
はじめに
こんにちは。DELISH KITCHEN開発部の村上です。
直近は社内でAmazon Bedrockを使った RAG基盤の構築をしています。その中でちょうど先月AWSから発表された advanced RAG機能 の中のAdvanced parsing optionsを検証も兼ねて使用する機会があったので紹介します。
Advanced parsing optionsとは
Knowledge baseではS3や他のデータコネクターを指定し、データソースを作成、同期することによってOpensearch ServerlessといったベクトルDBにデータを格納しています。データソースはさまざまなファイル形式をサポートしていますが、今まではサポートしている形式であってもその解析精度に課題が残るものもありました。
今回のアップデートで追加されたAdvanced parsing optionsは有効化することによって、今まで課題であったPDFファイルのテーブルや表、グラフなど非テキスト情報も基盤モデルを使って解析してベクトルDBに埋め込むことができるようになります。
設定可能な値は二つのみでほぼ有効化のみですぐに試すことができます。
- 使用する基盤モデル
- 『Claude 3 Sonnet v1』 or 『Claude 3 Haiku v1 』
- parserの指示プロンプト
- 英語のデフォルトプロンプトが設定済み
長いので折り畳みますが、デフォルトプロンプトはこのように記述されています。
プロンプト内容
Transcribe the text content from an image page and output in Markdown syntax (not code blocks). Follow these steps:
1. Examine the provided page carefully.
2. Identify all elements present in the page, including headers, body text, footnotes, tables, visualizations, captions, and page numbers, etc.
3. Use markdown syntax to format your output:
- Headings: # for main, ## for sections, ### for subsections, etc.
- Lists: * or - for bulleted, 1. 2. 3. for numbered
- Do not repeat yourself
4. If the element is a visualization
- Provide a detailed description in natural language
- Do not transcribe text in the visualization after providing the description
5. If the element is a table
- Create a markdown table, ensuring every row has the same number of columns
- Maintain cell alignment as closely as possible
- Do not split a table into multiple tables
- If a merged cell spans multiple rows or columns, place the text in the top-left cell and output ' ' for other
- Use | for column separators, |-|-| for header row separators
- If a cell has multiple items, list them in separate rows
- If the table contains sub-headers, separate the sub-headers from the headers in another row
6. If the element is a paragraph
- Transcribe each text element precisely as it appears
7. If the element is a header, footer, footnote, page number
- Transcribe each text element precisely as it appears
Output Example:
A bar chart showing annual sales figures, with the y-axis labeled "Sales ($Million)" and the x-axis labeled "Year". The chart has bars for 2018 ($12M), 2019 ($18M), 2020 ($8M), and 2021 ($22M).
Figure 3: This chart shows annual sales in millions. The year 2020 was significantly down due to the COVID-19 pandemic.
# Annual Report
## Financial Highlights
* Revenue: $40M
* Profit: $12M
* EPS: $1.25
| | Year Ended December 31, | |
| | 2021 | 2022 |
|-|-|-|
| Cash provided by (used in): | | |
| Operating activities | $ 46,327 | $ 46,752 |
| Investing activities | (58,154) | (37,601) |
| Financing activities | 6,291 | 9,718 |
Here is the image.
