
こちらはevery Tech Blog Advent Calendar 2024(夏) 17日目の記事になります。
こんにちは。 開発本部のデータ&AIチームでデータサイエンティストをしている古濵です。 変わらずML周辺の開発をもりもりしています。
今回は、DatabricksのFeature Storeについて検証した内容を共有します。
Databricks Model Servingについても検証記事をまとめていますので、ぜひご覧ください。
背景
現状、DELISH KITCHENを中心に、ML開発を進めており、今後のML開発のagility向上を見据えて、Feature Storeを導入することを検討しています。
DatabricksではFeature Storeを使う理由を、下記のようにまとめています。
参考
特徴量ストアとは |Databricks on AWS
発見性:Databricks ワークスペースからアクセスできるFeature Store UIでは、既存の特徴量を参照および検索できます。
リネージ:Databricksで特徴量テーブルを作成すると、特徴量テーブルの作成に使用されたデータソースが保存され、アクセスできるようになります。特徴量テーブルの各機能について、その機能を使用するモデル、ノートブック、ジョブ、エンドポイントにアクセスすることもできます。
モデルのスコアリングやサービングとの統合:Feature Storeの特徴量を使用してモデルをトレーニングする場合、モデルは特徴量メタデータと一緒にパッケージ化されます。モデルをバッチスコアリングまたはオンライン推論に使用すると、Feature Storeから自動的に特徴量が取得されます。呼び出し側はこれらの特徴量について知る必要はありませんし、特徴量を検索または結合して新しいデータをスコアリングするロジックを組み込む必要もありません。これにより、モデルのデプロイメントや更新が容易になります。
ポイントインタイムのルックアップ:Feature Storeは、特定の時点での正確性を必要とする時系列およびイベントベースのユースケースをサポートします。
上記含めて、DatabricksのFeature Storeに関するドキュメントを読んだ際、以下のような疑問を持ちました。
「Feature Store使わずに、Deltaテーブルから学習/推論すれば良いのでは?」
このように思った理由は、一般的なFeature Storeを使うメリットを、Unity CatalogとDeltaテーブルの機能でカバーできているのではないかと思ったからです(Unity Catalogに関してはこちらをご確認ください)。
これらを踏まえて、Feature Storeを使う場合と使わない場合の比較を実施しました。
検証した内容の共有の前に、前提条件となる弊社のDatabricksを活用したML開発状況をサマリます。
- ML開発はスモールスタート中で、モデル開発は1人もしくは2人
- バッチ推論がメインで、推論結果をサーバーのRedis(ElastiCache for Redis)にデプロイする運用
- DatabricksのUnity Catalogは最近使えるようになったばかり
Feature Storeを使う場合と使わない場合の比較
Basic example for Feature Engineering in Unity Catalogという、Databricksが提供しているサンプルノートブック(ワインの品質を予測するモデル作成例)を使って、Feature Storeを使う場合と使わない場合の比較を行いました。
事前準備
