はじめに
今回は Android アプリ開発において、健康に関するデータを一元管理し、他のフィットネスアプリや健康アプリと連携が行える ヘルスコネクト を用いた開発手法についてまとめたいと思います。
なお、以前 iOS のヘルスケアアプリ連携についてもまとめた記事を公開していますので、iOS 側にもご興味があればぜひ こちら の記事もご覧ください。
ヘルスコネクトとは
ヘルスコネクトは API やライブラリではなく一つのアプリで、健康に関するデータを管理できる新しいプラットフォームとなります。
ヘルスコネクトで健康データを一元管理し、その情報を Google Fit などの健康アプリと連携することができるため、ヘルスコネクトに対応している健康アプリであれば複数アプリ間で簡単にデータを同期することができます。
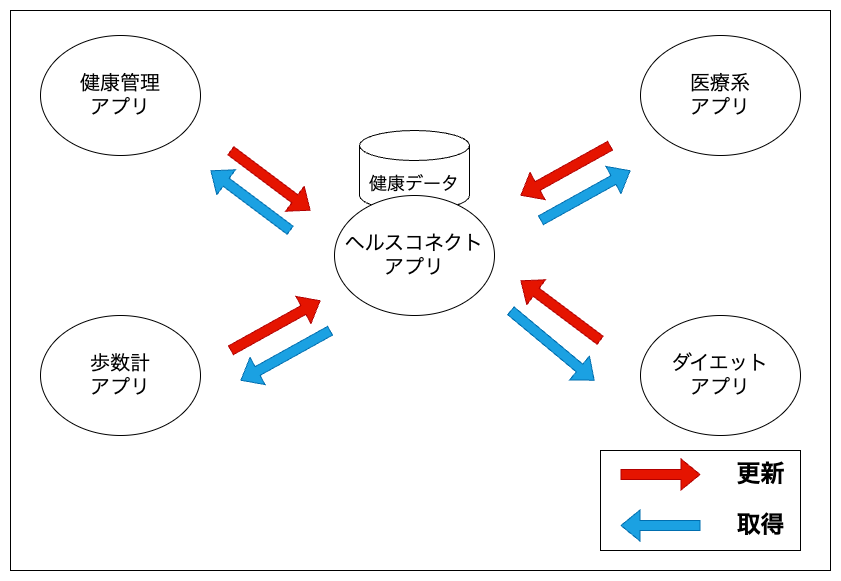
ヘルスコネクトアプリが端末にインストールされることで、実際に健康データにアクセスする Health Connect API とやり取りするための API サーフェスが提供されるため、データの連携が容易となる仕組みとなっています。
ヘルスコネクトアプリ自体は Google がストアに公開しているもので、 こちら からダウンロードできます。
なお、Android OS 14 の端末の場合は標準でヘルスコネクトアプリがインストールされているので、手動でのインストールは不要です。
※2024/3/13 時点ではまだヘルスコネクトアプリはベータ版となりますので、仕様が変更となる可能性があります。
事前準備
端末にヘルスコネクトアプリをインストールしておいてください。
なお、ヘルスコネクトアプリの Android 要件が OS 9 以上となっていますので、OS 9 以上のデバイスを準備してください。
環境構築・実装手順
では早速、環境構築と実装手順についてまとめていきたいと思います。
開発環境
- IDE : Android Studio Iguana | 2023.2.1
- 開発言語 : Kotlin
ライブラリの依存関係を追加
app レベルの build.gradle に以下を追加
dependencies {
implementation "androidx.health.connect:connect-client:1.0.0-alpha11"
}
ヘルスコネクトクライアントの取得設定を追加
AndroidManifest.xml に以下を追加
<manifest
<application
...
</application>
<queries>
<package android:name="com.google.android.apps.healthdata" />
</queries>
</manifest>
取得したい健康データの権限を追加
AndroidManifest.xml に以下を追加します。
<manifest
<!-- 歩数の読み取り、書き込み権限 -->
<uses-permission android:name="android.permission.health.READ_STEPS"/>
<uses-permission android:name="android.permission.health.WRITE_STEPS"/>
<!-- 身長の読み取り、書き込み権限 -->
<uses-permission android:name="android.permission.health.READ_HEIGHT"/>
<uses-permission android:name="android.permission.health.WRITE_HEIGHT"/>
<application
<activity
<!-- 権限をリクエストする Activity に追加 -->
<intent-filter>
<action android:name="androidx.health.ACTION_SHOW_PERMISSIONS_RATIONALE" />
</intent-filter>
</manifest>
uses-permission で読み取り、書き込みをしたい権限を個別に追加、また権限のリクエストを実施する Activity に intent-filter を追加します。
intent-filter を追加することでアプリで権限についての説明画面、及び許可不許可を設定する画面が表示されます。
使用できるデータの型と権限については こちら を参照してください。
ヘルスコネクトアプリがインストールされているかチェック
ここからは実装となります。
健康データにアクセスするためにはヘルスコネクトアプリがインストールされていることが必須のため、インストールチェックを行います。
// インストールされているかチェック
val availabilityStatus =
HealthConnectClient.sdkStatus(requireContext(), "com.google.android.apps.healthdata")
if (availabilityStatus == HealthConnectClient.SDK_UNAVAILABLE) return
// インストール済みの場合は Health Connect Client のインスタンスを生成
val healthConnectClient = HealthConnectClient.getOrCreate(requireContext())
インストールされていない場合は、ヘルスコネクトアプリのダウンロードページに飛ばすなどのケアが必要です。
ユーザに権限のリクエストを実施
アプリが適切に健康情報にアクセスすることを明示するため、権限のリクエストを行います。
// AndroidManifest の uses-permission で宣言した内容と同じものを設定
private val PERMISSIONS =
setOf(
HealthPermission.getReadPermission(StepsRecord::class),
HealthPermission.getWritePermission(StepsRecord::class),
HealthPermission.getReadPermission(HeightRecord::class),
HealthPermission.getWritePermission(HeightRecord::class)
)
