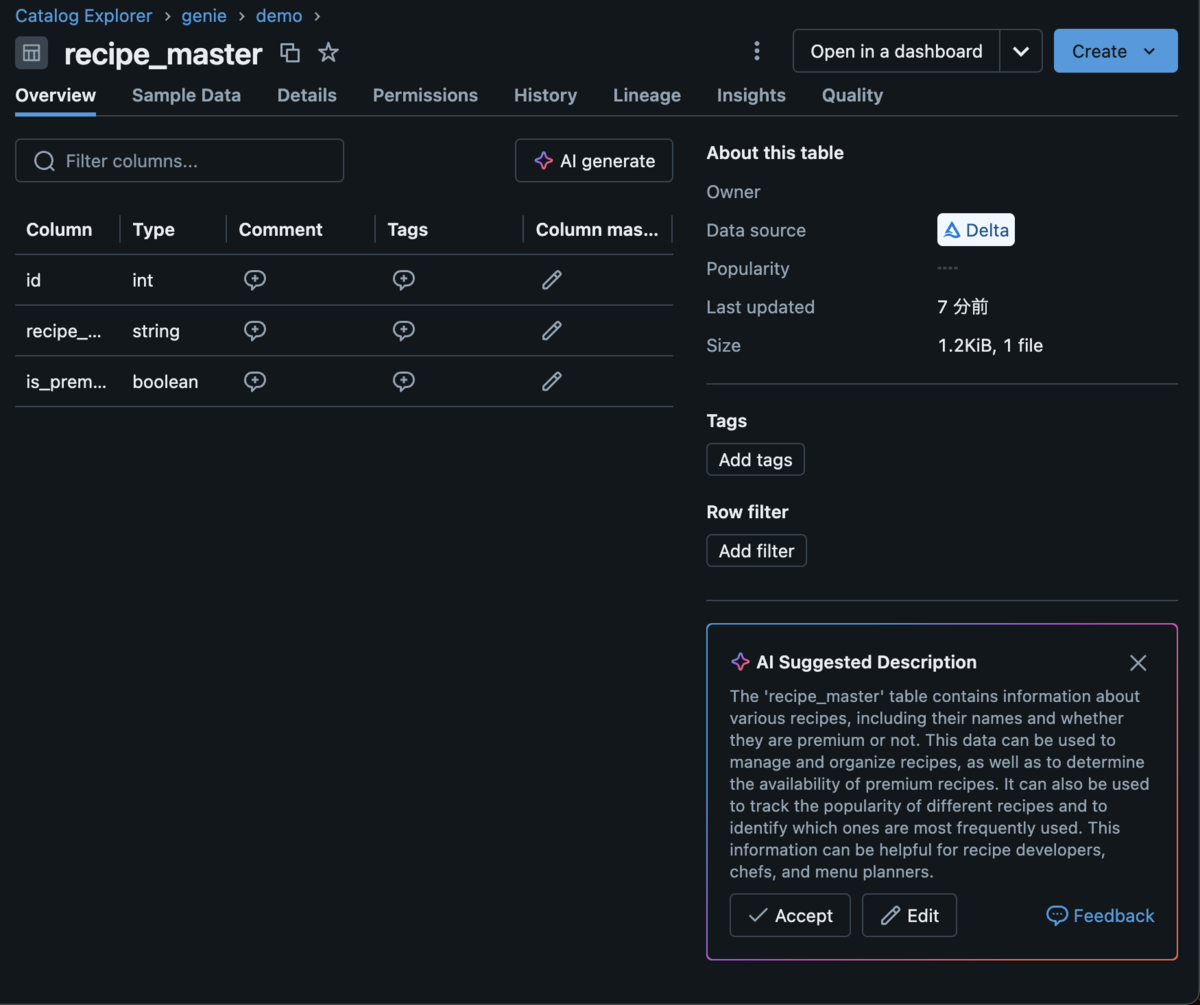
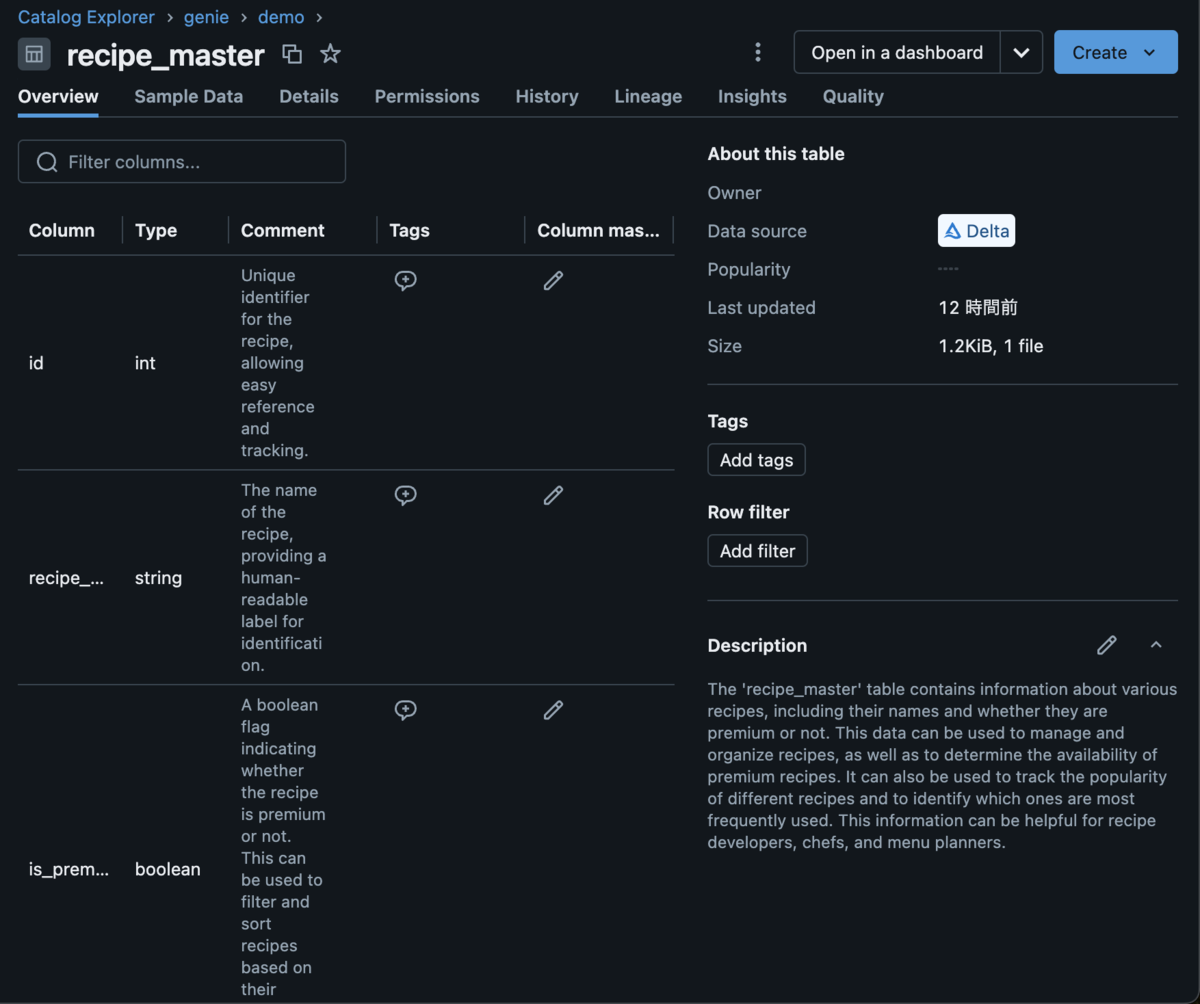
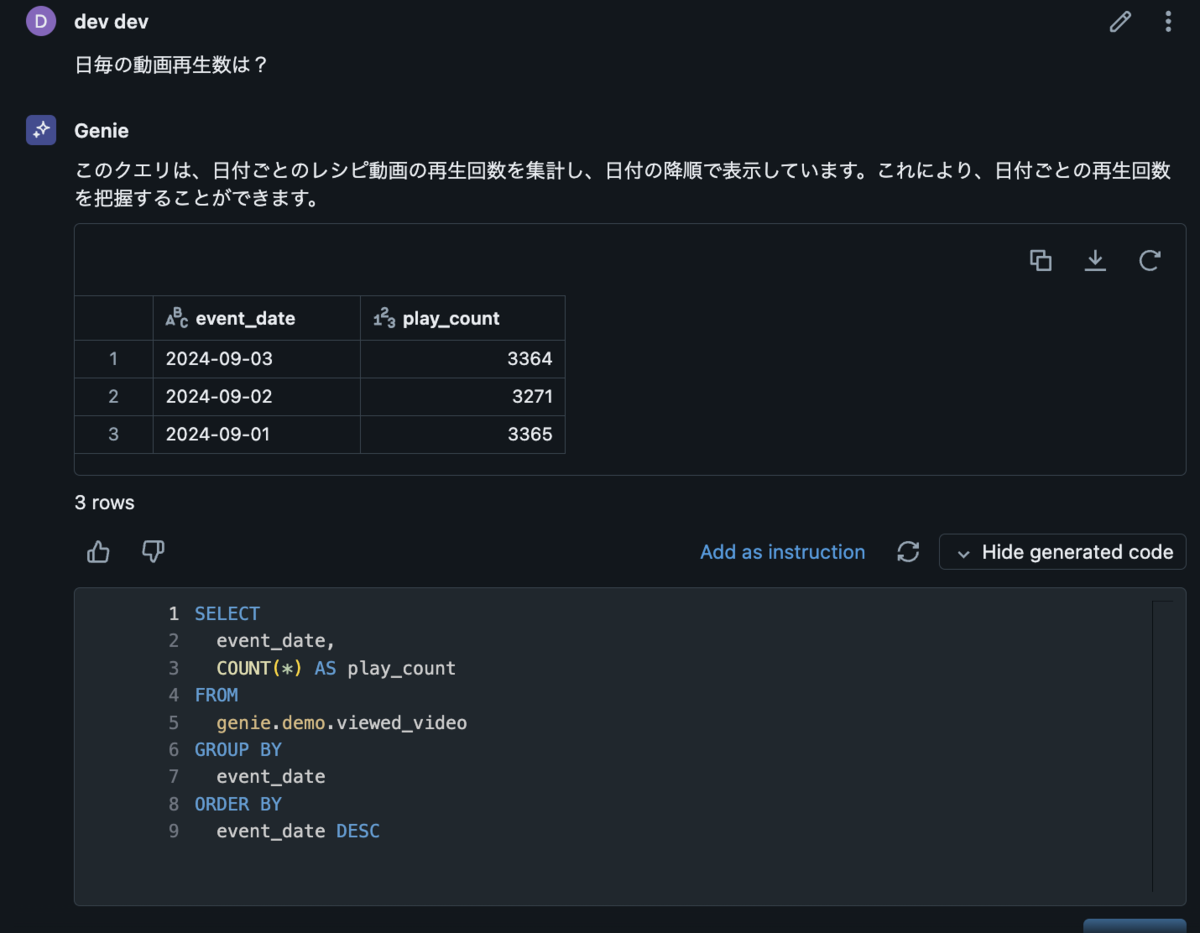
