こんにちは。2023/10/29~11/1に開催された統計・機械学習系の学会、第26回情報論的学習理論ワークショップ(IBIS2023)に、弊社データサイエンティストチームでオンライン参加してきました。
チュートリアルや企画セッションでは、2023年の開催ということもありやはり、昨今盛り上がりを見せているLLMが多くテーマとして取り上げられていました。
様々な研究や活用例がわかりやすくかつ多様に紹介されており、オンラインという形ではあったものの、その勢いや盛り上がりを感じることが出来ました。
本記事ではその中から、気になった講演をいくつか紹介していきます。
チュートリアル: 大規模言語モデル活用技術の最前線
稲葉通将様(電気通信大学 人工知能先端研究センター)
資料: IBIS2023チュートリアル「大規模言語モデル活用技術の最前線」 - Speaker Deck
この講演では、LLMの効果的な「使い方」に焦点を当て、LLMの性能を最大限に活かすための様々な技術や研究が、具体的な精度検証事例も交えつつ紹介されていました。
(数えたら優に10種類以上ありました)
特に印象に残ったものを以下に抜粋します。
Chain-of-Thought(Wei et al., 2022)
- LLMに問題を解かせる際、単に回答を出力させるだけでなく、回答に至る思考過程も述べさせるように、(例示などを交えながら)プロンプトを誘導する手法
- 応用として、同じ指示に対して複数のCoT生成結果を獲得し、それらの結果の多数決を取るアプローチもある(その分コストはかかる)
Let’s think step by step(Kojima et al., 2022)
- プロンプト末尾に「Let’s think step by step.」 を付けるだけでも精度に寄与するというテクニック
- 例示プロンプトの準備に手間がかかるChain-of-Thoughtの代替アプローチ
Tree of Thought(Yao et al., 2023)
- 複数のプランをLLMに生成させ、LLM自身にそれらのプランを評価させる。そして、高い評価のプランをもとにさらに次のプランを複数生成を繰り返すアプローチ
- LLMが不得意になりがちな先読みタスクや、探索が重要なタスクに有効。
感想
まず「Chain-of-Thoughtが上手くいく」のは、日頃プロンプトを試行錯誤しながらGPTとお喋りする中で肌感としてなんとなく感じていたことではあります。
しかし、こうした経験則を研究、データとして裏付けた事例を知ることで、よりそのノウハウを自分の中で体系化出来たと感じます。
また、Let’s think step by stepするだけでも良いプロンプトが狙える、Tree of Thoughtで先回りタスクの苦手さに対処するなど、目から鱗なテクニックも知ることが出来、より活用の幅が広がった気がします。
これらのテクニックを、弊社のLLM活用にも是非とも還元していきたいと感じました。
例えば、
- ビジネスサイドに向けたChatGPT講習資料※をアップデートする(特にLet’s think step by step等の気軽に試せそうなもの)
- 社内AI ChatApp(OpenAI APIのGPTをもとに社内Webツール化したもの)のテンプレートとして、これらのテクニックを埋め込む
等々、日頃のビジネス改善に寄与しそうなタネは多く転がっているのではないかと感じます。
※参考記事
企画セッション: 大規模言語モデルとVision-and-Language
西田光甫様(NTT人間情報研究所)
資料: ⼤規模⾔語モデルとVision-and-Language - Speaker Deck
この講演では、画像処理と自然言語処理の融合領域に焦点が当てられていました。
代表的な基盤モデル(GPT, CLIP等々)の紹介と共に、大規模モデルが如何にして画像と言語の情報を共に扱えるようになっていったのか、その技術の発展や応用例がとてもわかりやすく紹介されていました。
ここでは、特に興味深かったテーマを2つ掘り下げます。
Visual Instruction Tuning
画像×言語情報を扱える大規模モデルLLaVA: Large Language-and-Vision Assistantが、「複雑怪奇な画像のどこにおかしな点があるか」を的確に答える様子が紹介されていました。

Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual Instruction Tuning.