private val requestPermissionActivityContract =
PermissionController.createRequestPermissionResultContract()
private val requestPermissions =
registerForActivityResult(requestPermissionActivityContract) { granted ->
if (granted.containsAll(PERMISSIONS)) {
// 全ての権限が許可されたケース
} else {
// 許可されていない権限があるケース
}
}
private suspend fun requestPermission(client: HealthConnectClient) {
val granted = client.permissionController.getGrantedPermissions()
if (granted.containsAll(PERMISSIONS)) {
// 全ての権限が許可されたケース
} else {
requestPermissions.launch(PERMISSIONS)
}
}
リクエストに成功するとアプリ上で以下のような画面が表示されます。

レコードクラスについて
前項で Permission を指定する際に StepsRecord というクラスを使用していますが、こちらが Health Connect API が提供している歩数のレコードデータを取り扱うクラスとなります。
以降の項目でも紹介をしますが、データを書き込み・読み込みする際は StepsRecord に歩数のデータを設定してデータのやり取りを行います。
なお身長のデータについては HeightRecord を使用するなど、データの種別毎にレコードクラスが用意されています。定義されているレコードについては こちら を参照してください。
データを書き込み
実際にヘルスコネクトに歩数のデータを書き込んでみます。
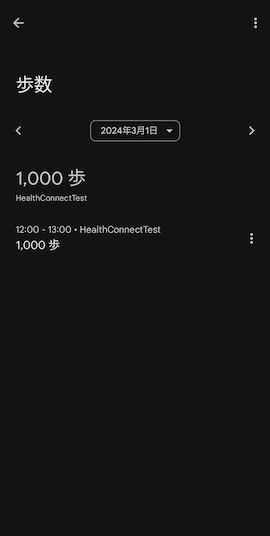
以下は 2024/3/1 12:00 〜13:00 に 1000 歩歩いたという情報を書き込む例です。
private suspend fun writeStep(client: HealthConnectClient) {
try {
val startTime = LocalDateTime.parse("2024-03-01T12:00:00")
val endTime = LocalDateTime.parse("2024-03-01T13:00:00")
val zoneOffset = ZoneOffset.systemDefault().rules.getOffset(Instant.now())
val stepsRecord = StepsRecord(
count = 1000,
startTime = startTime.toInstant(zoneOffset),
endTime = endTime.toInstant(zoneOffset),
startZoneOffset = zoneOffset,
endZoneOffset = zoneOffset,
)
client.insertRecords(listOf(stepsRecord))
} catch (e: Exception) {
// エラーケース
}
}
上記を実行後、実際にヘルスコネクトアプリを確認すると、本アプリから情報が書き込まれたことが確認できます。
健康データを読み取り
次にヘルスコネクトから歩数のデータを読み取ってみます。
以下は先ほどの項目で書き込んだデータを読み取る例です。
private suspend fun readStep(client: HealthConnectClient) {
val startTime = LocalDateTime.parse("2024-03-01T12:00:00")
val endTime = LocalDateTime.parse("2024-03-01T13:00:00")
val zoneOffset = ZoneOffset.systemDefault().rules.getOffset(Instant.now())
val request = ReadRecordsRequest(
recordType = StepsRecord::class,
timeRangeFilter = TimeRangeFilter.between(
startTime.toInstant(zoneOffset),
endTime.toInstant(zoneOffset)
)
)
val response = client.readRecords(request)
response.records.forEach { record ->
Log.d("Health Connect Test", "start time = ${record.startTime.atOffset(zoneOffset)}")
Log.d("Health Connect Test", "end time = ${record.endTime.atOffset(zoneOffset)}")
Log.d("Health Connect Test", "count time = ${record.count}")
}
}
上記を実行すると以下のようにログが出力されるため、先ほど書き込んだデータを取得できたことが確認できます。

環境構築・実装手順の紹介は以上となりますが、非常に簡単な実装だけでヘルスコネクト連携ができることが伝わったのでは、と思います。
おわりに
今回はヘルスコネクトを利用した健康データの連携についてさわりの部分を紹介しましたが、最少の工数で手間なく実装ができました。
ヘルスコネクトが公開される以前は Google Cloud で API を有効にする、認証情報を発行するなど手間が多く、不慣れだと実装の前段階でつまりやすく非常に手間がかかるものでしたが、
ヘルスコネクトを利用すればアプリの実装のみに閉じて開発が行えるため、手間も敷居もかなり下がったものと思います。
以前紹介した iOS のヘルスケア連携同様、両 OS とも簡単に実装ができる基盤が整いつつあるため、これを機に両 OS の開発に触れてみてはいかがでしょうか。
今回紹介した内容が少しでも皆さまのお役に立てれば幸いです。