実行環境はDatabricks 13.3LTS Runtimeを使用し、ノートブックの最初に以下を実行しています。
%pip install databricks-feature-engineering dbutils.library.restartPython()
サンプルノートブックのうち、使う場合と使わない場合のどちらでも使用するコードを以下に定義します。
細かい説明はしませんが、wine_qualityのサンプルデータセットを準備し、Unity CatalogとFeatureEnginneringClientを使えるようにしています。
import pandas as pd from pyspark.sql.functions import monotonically_increasing_id, expr, rand from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup import mlflow import mlflow.sklearn from mlflow.tracking.client import MlflowClient from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score
raw_data = spark.read.load("/databricks-datasets/wine-quality/winequality-red.csv", format="csv", sep=";", inferSchema="true", header="true" ) def addIdColumn(dataframe, id_column_name): """Add id column to dataframe""" columns = dataframe.columns new_df = dataframe.withColumn(id_column_name, monotonically_increasing_id()) return new_df[[id_column_name] + columns] def renameColumns(df): """Rename columns to be compatible with Feature Engineering in UC""" renamed_df = df for column in df.columns: renamed_df = renamed_df.withColumnRenamed(column, column.replace(" ", "_")) return renamed_df # Run functions renamed_df = renameColumns(raw_data) df = addIdColumn(renamed_df, "wine_id") # Drop target column ("quality") as it is not included in the feature table features_df = df.drop("quality") display(features_df)
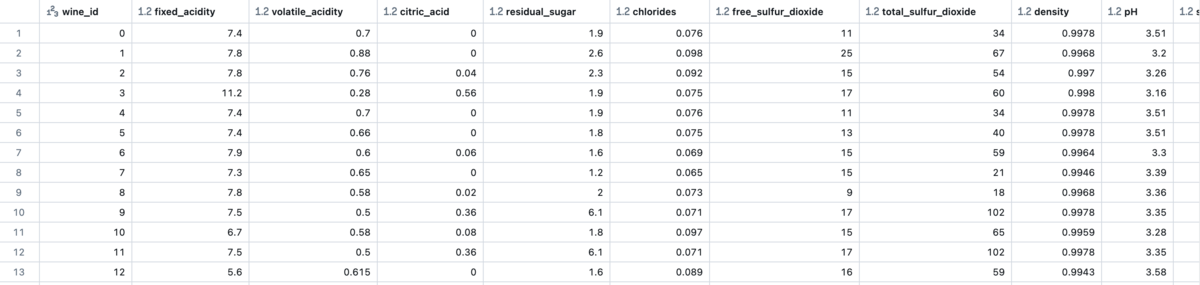
下記コードにはreal_time_measurementという特徴量の集計があります。
これが具体的にどんな特徴量なのか想像し難いですが、今回議論したい内容ではないため、Feature Storeに保存されていない特徴量という認識で進めます。
