
はじめに
こんにちは。 株式会社エブリーの開発本部データ&AIチーム(DAI)でデータエンジニアをしている吉田です。
この記事は every Tech Blog Advent Calendar の13日目の記事になります。
今回は、社内ChatApp向けに作成した、RAG(Retrieval-Augmented Generation)と呼ばれる手法を用いてコードを解説する機能について紹介します。
社内向けChatApp作成の取り組みは こちらの記事で紹介されています。
LLMを利用したコード解説
最近、古くから利用されているロジックの詳細を調査する機会がありました。
しかし、初めて利用するサービスのコードであり、また、初見の言語であることからLLMを利用してコードを解説してもらいながら調査を進めていました。
都度コードをコピペしつつChatAppに解説を依頼していましたが、手間がかかるため、より効率的に利用したいと考えました。
RAGについて
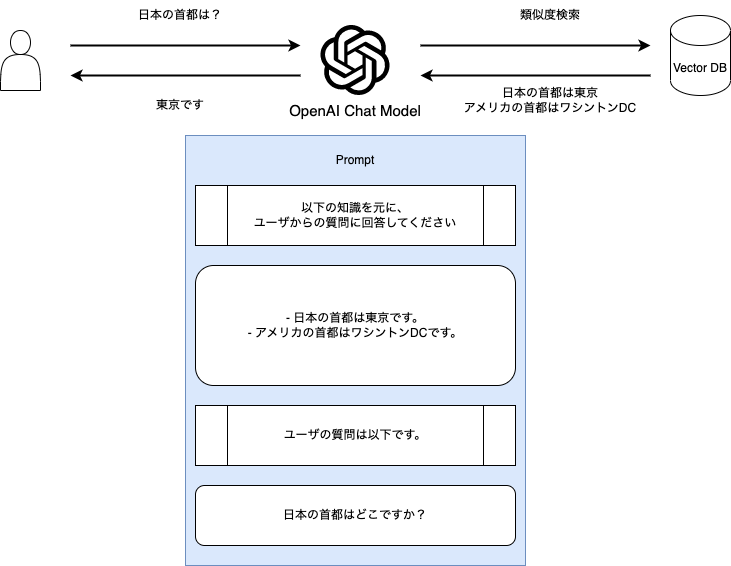
RAGは、ユーザの質問に関連する情報をPromptに入れ込むことで、prompt内の情報を用いて回答を生成する手法です。
LLMに事前に用意した「カンニングペーパー」を渡してあげることで、より正確な回答を生成できます。
RAGは以下のような手順で動作します。
- ユーザが質問を入力する
- 類似する情報を取得する
- 取得した情報をPrompt中に入れ込み、LLMに入力する
- LLMが回答を生成する
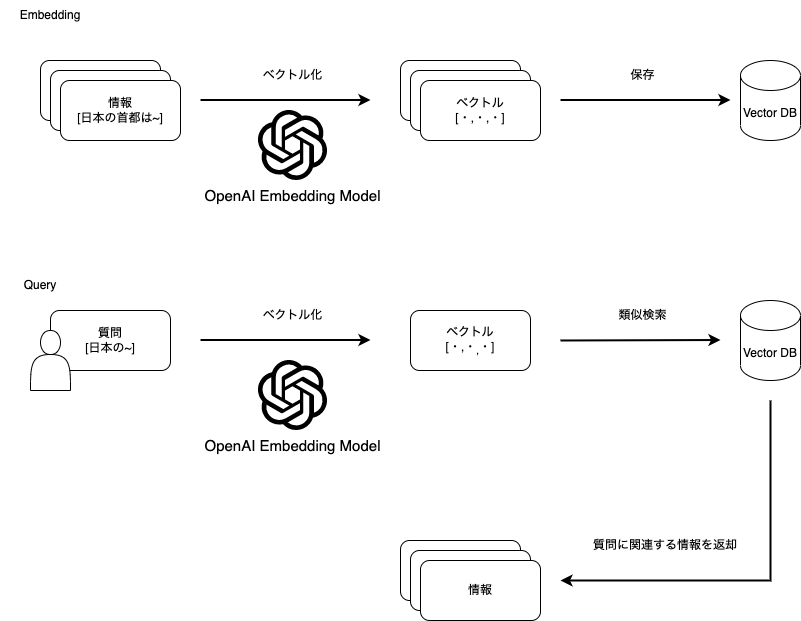
一般的に、事前に情報をベクトル変換したものをVector DBに保存しておき、類似度検索をかけることで質問に関連する情報を取得します。
LLMに対して特定のデータを参照させる場合、
- LLMをFine-tuningさせる方法
- プロンプト中にデータを埋め込む方法
などが挙げられますが、LLMのFine-tuningは大量の計算リソースと時間が必要となるため、コストがかかります。
特に頻繁に更新されるデータを参照させる場合、Fine-tuningを行うたびにコストがかかるため、大きな問題となります。
今回扱うコードは頻繁に更新されるため、Fine-tuningの利用は避けたいと考え、プロンプト中にデータを埋め込む方法であるRAGを採用しました。
コード解説機能構成
