はじめに
こんにちは、DELISH KITCHENのiOSアプリ開発をしている山口です。
今年のWWDC21でiPadのSwift Playgroundsを使ってアプリ製作ができるようになるというアナウンスがありました。本当はそれを試そうと思ったのですが、執筆時点だとまだPlaygroundsが対応していないようなので、今回は前段として、iPadのPlaygroundsでSwiftUIを使って簡単な動くものを作ろうと思います。
そもそも今までXcodeでの開発はやっているもののMac・iPadどちらのPlaygroundsもまともに使ったことがなく、またSwiftUIもちゃんと使ったことがない状態からのスタートになります。
使用端末は、iPadPro 11インチ(2018)です。
実作に作ってみる
あまりデザインなどは考えずに、カップラーメンタイマーを作ろうと思います。
カップラーメンの種類によっても時間が違ってくるので、3分、5分のようにデフォルトでいくつか設定できるのと、すこし硬めに麺を作りたい時もあると思うので、自分で時間を設定できるようにしようと思います。
1. プロジェクトをつくる
左上の新規作成マークを押すと新しいプロジェクトファイルができました。
そもそもSwiftという言語を学ぶためのアプリということもあり、Page(キャプチャーのようなものを作って)ステップごとに学んでいけるようになっているようです。
Source Code部分は走らせた時に自動実行されるMainと、モジュールという構成になっています。
今回は既存のプロジェクトを参考に使っていきます。
2. Mainを書く
SwiftUIのViewをUIHostingControllerに渡してそれをPlaygroundのLiveViewに渡せば表示はできるようになるみたいです。
UIHostingController(rootView: xxx) PlaygroundPage.current.liveView = yyy
3. SwiftUIで画面をつくる
とりあえず、こんな感じに書きました。
ちなみにモジュール内で定義しているのでMainで読むためにPublicにさせられます。
public var body: some View { VStack { Spacer() HStack(spacing: 24) { ForEach(model.preset, id: \.self) { time in Button(action: { setTime(time: time) }) { Text("\(time) m") .foregroundColor(selectedTime == time ? Color.black : Color.white) .font(.largeTitle) } .padding(.init(top: 8, leading: 8, bottom: 8, trailing: 8)) .background(selectedTime == time ? Color.yellow : Color.gray) .cornerRadius(8.0) } Button(action: { model.alertRelay.send(("Input new time", true)) }) { Text("+") .foregroundColor(Color.white) .font(.largeTitle) } .padding(.init(top: 8, leading: 16, bottom: 8, trailing: 16)) .background(Color.gray) .cornerRadius(8.0) } Spacer() Text("\(seconds) s") .foregroundColor(Color.white) .font(.system(size: 64, weight: .bold)) .fontWeight(.bold) Spacer() Button(action: { isPlay ? stopTimer() : startTimer() }) { Text(isPlay ? "Stop" : "Start") .foregroundColor(Color.black) .font(.largeTitle) .fontWeight(.bold) } .padding(.init(top: 8, leading: 32, bottom: 8, trailing: 32)) .background(isPlay ? Color.yellow : Color.white) .cornerRadius(8.0) Spacer() } }
ただ単にVStackとHStackを組み合わせて要素を羅列しただけなのですが、Spacerが良い感じに間を取ってくれていて、それっぽいデザインになりました。
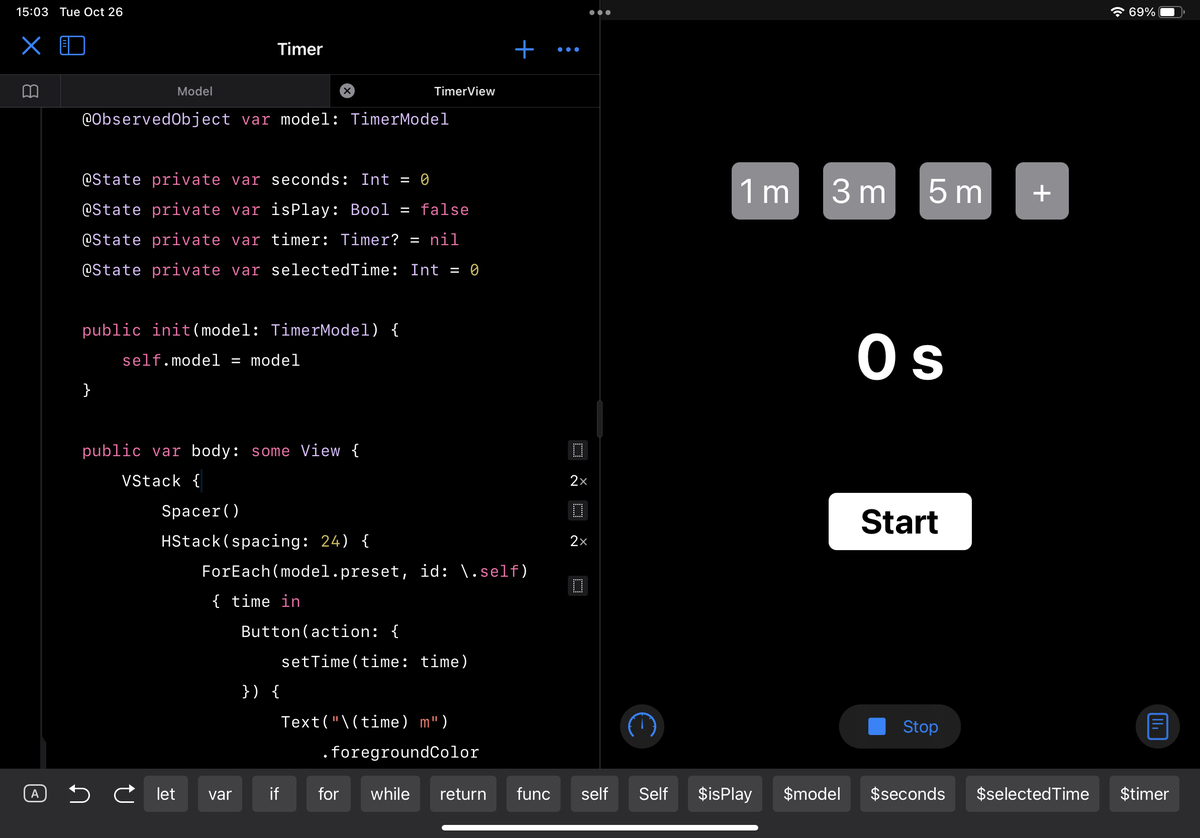
ボタンを押した時の色の変更などは、SwiftUIの@Stateや@ObservedObjectを使用すると、値の変更を自動検知して再描画してくれます。