これまでとの挙動の比較
実際にデフォルトの有効化されていない状態と比較しながら、Advanced parsingがどのようにPDFを解析しているのかを確認していきます。 今回はサンプルデータとして情報通信白書令和5年版のPDFをS3に入れて解析を行っています。
以下は使用している設定値です。
- 基盤モデル: Claude 3 Sonnet v1
- parserの指示プロンプト: デフォルト
グラフの解析
まず、p9の棒グラフを解析してみます。

PDFの中のグラフは、デフォルトの設定だと以下のように解析されました。デフォルトでも大きく崩れてはいませんが、それぞれの文字同士のつながりがわかりにくく、ひとつのグラフとして解釈するのは難しいかもしれません。
違法・有害情報センターへの相談件数の推移 0 1,000 2,000 3,000 4,000 5,000 6,000 7,000 平成22 平成23 平成24 平成25 平成26 平成27 平成28 平成29 平成30 令和元 令和2 令和4令和3 (年度) (件) 1,337 1,560 2,386 2,927 3,400 5,200 5,251 5,598 5,085 5,198 5,407 6,329 5,745 (出典)総務省「令和4年度インターネット上の違法・有害情報対応相談業務等請負業務報告書(概要版)」
Advanced parsingだとこのグラフはマークダウン形式で解析され、それぞれの年と数値の関係がわかりやすく表現されています。(※これ以降ではわかりやすく改行コードで改行を入れていますが、実際には一行にまとまっています。)
## 違法・有害情報センターへの相談件数の推移\n | 年度 | 件数 |\n |-|-|\n | 平成22 | 1,337 |\n | 平成23 | 1,560 |\n | 平成24 | 2,386 |\n | 平成25 | 2,927 |\n | 平成26 | 3,400 |\n | 平成27 | 5,200 |\n | 平成28 | 5,251 |\n | 平成29 | 5,598 |\n | 平成30 | 5,085 |\n | 令和元 | 5,198 |\n | 令和2 | 5,407 |\n | 令和3 | 6,329 |\n | 令和4 | 5,745 |\n (出典) 総務省「令和4年度インターネット上の違法・有害情報対応相談業務等請負業務報告書(概要版)」\n
他にシンプルな円グラフでも同じような検証を行いましたが、同じ結果でAdvanced parsingの方がより構造化されて解釈がしやすくなっていました。では、もう少し複雑なものだとどうでしょうか。
こちらはp7にある似たような折れ線グラフですが、先ほどの棒グラフと違い、細かい各年度の数値が書かれていません。

これをデフォルト設定で読み込むと、先ほどと同じくテキストは読み込みますが、大事な中身のグラフに対する内容が抜け落ちてしまっています。
主要プラットフォーマーの売上高の推移 0 100 200 300 400 500 600 (10億ドル) Google Amazon Meta Apple Microsoft Baidu Alibaba Tencent Holdings 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022(年) (出典)Statistaデータを基に作成
一方のAdvanced parsingだとそれぞれの数値が詳細に出されていないことを判断して、無駄なテキスト情報を省き、グラフが示唆する内容を簡単にまとめて解説しています。惜しいのは内容の抜粋になってしまっているので、RAGとして質問した時にそれ以上の回答はできなそうです。ただ、現状はデフォルトプロンプトを使っているので、カスタマイズすることによって精度向上は期待できるかもしれません。
## 主要プラットフォーマーの売上高の推移\n この画像は、主要プラットフォーマー企業の過去10年間の売上高の推移を示すグラフです。縦軸は売上高(10億ドル)、横軸は年を表しています。グラフには、Google、Amazon、Meta、Apple、Microsoft、Baidu、Alibaba、Tencent Holdingsの売上高の推移が示されています。全体的に右肩上がりの傾向が見られ、特にGoogleとAmazonの売上高の伸びが顕著です。\n (出典) Statistaデータを基に作成\n
次にp9にあるよりテキスト情報が多く、それぞれの対応関係を正しく把握しないといけないようなものを見てみます。