今回作成する機能は、利用に必要な労力をなるべく減らすことを目的としてます。
そのため、ユーザが質問を投げかけるだけで、コード解説が実行されるようにします。
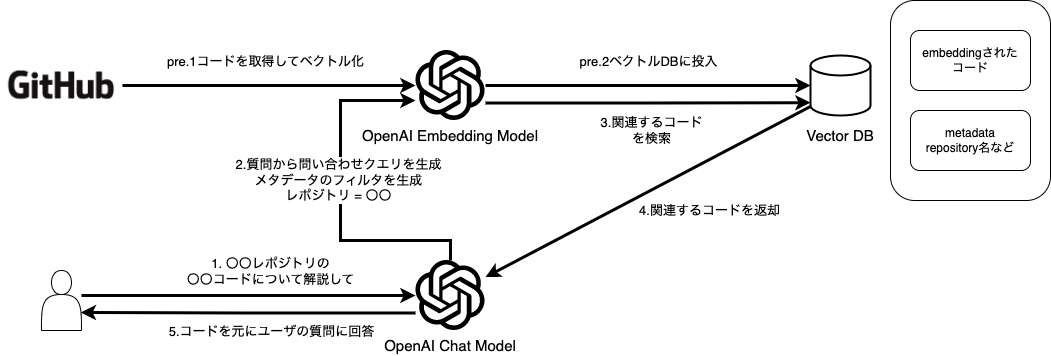
構成として、
- コードのベクトル化部分 (pre.1,2)
- ユーザの質問から関連するコードを取得する部分 (1 ~ 3)
- 取得したコードを元に回答を生成する部分 (4,5)
があり、それぞれ
- GitHubからコードを取得し前処理を行ってからEmbeddingを行いベクトル化し、メタデータとともにVector DBに保存する
- ユーザの質問を元に、Vector DBのメタデータフィルタを生成し、類似するコードを取得する
- 取得したコードとユーザの質問を元に、回答を生成する
といった処理を行います。
今回Vector DBとしてPineconeを利用しました。
また、GitHubからのコード取得、前処理などはそれぞれ
- LlamaIndexの Github Repository Loader
- LangChainの CodeTextSplitter
を利用しました。
Vector DBのMetadata Filteringを利用した検索
Vector DBにはコードのベクトルとともに、
- リポジトリ名
- ブランチ名
- ファイル名
- ファイルパス
といった情報をメタデータとして保存しています。
これは単純にコードのみをEmbeddingした場合、コード中に存在しない情報を検索に利用できないため、ユーザの期待とは異なるコードが返却される可能性があるためです。
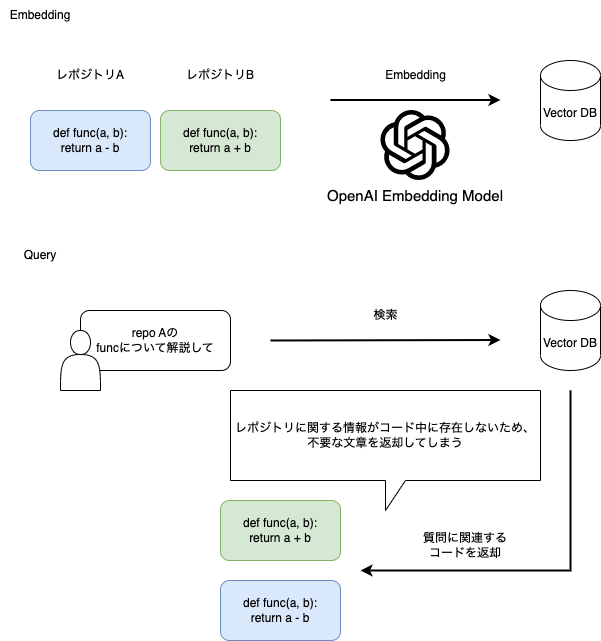
そこで、Vector DBのMetadata Filtering機能を利用することで、より正確な検索結果を返却できるようにします。
https://docs.pinecone.io/docs/metadata-filtering
ただし、ユーザがメタデータを意識することなく利用できるようにしたいため、メタデータフィルタリングの利用を自動化する必要があります。
そこで、メタデータとメタデータの説明がセットになったメタデータカタログを用意しLLMに入力することで、ユーザの質問から利用するメタデータと値を生成させます。
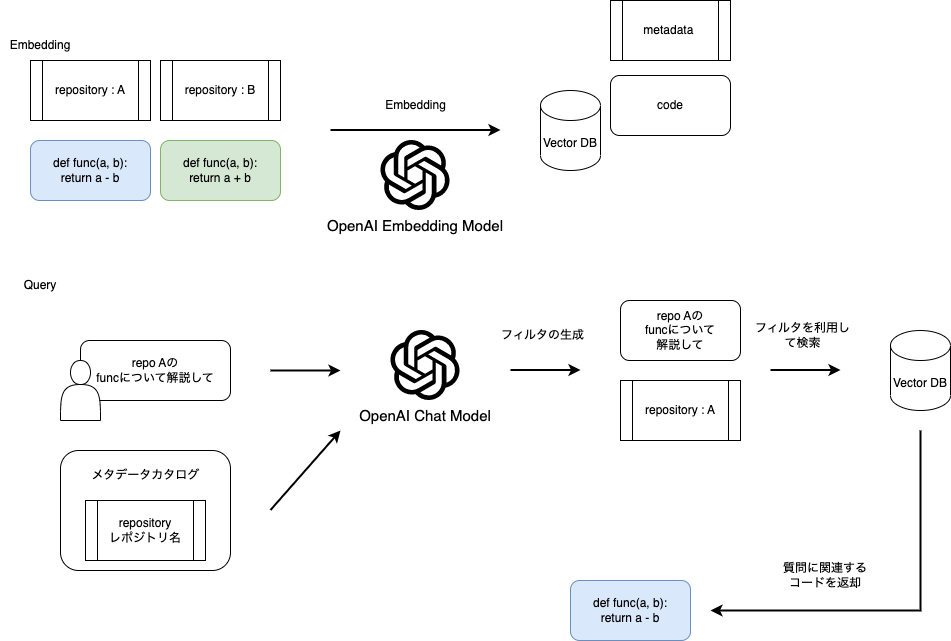