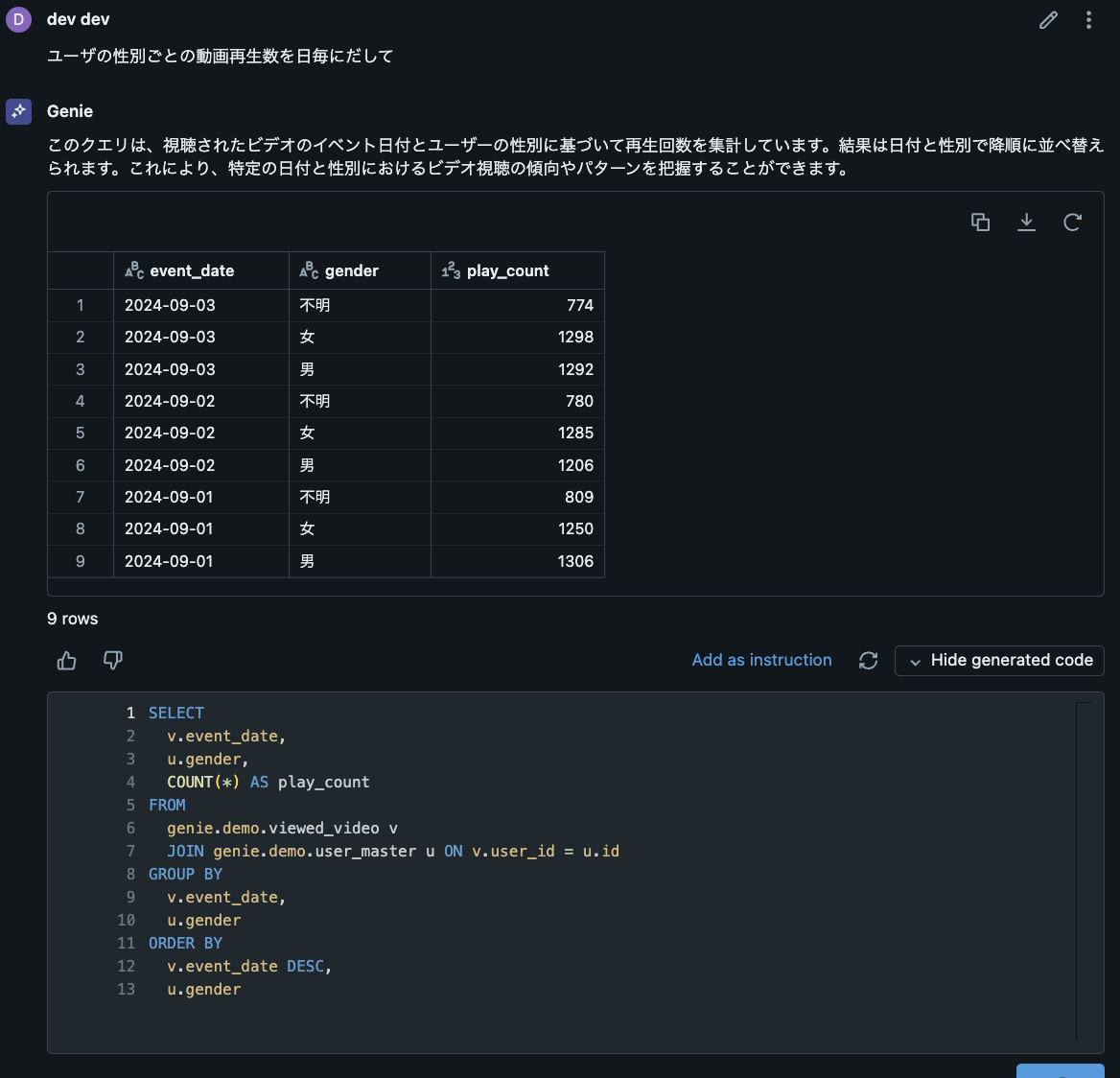
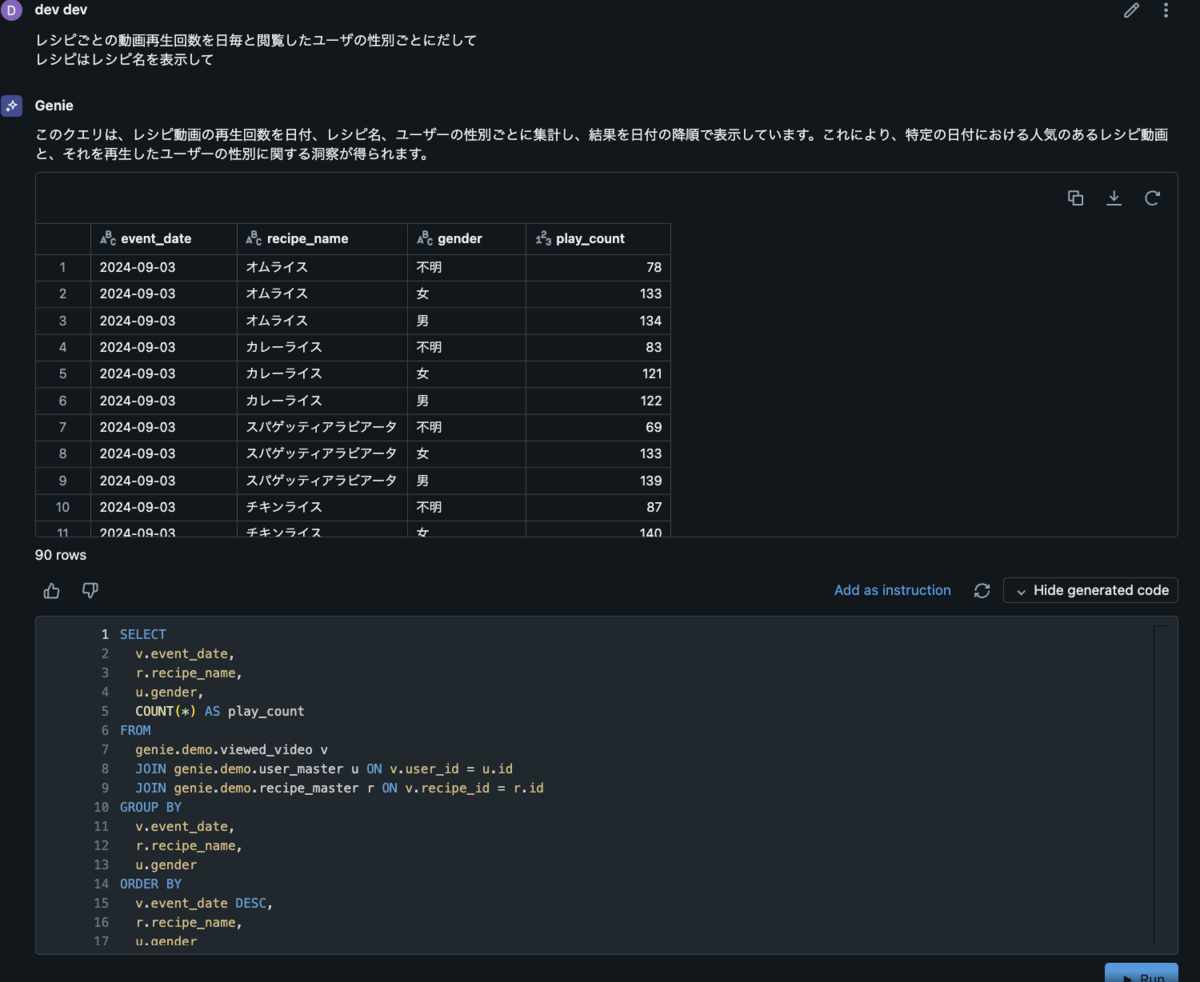
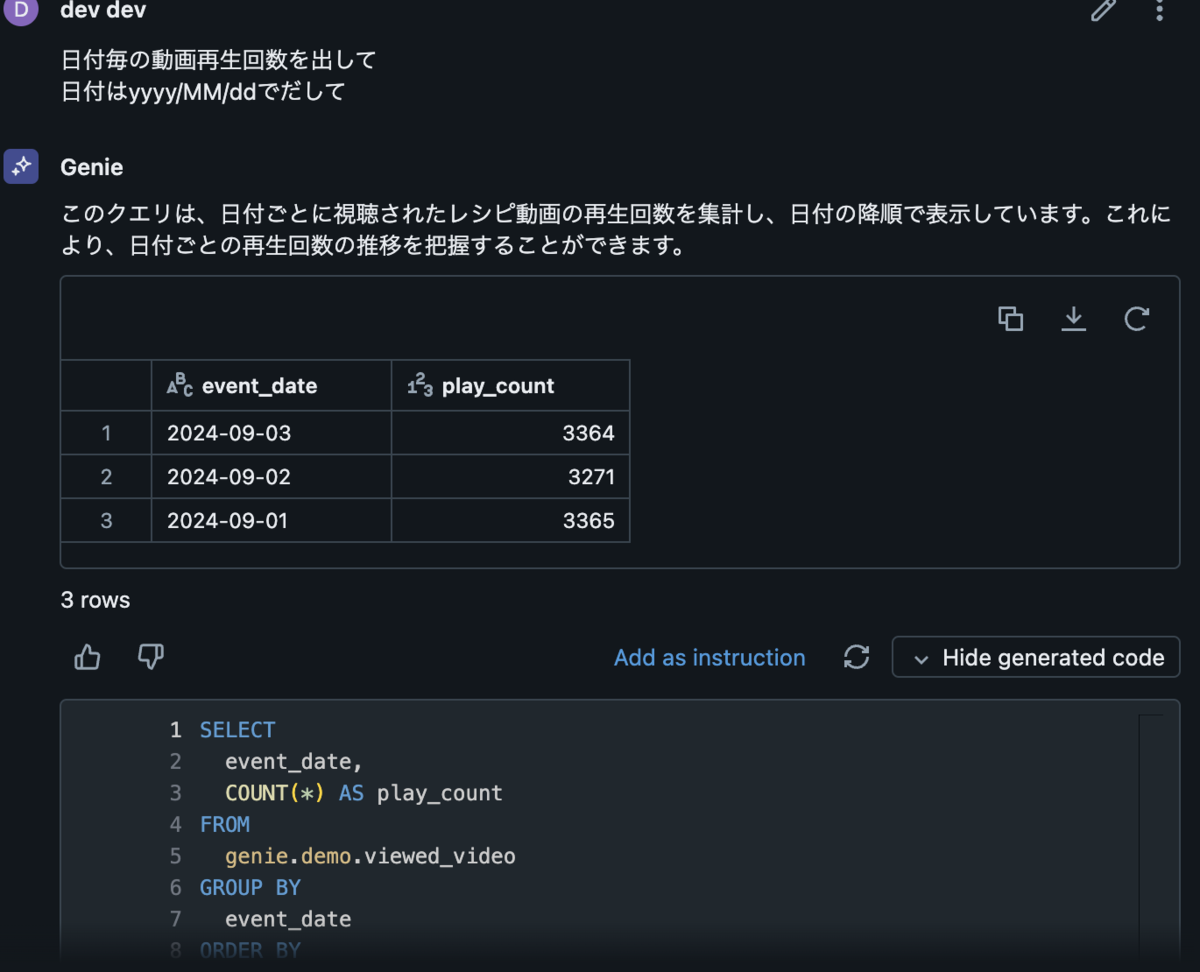
はじめに
こんにちは、DELISH KITCHEN でクライアントエンジニアを担当している kikuchi です。
昨今 AI がますます普及し業務で AI を活用する事例も増えてきましたが、Google が提供している Gemini が Android Studio の一機能として提供されていることをご存知でしょうか?