## inference_data_df includes wine_id (primary key), quality (prediction target), and a real time feature inference_data_df = df.select("wine_id", "quality", (10 * rand()).alias("real_time_measurement")) display(inference_data_df)
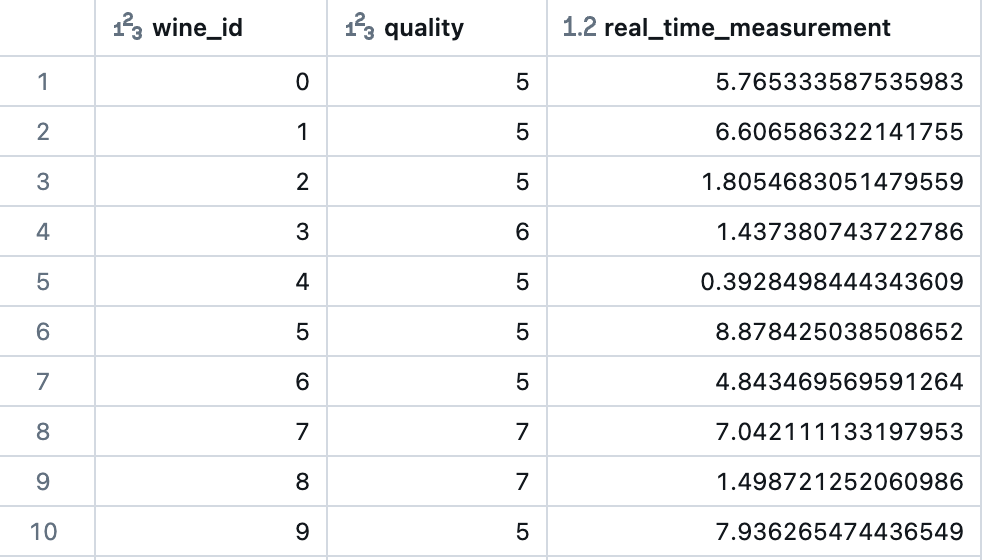
spark.sql("USE CATALOG uc_sandbox") spark.sql("USE SCHEMA naoki_furuhama") table_name = "wine_db"
fe = FeatureEngineeringClient()
特徴量テーブルの作成
Feature Storeを使う場合
fe.create_table(
name=table_name,
primary_keys=["wine_id"],
df=features_df,
schema=features_df.schema,
)
Feature Storeを使わない場合
features_df.write \ .mode("overwrite") \ .saveAsTable(table_name)

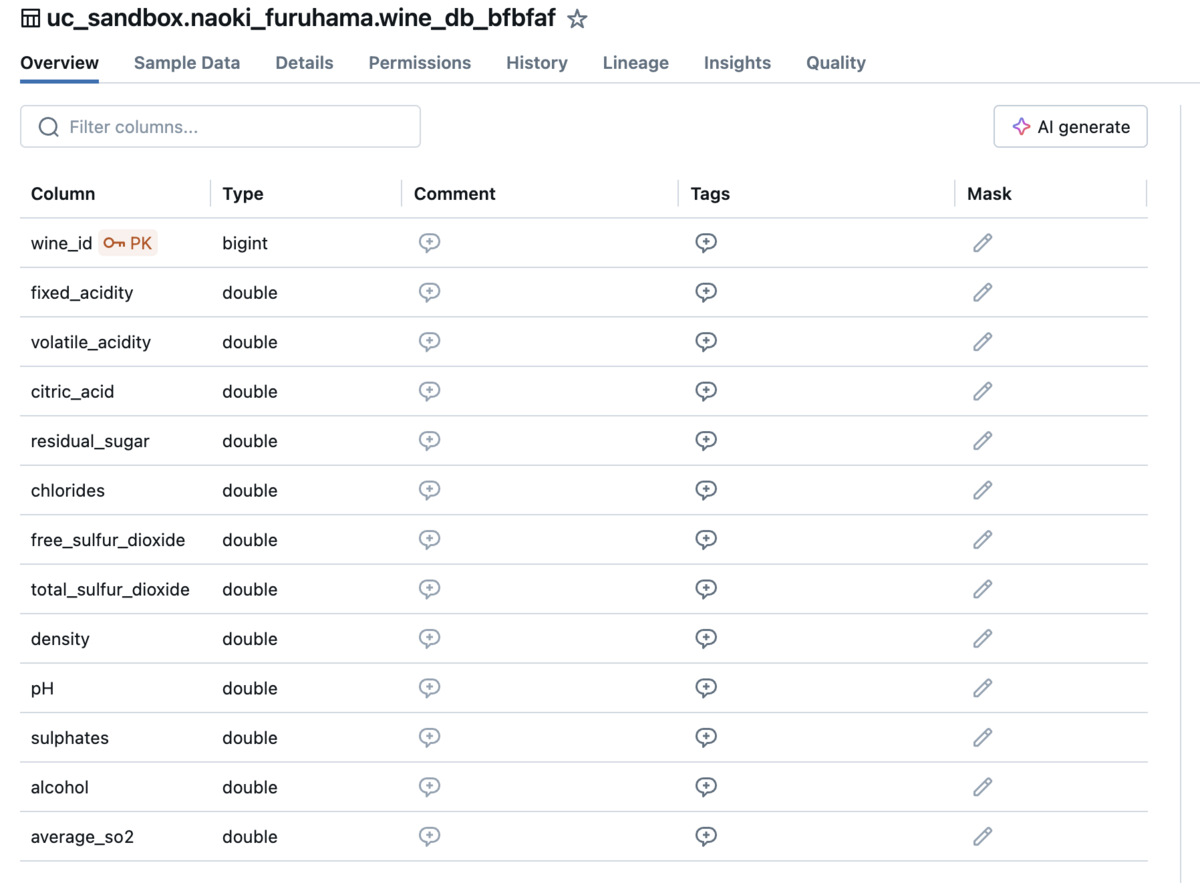
Feature Storeに特徴量テーブルとして保存する場合はFeatureEnginneringClientのcreate_tableメソッドを使います。
テーブルを作成して、スキーマを見るという観点だけはどちらも同じように見ることができます。
違いとして、Feature Storeを使う場合はprimary_keyの指定が必須で、primaly_keyを意味するPKがカラムの横に表示されているのがわかるかと思います。
なお、使わない場合で保存したとしても、Unity Catalog内のDeltaテーブルであれば、ALTER TABLEすることで、特徴量テーブルにすることもできます。
参考
Unity Catalogでの特徴量エンジニアリング | Databricks on AWS
特徴量テーブルの更新
特徴量テーブルに新しくカラムを追加する際のコードを対比してみます。
## Modify the dataframe containing the features so2_cols = ["free_sulfur_dioxide", "total_sulfur_dioxide"] new_features_df = (features_df.withColumn("average_so2", expr("+".join(so2_cols)) / 2))
Feature Storeを使う場合
fe.write_table(
name=table_name,
df=new_features_df,
mode="merge"
)
Feature Storeを使わない場合
new_features_df.write \ .mode("overwrite") \ .option("mergeSchema", "true") \ .saveAsTable(table_name)
特徴量テーブルの更新も作成と大きくは変わりません。
Feature Storeを使う場合は、write_tableメソッドを使って特徴量テーブルを更新します。
使わない場合は、mergeSchemaオプションを指定することでカラムが増えても問題なくDeltaテーブルを更新できます。
学習データの作成
Feature Storeを使う場合