そして、この能力を実現する鍵となったのは、Instruction Tuningの手法を画像処理タスクにも応用したVisual Instruction Tuningでした(Liu et al., 2023)。
Instruction Tuningは、「モデルが人間の指示に従い、未知のNLPタスクを柔軟に解く能力」を得られるように学習させる手法です(Wei et al., 2022)。
これは、ChatGPTにおける指示プロンプト→文章生成をZero-Shotで行う流れに代表されます。
Visual Instruction Tuningでは、画像の情報を文字情報(ex. 画像の内容を説明するキャプション、画像の中にある物体の座標値)に変換します。
そして、このようにして作成した「画像の説明」と、元の「画像特徴ベクトル」の組み合わせをモデルに入力して学習させることにより、LLaVAは画像情報を解析する能力を獲得します。
「画像に説明情報を付加して学習させる」というシンプルな方法により、大規模モデルがまるで視覚を持つかのように多様なタスクに対応できるようになる様に奥深さを感じました。
GPT-4Vの評価論文
2023年9月にChatGPTの画像入力機能として登場したばかりのGPT-4V(GPT-4 with Vision)の潜在的可能性を評価した論文(Yang et al., 2023)の一部が紹介されていました。
ここではGPT-4Vが処理できるタスクとして、以下のような事例が示されていました。
- 指示されたプロンプトに応じて、画像の中にあるや印や注釈などを読みに行き、そこにある情報を取得&活用できる。
- 画像として入力された論文を要約できる。数字や一文程度の誤りはあるものの、それ以外は概ね正確な要約を実現できる。
- 画像のどこに何があるかを物体検出し示せる。しかしその位置座標はまだまだ誤差が大きい。

Yang, Z., Li, L., Lin, K., Wang, J., Lin, C.-C., Liu, Z., & Wang, L. (2023). The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) (Version 2).
これにより、現状どの程度複雑なタスクを処理できる可能性があるかの勘所を掴んだり、逆にどのようなタスクが苦手で課題があるのかを把握したりすることが出来ました。
企画セッション: テキストから実世界理解に向けて
栗田修平様(理化学研究所AIP)
資料: テキストからの実世界理解に向けて - Speaker Deck
画像と言語の対応付けを実世界へどう応用していくのかの研究に関する講演でした。
画像と言語の対応付けには、画像キャプション生成と画像質問応答が2大タスクであるそうです。
これらよりも細かく画像中の物体とテキストを対応付けられないかについて、近年のVision-and-Language領域の研究について紹介していました。
特に参照表現理解というテキスト表現で参照された物体の座標(Bounding Box)を推測する研究分野について詳しく述べられていました。
具体的な手法としては、MDETR(Kamath et al., 2021)とGLIPv2(Zhang et al., 2023)などがあり、MDETRは名詞句に対応づいた画像中の物体を検出するもので、GLIPv2は画像内部の対照学習(MDETR)と他の画像との対照学習(CLIP)を組み合わせた手法だそうです。

講演の後半には、実世界への応用について述べられていました。
参照表現理解は、テキストで参照された物体を画像から探すものですが、これは暗黙的に画像内にその物体が存在することを前提としていると述べられていました。