2024/9/13 時点ではまだプレビュー版ではありますが無料で公開されていますので、今回は実際に使用した際の環境構築手順、使用感などをまとめてみたいと思います。
Gemini の詳細は今回割愛しますが、Gemini は大きく分けて無料版の Gemini、有料版の Gemini Advanced と分かれており、現時点では Android Studio は無料版の Gemini と連動しているようです。
事前準備
Android Studio と Gemini を連携する場合は Google アカウントが必須となりますので、事前に作成をしておいてください。
なお、プレビュー版では Gemini Advanced への加入状況は反映されないため、Gemini Advanced への加入は不要です。
環境構築手順
公式サイト から Canary 版 (2024/9/13 時点では Ladybug) をダウンロードし、Android Studio を起動します
プロジェクトを生成後、右上にある Gemini のアイコンをクリックします
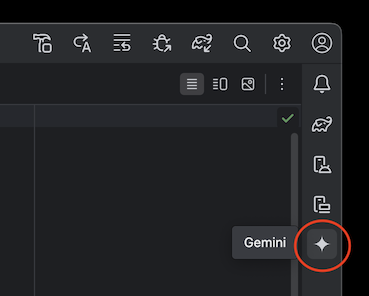
「Log in to Google」をクリックするとブラウザが起動するためブラウザで認証を通し、完了後に「Next」をクリックします
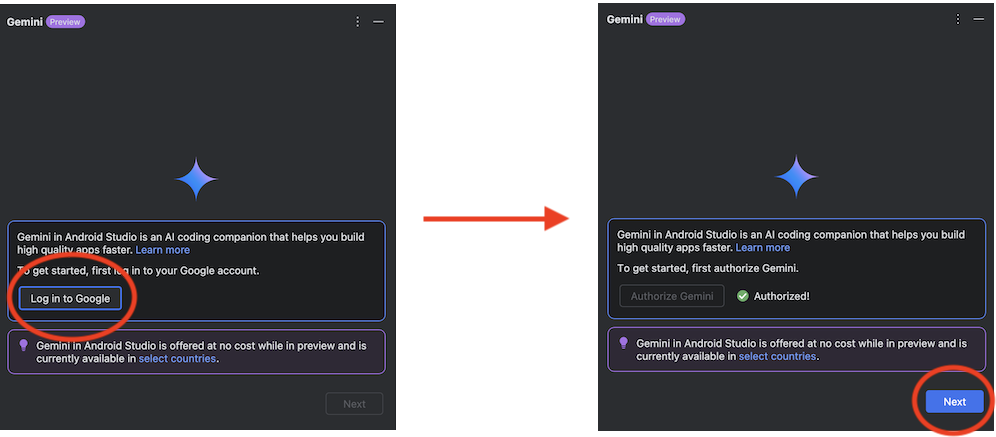
プライバシーポリシーを確認し、「Next」をクリックします
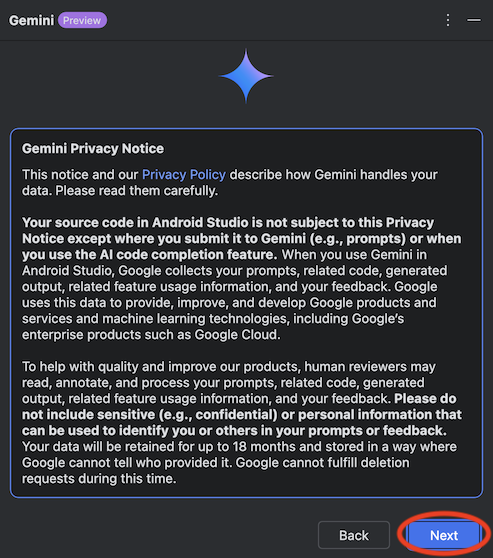
利用規約を確認し、チェックを付けて「Next」をクリックします
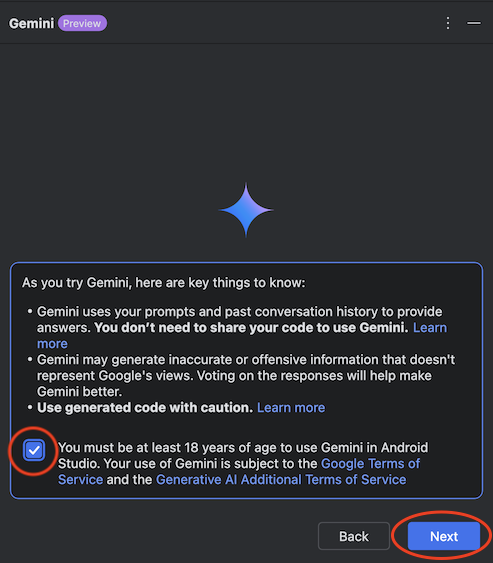
プライバシー設定を確認し、任意の項目にチェックを付けて「Finish」をクリックします
以上で Gemini の機能を使用できる準備が完了しました。
操作方法について
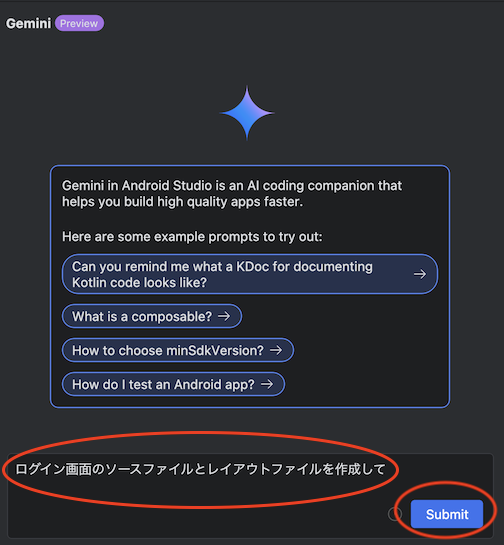
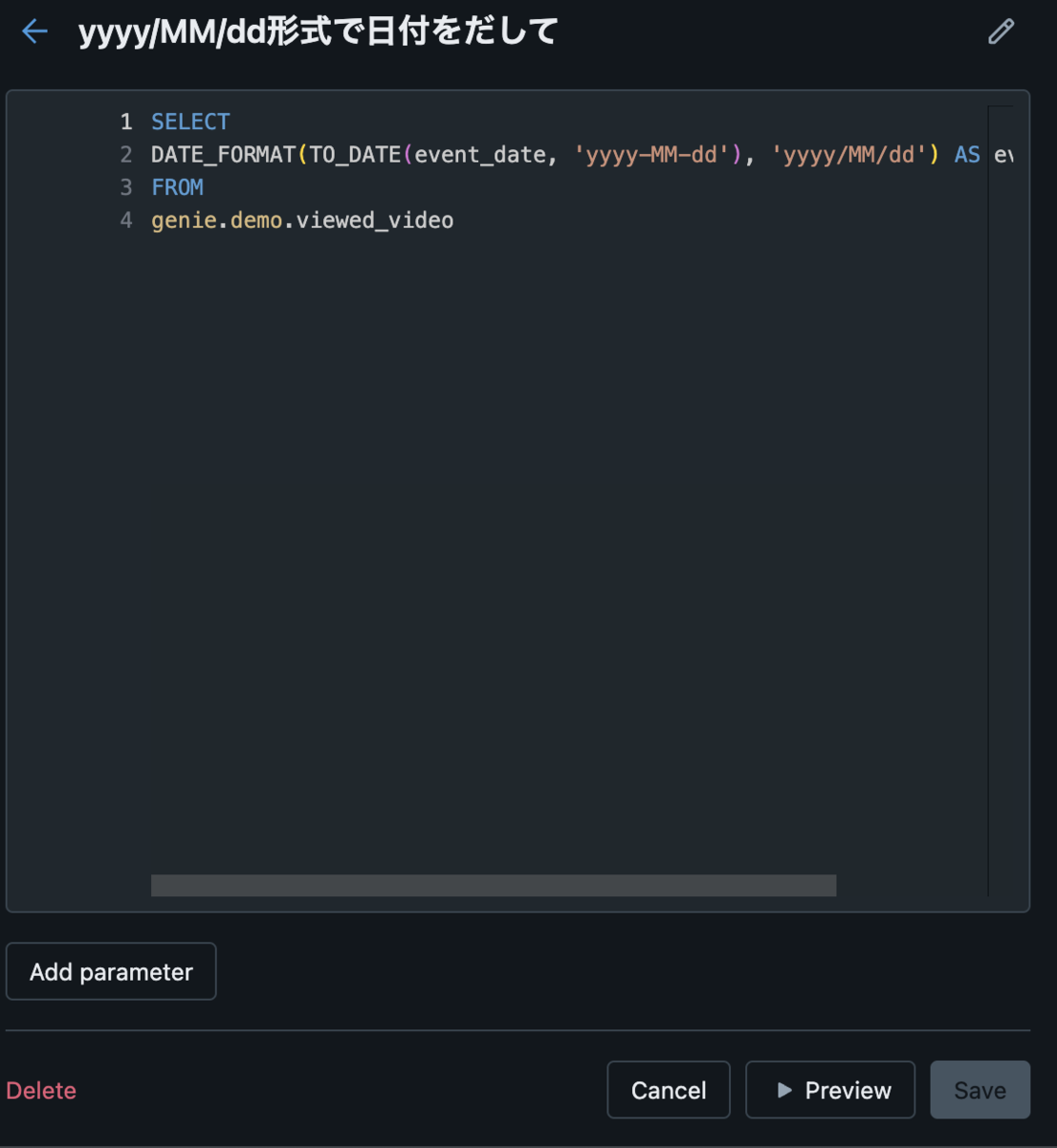
操作方法はコメント入力欄に質問内容を入力し 「Submit」 をクリックすると AI が回答をしてくれるという形で、通常のブラウザ上で操作するものと大きな違いはありません。