def load_data(table_name, lookup_key): # In the FeatureLookup, if you do not provide the `feature_names` parameter, all features except primary keys are returned model_feature_lookups = [ FeatureLookup( table_name=table_name, lookup_key=lookup_key ) ] # fe.create_training_set looks up features in model_feature_lookups that match the primary key from inference_data_df training_set = fe.create_training_set( df=inference_data_df, feature_lookups=model_feature_lookups, label="quality", exclude_columns="wine_id" ) training_pd = training_set.load_df().toPandas() # Create train and test datasets X = training_pd.drop("quality", axis=1) y = training_pd["quality"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) return X_train, X_test, y_train, y_test, training_set # Create the train and test datasets X_train, X_test, y_train, y_test, training_set = load_data(table_name, "wine_id")
Feature Storeを使わない場合
def load_data() training_pd = inference_data_df.join( features_df, on=["wine_id"], how="left" ).toPandas() # Create train and test datasets X = training_pd.drop("quality", axis=1) y = training_pd["quality"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) return X_train, X_test, y_train, y_test # Create the train and test datasets X_train, X_test, y_train, y_test = load_data()
Feature Storeを使う場合は、FeatureLoookup機能を使ってFeature Storeに保存している特徴量テーブルを引っ張ってきます。
サンプルコードではFeatureLookupは1つしか指定していませんが、複数指定することで様々な特徴量テーブルを結合することが可能です。
そして、create_training_setメソッドを使って、起点となる(primary_keyやlabel等を含んだ)データと特徴量テーブルを結合して学習データを作成することができます。
使わない場合は、Deltaテーブルから特徴量テーブルを読み込んで、推論データと結合して学習データを作成します。