そのようなケースは確かに実世界だと限定的だなという印象を受け、課題感について納得できました。
この課題解決に向けて、物体が存在しないことも考慮できるようになれば、参照物体が画像内に存在するかの判定機としても動作すると述べられており、非常に興味深いと思いました。
将来的にロボットやドローンによる災害救助などへの応用できれば、非常に有用な技術となりそうだなと感じました。
企画セッション: 作業動画と手順書を対象としたマルチモーダル理解
西村太一様(京都大学大学院 情報学研究科 (現: LINEヤフー株式会社))
資料: 作業動画と手順書を対象としたマルチモーダル理解 - Speaker Deck
動画と言語から学習するVision-and-Language領域で、動画としては作業動画を、言語としては人手で作成した手順書や音声書き起こしを活用した研究に関する講演でした。
この研究では、手順書はノイズが少なく、音声書き起こしはノイズが多いという特性があります。
アノテーションには時間区間のアノテーションと区間ごとの文を付与するといった手法が使われるため、手順書だとデータ量が少なくなり、音声書き起こしだと大規模なデータを学習させることができるそうです。
応用研究として、料理動画からレシピを生成する研究(Nishimura et al., 2022)や、初期状態と最終状態から中間の動作を推定するProcedure planningといった研究(Chang et al., 2020; Sun et al., 2022)を紹介されていました。
弊社でも料理の手順を動画として提供しているため、この講演に大変興味を持ちました。
料理動画からレシピの生成は、ビジネス的観点からどのように活用するのが良いのか、という視点で考えると、弊社の料理動画はPGC(Professional Generated Content)のため、社内のコンテンツ作成チームの効率化が可能かもしれません。
UGC(User Generated Content)観点では、ユーザが動画を撮ってアップロードするだけでレシピを生成して投稿できるといったシステムが作れれば、YouTubeなどと棲み分けができ、新たな価値を生み出せるではないかと感じました。
また、Procedure planningは料理の活用が困難と述べられていましたが、弊社のような動画の画角が固定されていて、手順をトリミング編集したような動画を使うことができれば、うまく学習できるのかという点についても気になりました。
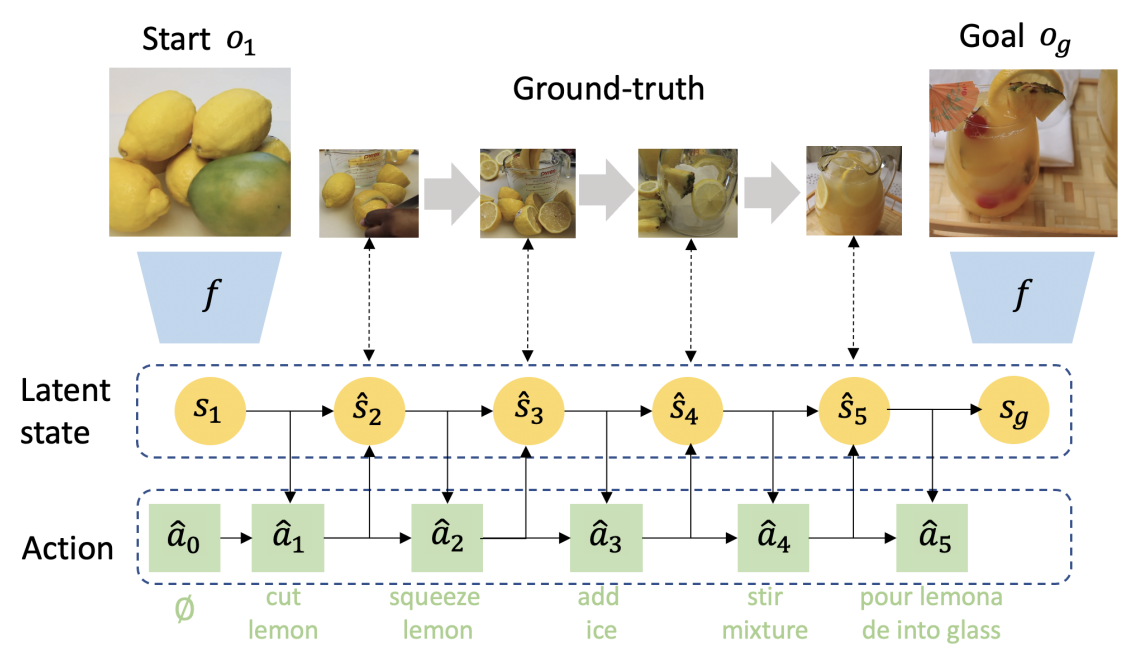
Sun, J., Huang, D., Lu, B., Liu, Y., Zhou, B., & Garg, A. (2022).
PlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks.
最後に
本記事では、「Vision and Languageの最前線」をテーマとした企画セッションを多く取り上げました。
前述した通り、この領域は、弊社が提供する料理動画メディア『DELISH KITCHEN』とも親和性が高いと感じる部分も多々ありました。
これまで、大量に存在している料理動画&画像データ(原石)を如何にして磨くか、ビジネスの発展やプロダクトの成長に活かしていこうか頭を捻らせていたことがありました。しかし、Vision and Language大規模モデルの出現により「視覚的な料理過程の情報と、それに対応する付帯情報(例えば料理手順説明テキストなど)を丸ごと覚えさせ、その文脈を多様なタスクの解決に発展させる」アプローチが現実味を帯びてきた印象を受けます。
こうした技術の発展にアンテナを張りつつ、我々のプロダクトならではの活路を見つけ出していきたいと思います。