以下は 「ログイン画面のソースファイルとレイアウトファイルを作成して」 と質問した時の回答です。
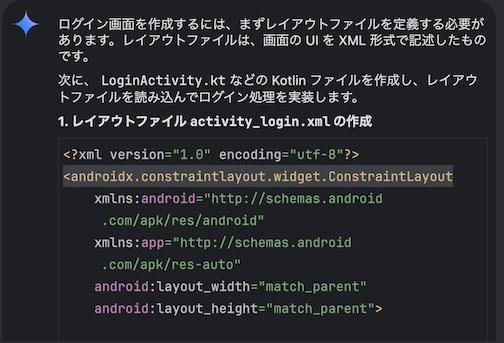
AI のサービスを使用したことがある方は違和感なく使用できるかと思います。
ファイル操作
Android Studio の Gemini では通常のブラウザ上で使用するようなチャット形式でやり取りが出来る点に加え、生成したソースコードに対して特殊な操作が行えるようになります。

上記は実際に Android Studio 上の Gemini で生成したソースコードの直下に表示されるアイコンですが、左から順に
- Copy → ソースコードをコピーする
- Insert at Cursor → カーソルが当たっている箇所に該当のソースを挿入する
- Insert in New Kotlin File → ソースコードを新規ファイルとして生成する (レイアウトファイルの場合はレイアウトファイルとして新規で生成する)
- Explore in Playground → 生成されたコードを Playground 上で確認する
といった操作が行えます。
1、2、4 についてはソースコードのコピーやコピー&ペーストを一括で実施してくれる機能となりますが、3 についてもう少し細かく動きを見てみたいと思います。
Insert in New Kotlin File の実施例
実際に回答結果で出力されたソースファイルの「Insert in New Kotlin File」を実行してみたいと思います。
ファイルを追加したいディレクトリを選択した状態で「Insert in New Kotlin File」のアイコンをクリックします。
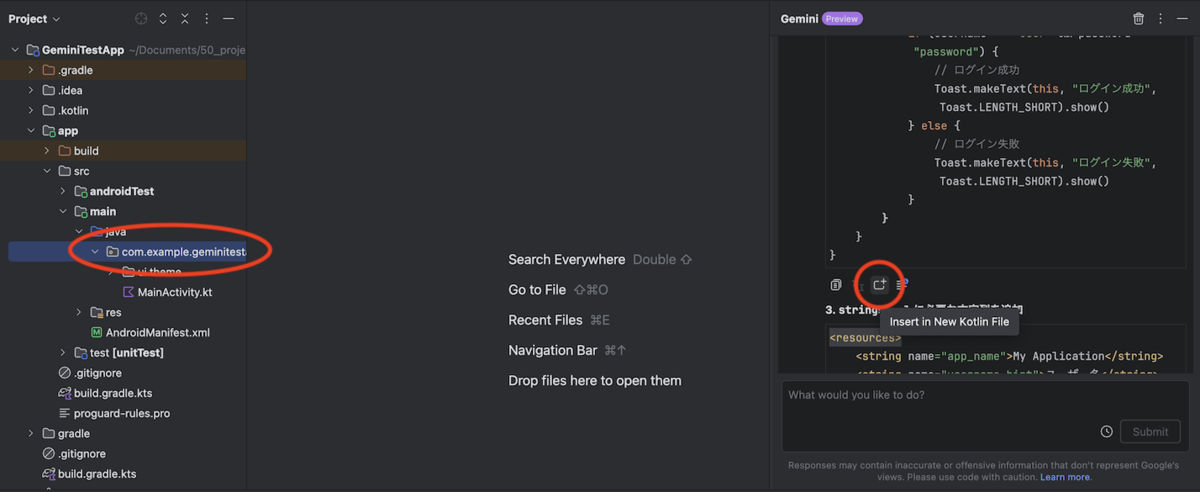
実行後、ファイルが自動的に追加された上、androidx.appcompat:appcompat:1.7.0 のライブラリが不足していることを検知し、追加するかの提案もしてくれます。
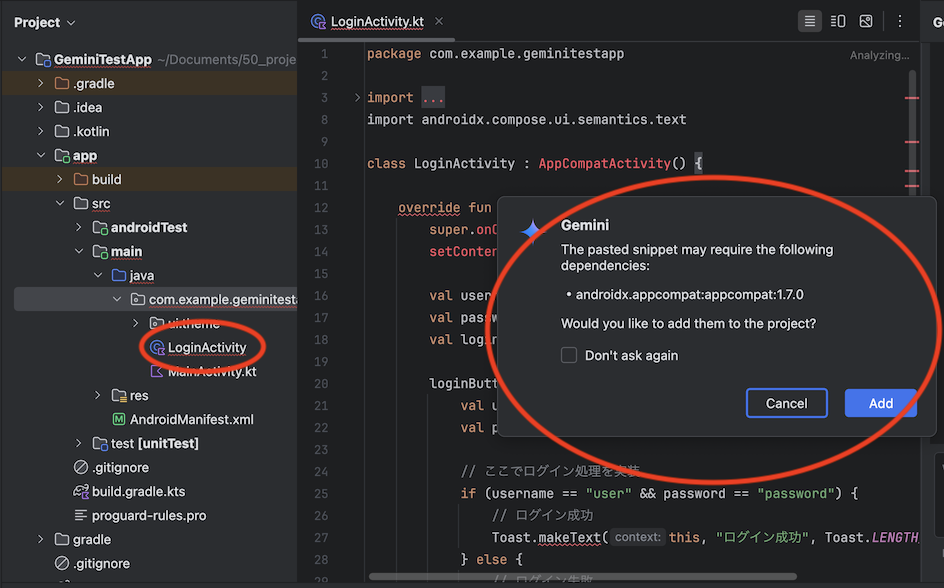
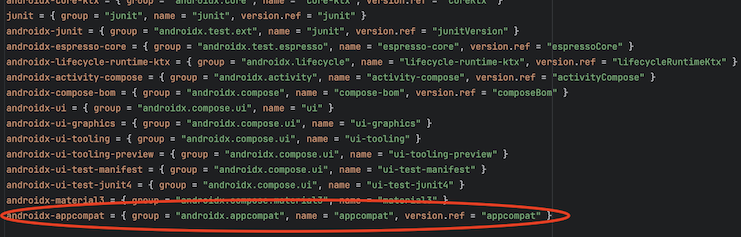