生成された値を元にメタデータフィルタリングを利用することで、ユーザの質問に対するコードをより正確に取得できます。
これにより、hogeレポジトリのfuga.pyのpiyo関数の処理を教えてといった質問を投げるだけで、対象のコードを正確に取得し回答を生成できます。
今回、LangChainの self-querying retriever を利用することで簡単に実装できました。
実験
テストとして簡単なコードを用意し、適切なフィルタリングが行われているかを確認します。
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.chat_models import ChatOpenAI from langchain.chains import ConversationalRetrievalChain from langchain.retrievers.self_query.base import SelfQueryRetriever from langchain.chains.query_constructor.base import AttributeInfo from langchain.schema import Document from langchain.vectorstores import Chroma # ベクターストアの構築 def vectorstore(): # テスト用のドキュメント docs = [ Document( page_content=""" def func(a: int, b: int) -> int: return a + b """, metadata={"repository": "AAA", "filename": "hoge.py"} ), Document( page_content=""" def func(a: int, b: int) -> int: return a - b """, metadata={"repository": "BBB", "filename": "hoge.py"} ), Document( page_content=""" def func(a: int, b: int) -> int: return a * b """, metadata={"repository": "BBB", "filename": "huga.py"} ), ] return Chroma.from_documents(docs, OpenAIEmbeddings()) # メタデータフィルタリングを利用するself-query retrieverの構築 def self_query_retriever(vectorstore): # メタデータカタログ metadata_field_info = [ AttributeInfo( name="filename", description="The filename of the source code", type="string", ), AttributeInfo( name="repository", description="Repository name where source code exists", type="string", ), ] document_content_description = "Source code files collected from multiple repositories" llm = ChatOpenAI(temperature=0, model_name="gpt-4-1106-preview") return SelfQueryRetriever.from_llm( llm, vectorstore, document_content_description, metadata_field_info, verbose=True ) # メタデータフィルタリングを利用しないretrieverの構築 def retriever(vectorstore): return vectorstore.as_retriever() def get_retrieval_chain(retriever): return ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0, model_name="gpt-4-1106-preview"), retriever=retriever, return_source_documents=True, verbose=True) vectorstore = vectorstore() retriever = self_query_retriever(vectorstore) # retriever() or self_query_retriever() qa = get_retrieval_chain(retriever) result = qa({"question": "repository BBBのhoge.pyの関数funcについて解説してください"})
