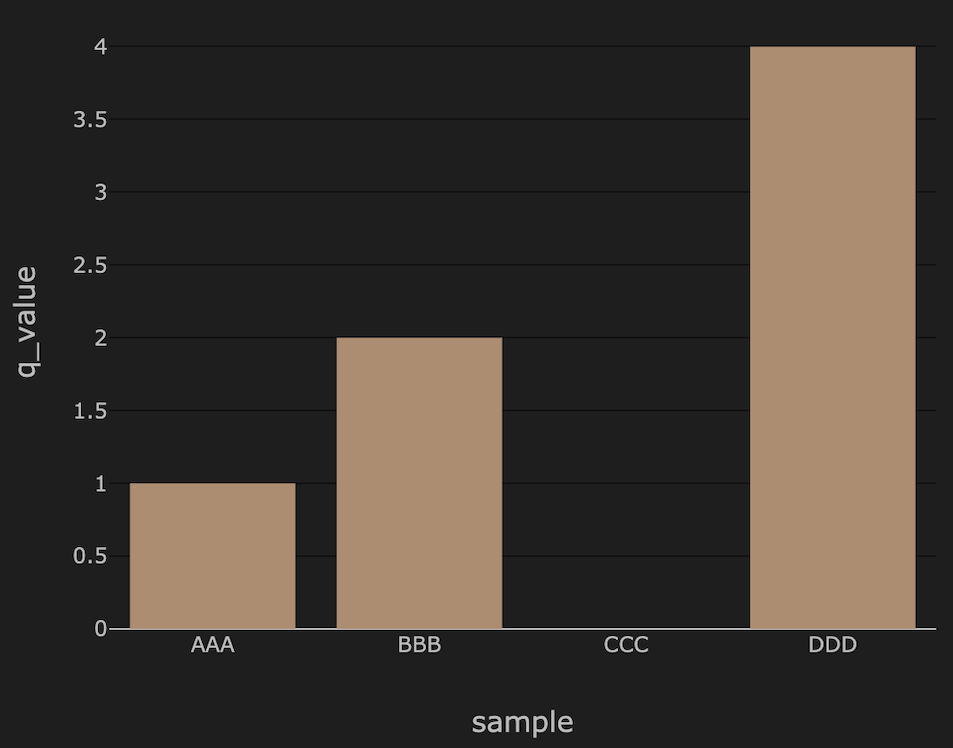
ダッシュボード可視化の例
大変だったこと
次に、施策の目指す向きをうまく表現する指標を選定したり、それを実装へ落とし込むために元となるログ周りを理解したり、さらにプロダクトマネージャーと連携したりする過程で大変だったことについて紹介します。
指標の選定作業
ゴール指標の代理指標の設定
本来は上記の指標の分類にて挙げたゴール指標で施策の良し悪しの意思決定が出来れば理想ですが、実際には代理指標(指標の分類でいうところのドライバー指標)を設定し、これを主要な指標として観察していく場合も多々あります。
この際には代理指標としての妥当性(擬似相関になっていないか、因果関係まで整理できているか)の模索に、多くのリソースを割かなければなりません。
施策の影響範囲を見極めた集計
ひとえに施策の効果を測るといっても、集計対象とするユーザーをどう選ぶかでその意味合いは大きく変わります。
「使った人がどう反応するか」を知りたいとき
機能の使い心地に介入するような施策を打った場合は、その機能が利用されない限り効果を測ることが出来ないため、機能利用実績があるユーザーのみを集計対象とするのがふさわしいといえます。
「使わなかった人がどれだけ使ってくれるようになったか」も含めて知りたいとき
アプリ内動線の追加や、デザイン変更等で機能の利用を促す施策を打った場合はその機能の獲得傾向に興味があるため、注目する機能を利用していないユーザーも集計対象となります。
このようにして「どのユーザー集団に対して平均を取り、そこから何を知りたいのか」をイメージしながら意味のある指標に落とし込むにはアプリのUI/UX側の深い理解が必要だと感じました。
ログ周りの理解
ログの仕様および状態の確認
評価指標を実装するためには当然その元となるログの存在が前提となるため、選定時点でそれらの仕様を頭に入れておく必要があります。
実装したい評価指標に対応するログが存在しない場合の対処
もし評価指標の実装に必要なログが存在しない場合は、以下のいずれかの選択肢を取ることになります。
これらのうちどの方向に舵を切るかは、当該指標のビジネス的な重要性、意思決定までのタイムリミットから逆算した施策の実施期間、他部署のリソース等の間のトレードオフ関係の熟慮ののちに各ステークホルダーと相談することによって決定されることとなります。
プロダクトマネージャーとの連携
わかりやすく説明する能力
流れの説明 にて解説した通り、A/Bテストの狙いはその分析結果をプロダクトマネージャーへ報告し、そこから意思決定につなげる洞察を得ることです。
評価指標についてのすり合わせ
指標の分類 の項でも述べたように、プロダクトマネージャーが追跡するKGIなどのビジネス指標とA/Bテストとして設定する評価指標は必ずしも一致しない場合が多くあります。ゴール指標の代理指標の設定 にて説明した懸念に直面するため、この場合はより効果検証にふさわしい代理指標を主に見ていくことになります。
最後に
「コントロール群とテスト群を比較する」というコンセプトだけ聞くと単純明快な印象を受けがちなA/Bテストですが、それを良質な意思決定へつなげるためには一筋縄にはいかない工夫が必要であることをこの数ヶ月間の業務で改めて認識しました。
参考文献
Ron Kohavi,Diane Tang,Ya Xu,大杉 直也.(2021)「A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは (Japanese Edition) 」
Alex Deng, Xiaolin Shi. Data-Driven Metric Development for Online Controlled Experiments: Seven Lessons Learned. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD, 2016