「Add」 をクリックすると build.gradle に追加してくれるだけでなく、Version Catalog でライブラリを管理している場合は libs.versions.toml にも変更を加えてくれます。
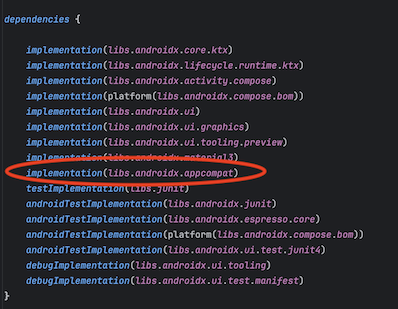
1 つ注意点としては、AndroidManifest.xml には自動的に定義が追加されないため、手動で activity の定義を追加する必要があります。
1 つ手動操作が必要なものの、ソースコードはファイル生成からライブラリの導入までスムーズに行うことが出来ました。
では引き続きレイアウトファイルの生成を行ってみます。
レイアウトファイルの場合はアイコンの説明が「Insert in New Layout File」になるため、そちらのアイコンをクリックします。
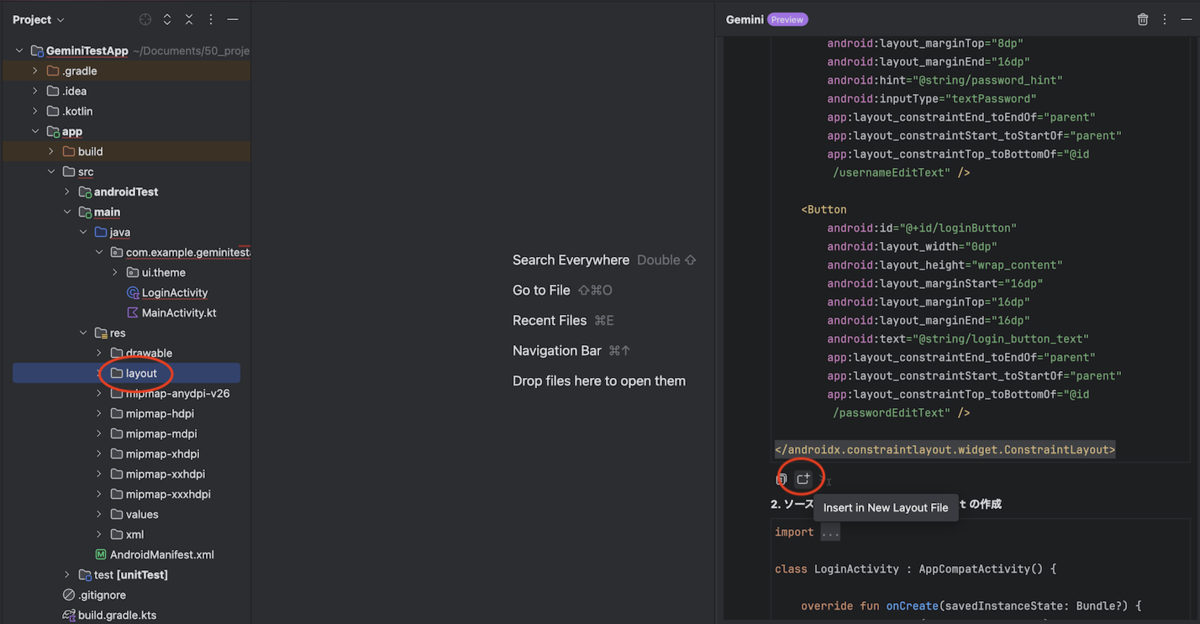
レイアウトファイルの場合はここで 2 つほど問題が発生してしまいます。追加後の状態は以下の画像のようになります。
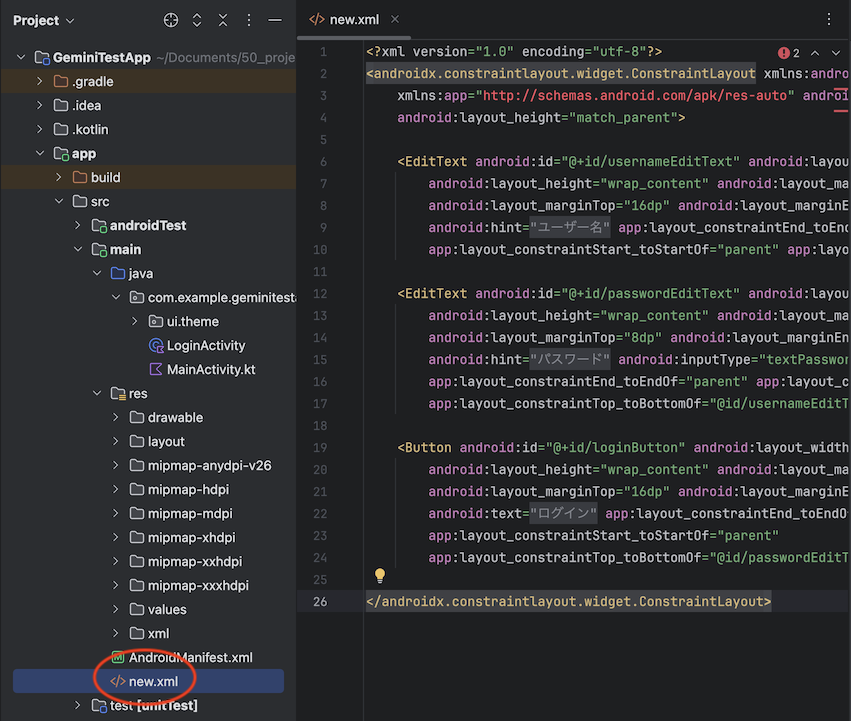
問題の 1 つ目、どのディレクトリを選択していても res ディレクトリ直下に「new.xml」というファイル名で生成されてしまうため、手動でリネームとパス移動が必要になります。
そして 2 つ目、自動生成されたレイアウトファイルは ConstraintLayout を使用していますが、このプロジェクトでは androidx.constraintlayout:constraintlayout のライブラリを設定しておらず、
こちらはソースコードの場合と違ってライブラリが不足していることを検知しませんでした。
レイアウトファイルの自動生成については、手動操作、エラーの解析、ライブラリの追加が必要となってしまいます。
本項でファイルの自動生成を試してみましたが、ソースファイルの生成は容易なものの、レイアウトファイルの生成にはまだまだ課題がありました。
コード補完
前項ではチャット形式でのやり取りについて説明しましたが、実際のソースコードのドキュメント作成や補完を行えるコード補完の機能についても触れたいと思います。