特徴量テーブル1つであれば、こちらの方がシンプルで可読性も高いですが、特徴量テーブルが増えるとleft joinを繰り返し記述することになります。
モデルの学習
検証用のモデルを準備します。
# Configure MLflow client to access models in Unity Catalog mlflow.set_registry_uri("databricks-uc") model_name = "uc_sandbox.naoki_furuhama.wine_model" client = MlflowClient() try: client.delete_registered_model(model_name) # Delete the model if already created except: None
Feature Storeを使う場合
# Disable MLflow autologging and instead log the model using Feature Engineering in UC mlflow.sklearn.autolog(log_models=False) def train_model(X_train, X_test, y_train, y_test, training_set, fe): ## fit and log model with mlflow.start_run() as run: rf = RandomForestRegressor(max_depth=3, n_estimators=20, random_state=42) rf.fit(X_train, y_train) y_pred = rf.predict(X_test) mlflow.log_metric("test_mse", mean_squared_error(y_test, y_pred)) mlflow.log_metric("test_r2_score", r2_score(y_test, y_pred)) fe.log_model( model=rf, artifact_path="wine_quality_prediction", flavor=mlflow.sklearn, training_set=training_set, registered_model_name=model_name, ) train_model(X_train, X_test, y_train, y_test, training_set, fe)
Feature Storeを使わない場合
mlflow.sklearn.autolog(log_models=True) def train_model(X_train, X_test, y_train, y_test): ## fit and log model with mlflow.start_run() as run: rf = RandomForestRegressor(max_depth=3, n_estimators=20, random_state=42) rf.fit(X_train, y_train) y_pred = rf.predict(X_test) mlflow.log_metric("test_mse", mean_squared_error(y_test, y_pred)) mlflow.log_metric("test_r2_score", r2_score(y_test, y_pred)) mlflow.register_model( model_uri="runs:/abcdefghijklmnopqrstuvwxyz123456/model", name=model_name ) train_model(X_train, X_test, y_train, y_test)