デフォルト設定では同じように構造化されていない文字の抽出だけで複雑になった分だけよりわかりにくくなっています。
インターネット上の偽・誤情報への接触頻度 毎日、またはほぼ毎日 最低週1回 月に数回 ほとんどない 頻度はわからない 一度も見たことがない そもそも何がフェイクニュースなのかがわからない 19.1 12.0 16.6 18.6 20.2 2.9 10.7 19.5 19.5 21.7 10.7 22.2 5.0 1.4 令和3年度インターネット上のメディア (SNSやブログなど) 令和3年度まとめサイト
Advanced parsingだと先ほどのようにマークダウン形式で解析され、一見すると綺麗に整ったように感じられます。 しかし、よく見るとそれぞれに対応する数値が違っていたり、欠損が目立っており正しく解析はできていないようで一部はハルシネーションにつながりそうな結果となりました。
## インターネット上の偽・誤情報への接触頻度\n | | 令和3年度インターネット上のメディア(SNSやブログなど) | 令和3年度まとめサイト |\n |-|-|-|\n | 毎日、またはほぼ毎日 | 19.1% | 10.7% |\n | 最低週1回 | 12.0% | 19.5% |\n | 月に数回 | 16.6% | 19.5% |\n | ほとんどない | 18.6% | 21.7% |\n | 頻度はわからない | 20.2% | 10.7% |\n | 一度も見たことがない | 2.9% | 22.2% |\n | そもそも何がフェイクニュースなのかがわからない | | 5.0% |\n | | | 1.4% |\n (出典) 総務省「令和3年版 国内外における偽情報に関する意識調査」
画像の解析
p39の埋め込まれた画像を解析してみます。

デフォルト設定では画像は完全な非テキスト情報となり、その部分だけが情報として抜け落ちてしまいました。
図表2-1-4-1 校務・学習データの可視化(Microsoft) (出典)Microsoft
一方でAdvanced parsingでは、画像内で表現されていることを解析して、説明が加えられています。内容も大きく異なることを言っているわけではなく、かなりいい精度で解析ができています。
## 図表2-1-4-1 校務・学習データの可視化(Microsoft) この図は、Microsoftによる校務・学習データの可視化の概要を示しています。左側には、Microsoft Teamsやアンケート・出欠管理システムなどの学校で利用されるシステムが列挙されています。中央には、これらのシステムから収集されたデータが蓄積されていることが示されています。右側には、蓄積されたデータを可視化し、学校全体、クラス、児童・生徒個人のレベルで分析できることが示されています。
表の解析
p7の表を解析してみます。

デフォルト設定の結果は今までのグラフと同じく、文字の抽出のみです。
プラットフォーマーが取得するデータ項目 データ項目 プラットフォーム Google Facebook Amazon Apple 名前 〇 〇 〇 〇 ユーザー名 - - 〇 - IPアドレス 〇 〇 〇 〇 検索ワード 〇 - 〇 〇 コンテンツの内容 - 〇 - - コンテンツと広告表示の対応関係 〇 〇 - - アクティビティの時間や頻度、期間 〇 〇 - 〇 購買活動 〇 - 〇 - コミュニケーションを行った相手 〇 〇 - - サードパーティーアプリ等でのアクティビティ 〇 - - - 閲覧履歴 購買活動 〇 - 〇 - コミュニケーションを行った相手 〇 〇 - - サードパーティーアプリ等でのアクティビティ 〇 - - - 閲覧履歴 〇 - 〇 - (出典)Security.org「The Data Big Tech Companies Have On You」 より、一部抜粋して作成
Advanced parsingでは、マークダウンでそのまま表形式を表現することでPDFと同じ構造を保てています。