public struct ContentView: View { @ObservedObject var model: TimerModel @State private var seconds: Int = 0 @State private var isPlay: Bool = false @State private var timer: Timer? = nil @State private var selectedTime: Int = 0
さて、Viewが組み立てられたので、あとはStartをタップした時に再生するようにして、Stopした時に一時停止するようにすればタイマーの完成です。
3. ロジックを書く
タップした時に、Timer.scheduledTimer()を使って1秒間隔で処理を実行させれば設定した時間分カウントダウンしてくれます。
timer = Timer.scheduledTimer(withTimeInterval: 1, repeats: true, block: { _ in guard seconds > 0 else { model.alertRelay.send(("Done", false)) setTime(time: selectedTime) stopTimer() return } seconds -= 1 })
あとは、適当にModelを定義してプリセットの時間をいくつか持てるようにしてあげます。
final public class TimerModel: ObservableObject { @Published var preset: [Int] = [1, 3, 5] ... }
ただカウントダウンするだけだと終わった時に気づかない可能性があるため、ダイアログを出すようにします。
今回は、Combineを使ってSwiftUI側からMain側に知らせるようにしました。
ついでに、ユーザがプリセットの時間を作る時もAlertのダイアログで指定できるようにしました。
let cancellable = model.alertRelay.sink{ [unowned vc] (title, isInputEnable) in guard !title.isEmpty else { return } let alertVC = UIAlertController(title: title, message: "", preferredStyle: .alert) if isInputEnable { alertVC.addTextField() } alertVC.addAction(UIAlertAction(title: "OK", style: .default) { _ in guard isInputEnable else { return } guard let value = Int(alertVC.textFields?[0].text ?? "") else { model.alertRelay.send(("Invalid time input", false)) return } model.addPresetTime(time: value) }) vc.present(alertVC, animated: true) }
これで全て動くようになりました!
| カウントダウン | 新しい時間をセット |
|---|---|
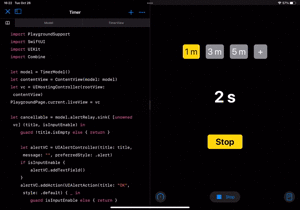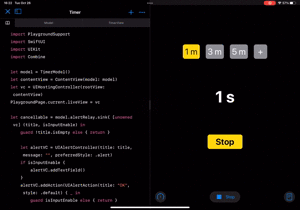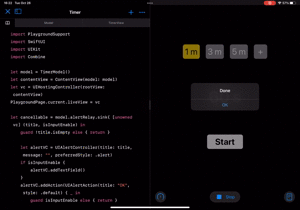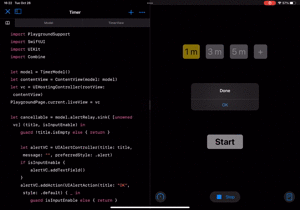 |
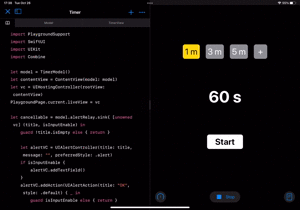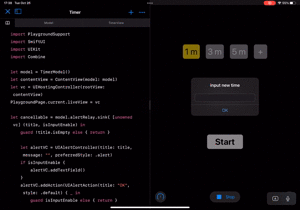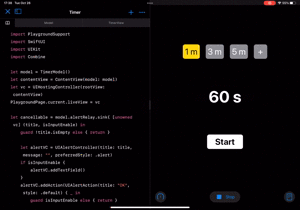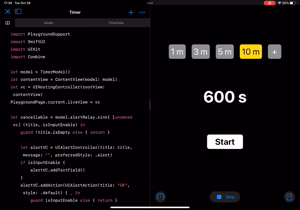 |
注意点
これは何かの相性なのかデフォルトの挙動なのかわからないのですが、プレビュー画面の左下にあるメニューの「Enable Results」が有効の状態で、実行するとSwiftUIの再描画がされない現象がありました。
最後に
普段UIKitを使ったUIしか作っていないので、今更ながらかなり新鮮でした。アイテムが規則的に並んでいる画面であれば、UIKitよりもかなり簡単に作れるので良さそうです。
iPadのPlaygrounds自体は、やはりSwiftを学ぶために最適化されていて、現時点だとアプリを作るのは大変そうです、ただMacを買わなくても身近な不満を手軽にアプリを作って解決できるようになるのは良い仕組みだなと感じました。
今回iPadのPlaygroundsのみで作ってみたのですが、最低外部キーボードがあれば、画面は多少小さいもののコーディングできそうでした。また、デスクだけでなくベッドの上などでもコーディングできるか試してみたのですが、意外とできたので将来的にiPadで快適に開発できる可能性も見えました。
以上、ありがとうございました!