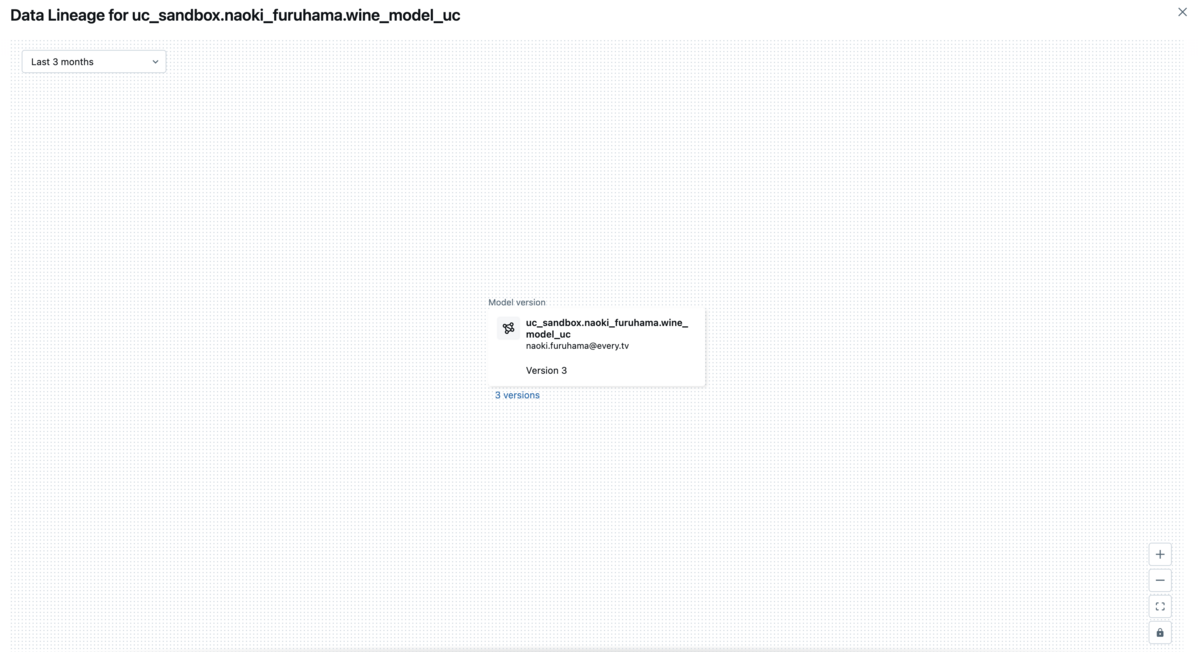
モデルの学習はFeature Storeを使う場合と使わない場合で、FeatureEnginneringClientを使うかmlflowを使うかの違いがあります。
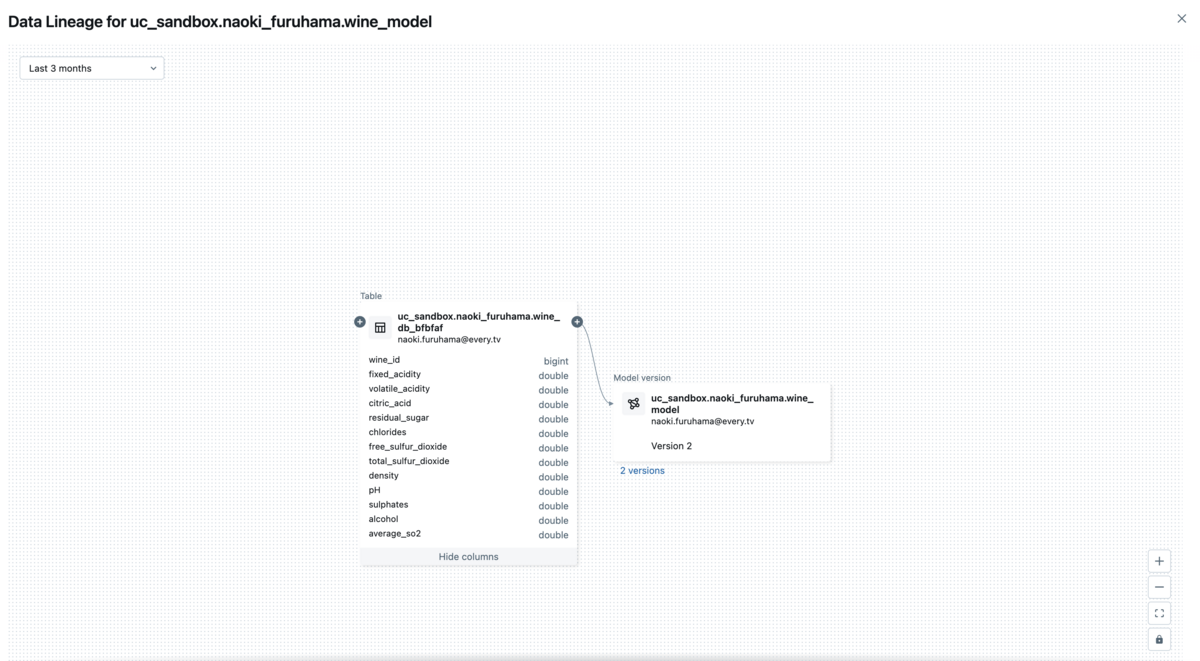
また、Feature Storeを使う場合は、特徴量テーブルとモデルを紐づけるリネージが作成できることが確認できます。
これにより、一目でモデルがどんな特徴量から学習されたかを見ることができ、過去の実験の振り返りをもとにした改善が容易になります。
バッチ推論
登録済みのモデルのうち、最新のモデルを取得する関数を定義します。
# Helper function def get_latest_model_version(model_name): latest_version = 1 mlflow_client = MlflowClient() for mv in mlflow_client.search_model_versions(f"name="{model_name}""): version_int = int(mv.version) if version_int > latest_version: latest_version = version_int return latest_version
Feature Storeを使う場合
## For simplicity, this example uses inference_data_df as input data for prediction batch_input_df = inference_data_df.drop("quality") # Drop the label column latest_model_version = get_latest_model_version(model_name) predictions_df = fe.score_batch( model_uri=f"models:/{model_name}/{latest_model_version}", df=batch_input_df ) display(predictions_df["wine_id", "prediction"])
Feature Storeを使わない場合
batch_input_df = inference_data_df.join(
features_df,
on=["wine_id"],
how="left"
).drop("quality") # Drop the label column
latest_model_version = get_latest_model_version(model_name)
from pyspark.sql.functions import struct, col
# Load model as a Spark UDF. Override result_type if the model does not return double values.
loaded_model = mlflow.pyfunc.spark_udf(
spark,
model_uri=f'models:/wine_model_uc/{latest_model_version}',
result_type='double'
)