## プラットフォーマーが取得するデータ項目\n | データ項目 | Google | Facebook | Amazon | Apple |\n |-|-|-|-|-|\n | 名前 | ◯ | ◯ | ◯ | ◯ |\n | ユーザー名 | - | - | ◯ | - |\n | IPアドレス | ◯ | ◯ | ◯ | ◯ |\n | 検索ワード | ◯ | - | ◯ | ◯ |\n | コンテンツの内容 | - | ◯ | - | - |\n | コンテンツと広告表示の対応関係 | ◯ | ◯ | - | - |\n | アクティビティの時間や頻度、期間 | ◯ | ◯ | - | ◯ |\n | 購買活動 | ◯ | - | ◯ | - |\n | コミュニケーションを行った相手 | ◯ | ◯ | - | - |\n | サードパーティーアプリ等でのアクティビティ | ◯ | - | - | - |\n | 閲覧履歴 | ◯ | - | ◯ | - |\n (出典) Security.org「The Data Big Tech Companies Have On You」より、一部抜粋して作成\n
テキストの解析
基本的にAdvanced parsingはこれまで述べてきた非テキスト情報の解析が大きな特徴になっていますが、テキスト情報でもどのような影響があるのかを最後にこちらの目次を解析した結果で確認します。
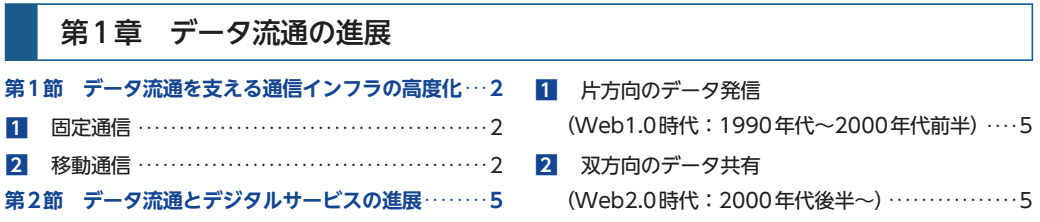
デフォルト設定では、チャンキングの設定により途中で切れてしまっていますが、表示されている通りに抽出を行っているため無駄にトークンを消費していそうです。
第1章 データ流通の進展 第1節 データ流通を支える通信インフラの高度化・・・・2 ■1 固定通信・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・2 ■2 移動通信・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・2 第2節 データ流通とデジタルサービスの進展・・・・・・・・5 ■1 片方向のデータ発信・ (Web1.0時代:1990年代~2000年代前半)・・・・・5 ■2
一方のAdvanced parsingでは書かれている内容を解析して、その意味を失わない範囲でマークダウンに整形しており、無駄がありません。 また、マークダウンで構造も表現できているため、文章の関係もこちらの方がわかりやすいです。
### 第1章 データ流通の進展 #### 第1節 データ流通を支える通信インフラの高度化 * 1 固定通信 * 2 移動通信 #### 第2節 データ流通とデジタルサービスの進展 * 1 片方向のデータ発信 * (Web1.0時代:1990年代~2000年代前半) * 2 双方向のデータ共有 * (Web2.0時代:2000年代後半~)
運用上の注意点
以上のようにAdvanced parsing optionを有効化することによって完璧ではないものの全体の精度の向上が見込めそうなことがわかりました。一方で使っていく中で以下のような注意点があります。
- 基盤モデルで前処理を行う都合上、デフォルト設定よりモデルの利用コストが増加する
- ベクトルDBへの同期処理が遅いため、リアルタイムに文書を処理したい場合に適していない
- デフォルトプロンプトが英語だからなのか、そのままデフォルトで使うと一部の解析結果が英語になってしまう可能性がある
- データサイズ、読み込みファイル数に制限がある
特にフルにこの機能をRAG基盤で活用するにあたって大きな障壁に感じたのは、読み込みファイル数の制限です。現状では解析できるファイルの最大数は100ファイルで申請による調整もできません。工夫したとしてもナレッジベースあたりのデータソース数は5つなので、分割して全て使ったとしても500ファイル程度で上限に達してしまいます。もう一つの解決策としてファイルサイズの上限まで複数のファイルを繋げて、ファイル数を削減することですが、その手間を考えるとAWS側での今後の引き上げを期待したいところです。
まとめ
今回はここ1ヶ月ほどで出たAdvanced parsing optionsを活用したKnowledge baseの精度向上に関して、その挙動を見ていきながら機能を紹介しました。
リリースではこの他にもチャンキング戦略のアップデートやクエリ分割の機能など多くのアップデートがあり、Amazon Bedrockの改善のスピード感とAWSがかなり力を入れていることを日々感じています。現在同じようにRAG基盤を構築されている方はぜひ追加された機能も試してみてください。