メタデータフィルタリングを利用しない場合
まずは、メタデータフィルタリングを利用せずに、repository BBBのhoge.pyの関数funcについて解説してくださいという質問を投げてみます。
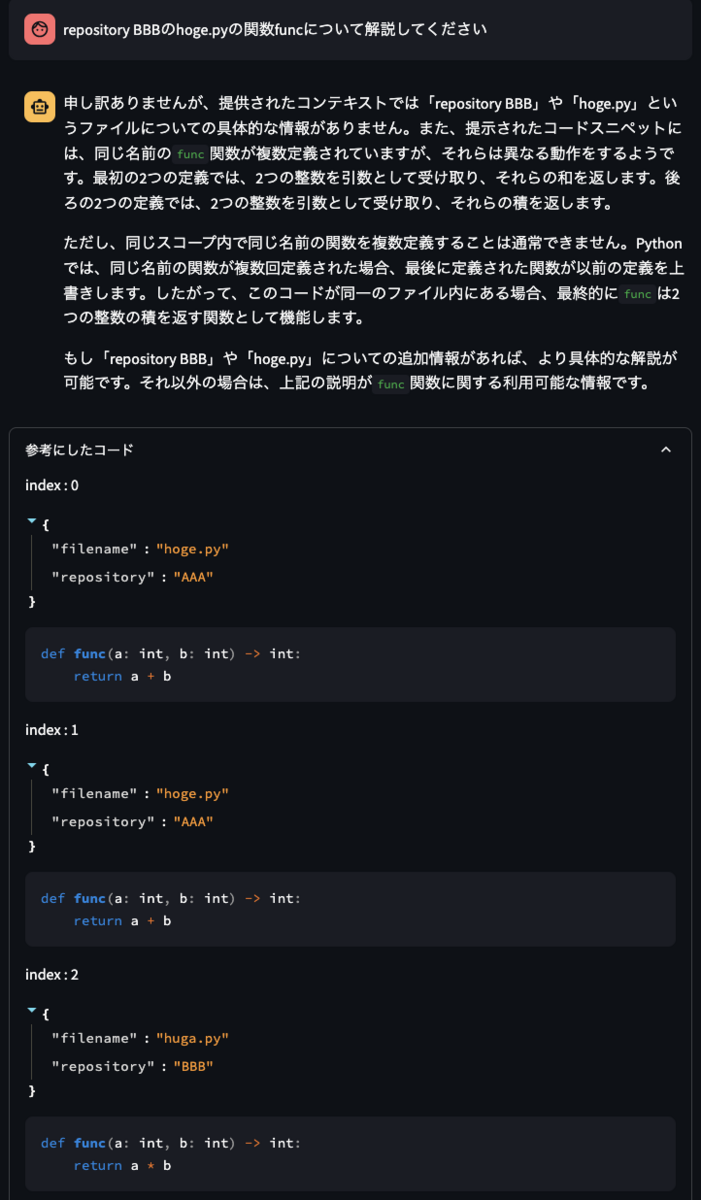
LLMが参照にしたコードの項目を見ると、
- repository BBBのコード以外にもAAAのコードも参照している
- hoge.pyではなくhuga.pyのコードも参照している
といったように、ユーザの質問に対して不適切なコードを参照していることがわかります。
その結果、ユーザが期待する回答を得られませんでした。
メタデータフィルタリングを利用した場合
次に、メタデータフィルタリングを利用して、同様の質問を投げてみます。
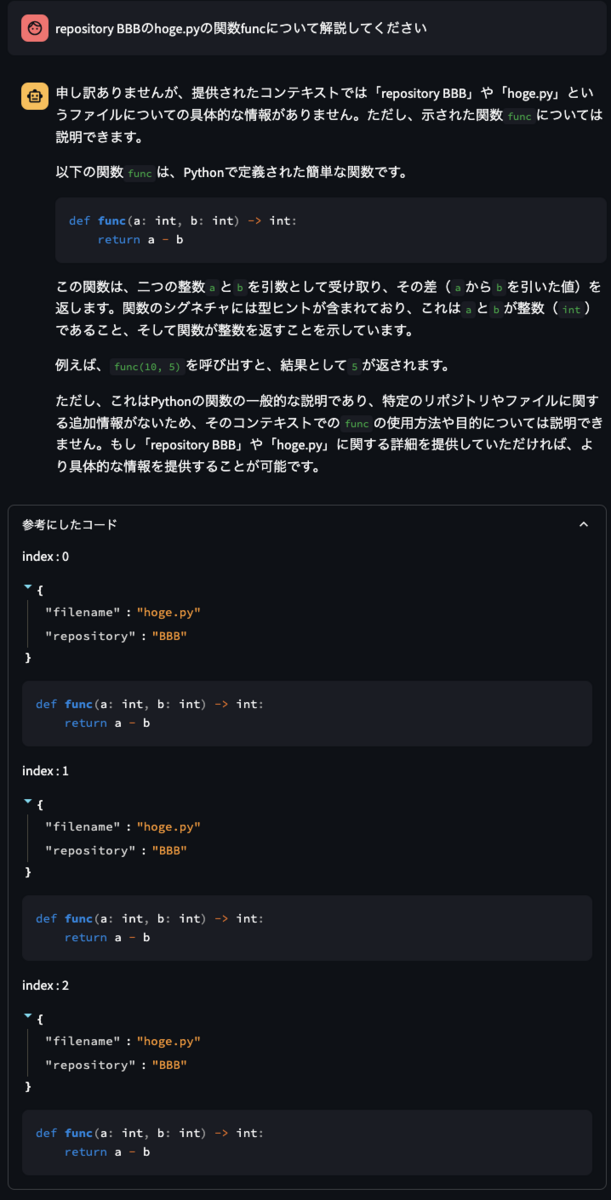
今度は、repository BBBのhoge.pyのみを参照しており、ユーザが期待する回答を得ることができました。
メタデータフィルタリングを適切に利用できない場合
self-query retrieverはLLMがユーザの質問とメタデータカタログを元に利用するメタデータフィルタを自動生成します。
そのため質問の仕方や、メタデータカタログの内容によっては、適切なメタデータフィルタが生成されない可能性があります。
その場合、誤ったドキュメントの参照や、ドキュメントの参照が行われず、適切な回答が得られない可能性があります。
メタデータフィルタの生成精度を向上させるには、self-query retrieverで使用するpromptや、メタデータカタログの内容を調節する必要があります。
終わりに
今回作成した、コード解説機能は社内向けChatAppにβ版としてリリース予定です。
self-query retrieverを利用してメタデータフィルタを自動生成することで、RAGで適切なデータを参照することができるようになり、ユーザが質問を投げるだけでコード解説が行えるようになりました。
今後の取り組みとしては、コードEmbeddingの効率化や最適化、prompt改善による回答精度の向上などを行っていきたいと考えています。