先ほど自動生成したファイルのメソッドで右クリックをすると以下の機能を選択できます。
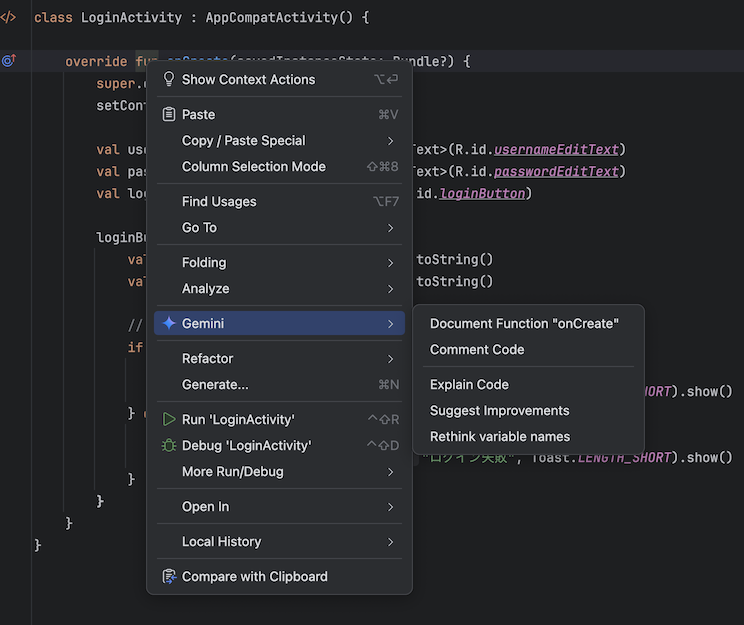
こちらは上から順に
- Document Function "<メソッド名>" → メソッドの KDoc を作成する
- Comment Code → 処理にコメントを付ける
- Explain Code → 処理の解説をする
- Suggest Improvements → 処理の改善案を提示する
- Rethink variable names → 無反応のため不明 (直訳だと変数名の再定義)
となっており、どれも該当のソースコードに特殊なプレフィックスを付けてチャット欄に貼り付けるものでした。
最終的には通常のチャット形式でのやり取りになるため、3 のみ試してみたいと思います。
Explain Code の実施例
実際にメソッドの部分で Explain Code を選択すると以下の警告が表示されます。
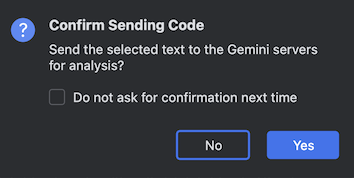
解析のために Gemini のサーバーにソースコードを送信してよいかという質問になります。機密情報を含むソースコードの取り扱いには注意が必要なため、適切な判断をする必要があります。
今回は先程 Gemini で自動生成したソースコードのため、そのまま送信をしてみます。
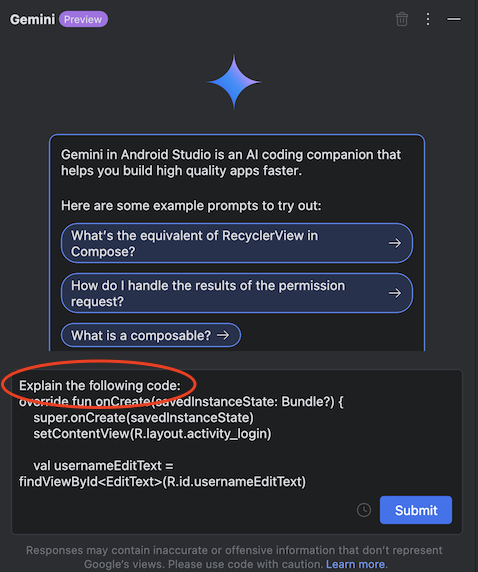
プレフィックスとして Explain the following code: というものが付いて、後は丸々ソースコードがチャット欄に貼り付けられる、という挙動になりました。
あとは「submit」をクリックします。
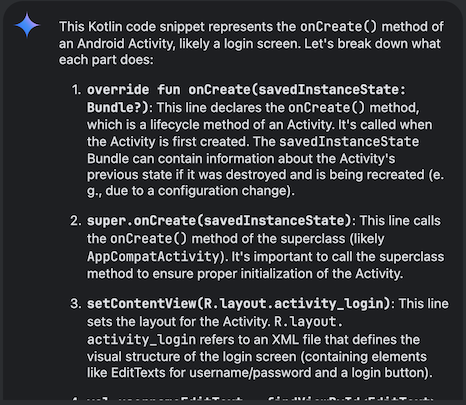
ソースコードの解析結果がチャット欄に出力されました。
こちらはチャット欄で「コードを解析して」といった文章を入力したり、ソースコードをコピー&ペーストする手間を省く効果が期待できそうです。
注意点
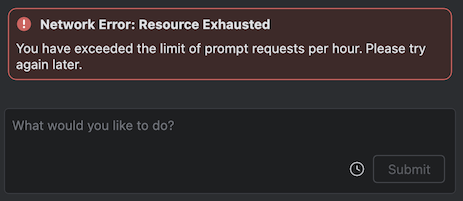