# Predict on a Spark DataFrame.
batch_input_df.withColumn("prediction", loaded_model(struct(*map(col, batch_input_df.columns))))
predictions_df = batch_input_df
display(predictions_df["wine_id", "prediction"])
バッチ推論もFeature Storeを使う場合と使わない場合で、FeatureEnginneringClientを使うかmlflowを使うかの違いがあります。Feature Storeを使う場合はfe.score_batchメソッドを使い、使わない場合はmlflow.pyfunc.spark_udfメソッドを使って推論します。
また、大きな違いとして、Feature Storeを使う場合は、推論時に起点となる(primary_keyやlabel等を含んだ)データを渡せば、特徴量をデータとして渡さずに推論することができます。 これは、FeatureEnginneringClientがメタデータをもとに学習時に使用した特徴量を自動的に取得してくれるからだと思われます。
メリット・デメリット
Feature Storeを使う場合と使わない場合で、以下の実装上の比較をしました。
- 特徴量テーブルの作成
- 特徴量テーブルの更新
- 学習データの作成
- モデルの学習
- バッチ推論
では、実際にどのようなメリット・デメリットがあるかまとめます。
メリット
リネージ機能
Feature Storeを使う場合は、特徴量テーブルとモデルを紐づけることができるため、モデルがどんな特徴量から学習されたかを一目で確認できる。特徴量の自動取得
Feature Storeを使う場合は、推論時に起点となるデータを渡せばFeature Storeがよしなに特徴量を参照してくれるため、明示的に特徴量をデータとして渡さずとも推論できる。
デメリット
可読性
FeatureLoopup機能を使った特徴量の結合は、暗黙的にleft joinしてるなど、FeatureEnginneringClientについて理解がないと、どんな処理をしているわからず、可読性が低い。学習コスト
特徴量の自動取得な便利な側面はあるが、上記の可読性のデメリットも含めてFeatureEnginneringClientの書き方に慣れるまでの学習コストがかかる。
振り返り
Databricks側が、Feature Store機能の使用を推奨している理由は冒頭で述べた通りです。
それぞれの観点で、弊社のMLのスモールスタートフェーズにおいてFeature Storeを使う理由があるか考えると、以下のようになりました。
発見性 ◯
特徴量に関しては、Unity Catalog内のDeltaテーブルでもUnity Catalog Explorerでも参照できるため、Feature Storeを使わなくても検索やスキーマ等を確認できる。
対して、Unity Catalog外のDeltaテーブルであれば、上記ができないためFeature Storeを使えると嬉しい。リネージ ◯
Feature Storeを使うことで特徴量テーブルとモデル間でのリネージ機能があるため、Feature Storeを使えると嬉しい。モデルのスコアリングやサービングとの統合 △
モデルのスコアリングに関しては、バッチ推論時に特徴量を自動取得してくれる機能があるため、Feature Storeを使えると嬉しい。
MLのスモールスタートフェーズにおいて、サービングに関してはスコープ外であり、Feature Storeが使えなくてもよい。ポイントインタイムのルックアップ ✗
MLのスモールスタートフェーズにおいて、特定の時点での正確性を必要とする時系列およびイベントベースのユースケースはスコープ外であり、Feature Storeが使えなくてもよい。
所感
個人的なDatabricksのFeature Storeに対する疑問が、今回の検証で解消されました。
特に発見性とリネージに関して、これからML開発を進めていき、たくさんの実験をしていく中で大いに助けになってくれる機能だと感じました。
FeatureEnginneringClientの学習コストや可読性に関して懸念を述べましたが、今回の検証にあたりドキュメントを読み込んでいく中で整理できたかなと思います。
これから新しくMLのモデル開発するメンバーを見据えた整備も順次進めていければなと思います。
Feature Storeを導入することで、MLのモデル開発のagility向上に繋がることは間違いないと感じました。 今実装しているいくつかの特徴量から順にFeature Storeに移行していくことで、Feature Storeの恩恵を受けられるML環境の構築を目指していきたいと思います。