おそらく 1 時間に 10 回程度質問のやり取りをしたところで上限に達してしまいました。1 時間程度待てば再度使用できるようになりましたが、ここは現時点で無料版を使用しているための制限になるかと思います。
実際の使用例
色々と試した中で一番便利に感じたのは、ファイル操作の「Insert at Cursor (カーソルの位置に自動挿入)」と「Insert in New Kotlin File (ファイル自動生成)」を組み合わせて使用する形でした。
具体的な例を記載してみます。
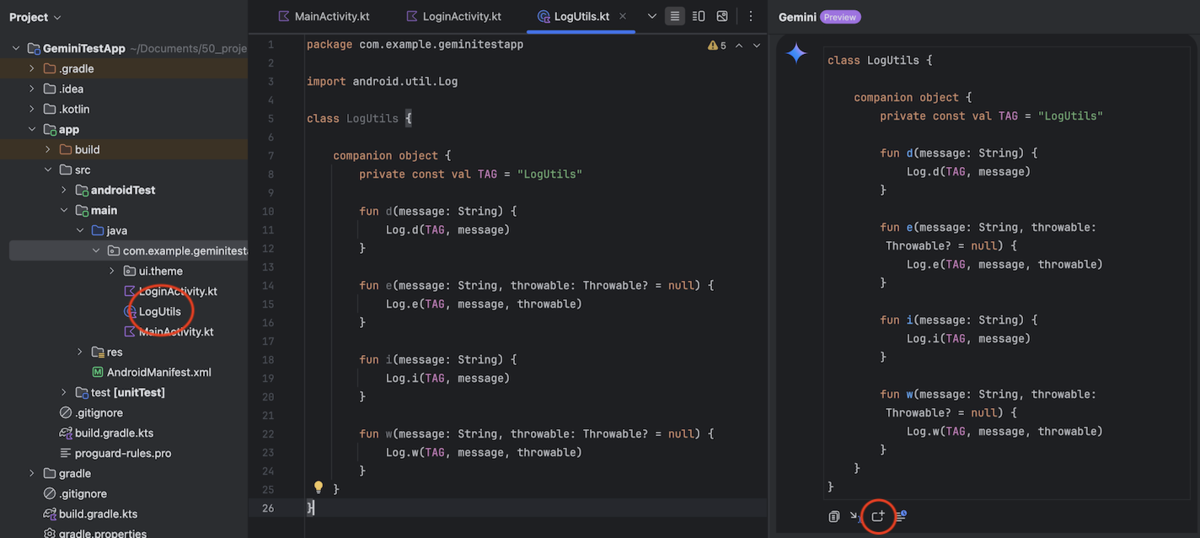
「ログを出力する Utility クラスを作成して」と質問し、出力結果で「Insert in New Kotlin File」を実行しファイルを自動生成する
「verbose のログを出力するメソッドを作成して」と質問し、出力結果で「Insert at Cursor」を実行しクラスを拡張する
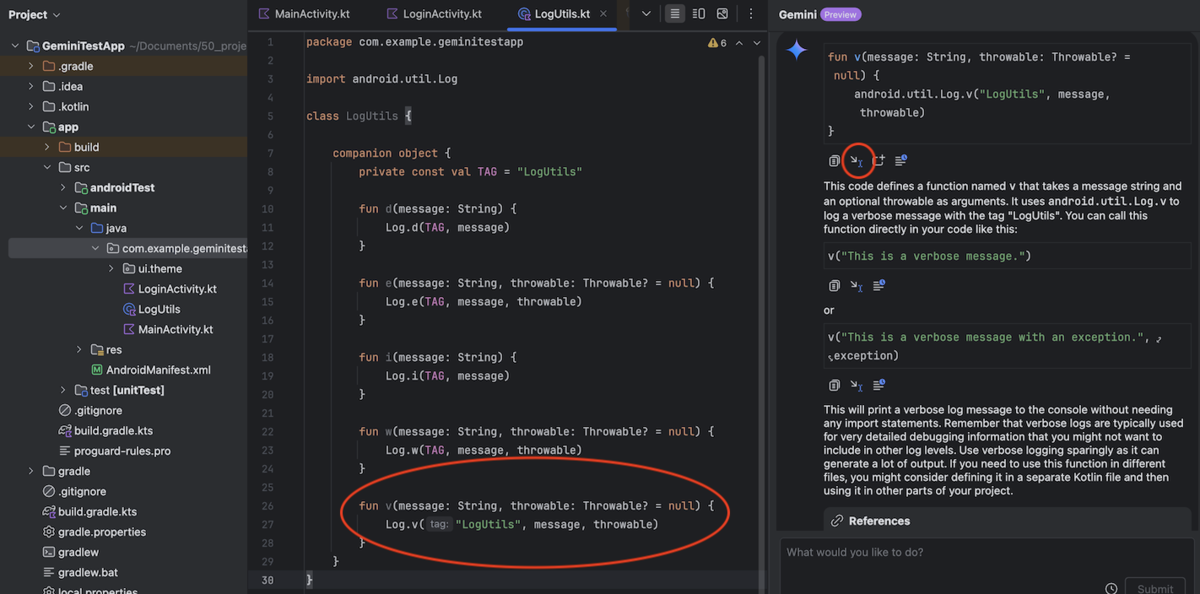
手動で実装することなくチャットによるやり取りのみでクラスの生成、クラスの拡張を行うことが出来ました。
ビジネスロジックを含むようなクラスの生成は難しいかもしれませんが、Utility クラスや data クラスなど単純なメソッドの組み合わせになるようなクラスであればこちらの方が速く実装できる可能性があります。
まとめ
今回 Android Studio の Gemini 機能を使用してみましたが、ブラウザと Android Studio を行き来する手間もなくなり、ファイルの自動生成など Android Studio の操作の手間をかなり軽減し、
また最低限の知識さえあればソースコードをほぼ書かずに実行ができる状態まで作れるため、開発のサポートとしては非常に強力だと感じました。
ただし、前述の通りまだプレビュー版のため、無料版の Gemini を使用していることで回答が返るまでに 10 秒程度かかってしまう点、レイアウトファイルの操作は完全に自動化されていないなど、
まだまだ課題も目立っています。
今後どう改修されていくかは分かりませんが、結局は Android 開発の正しい知識は必須であることには変わりないため、あくまで開発の補助に留めて使用するのがベストかと感じました。
今回紹介した内容が少しでも皆さまのお役に立てれば幸いです。