
はじめに
こんにちは!トモニテにて開発を行なっている吉田です。
今回は先日参加した Amazon Bedrock ワークショップに参加させいただいたのでそこで学んだことについて紹介します!
ワークショップは AWS 様からエブリー向けに開催いただきました。

Amazon Bedrock とは
Amazon Bedrock は、高性能な基盤モデル (Foundation Model) の選択肢に加え、生成 AI アプリケーションの構築に必要な幅広い機能を提供する完全マネージド型サービスです。 特徴としては以下が挙げられます。
- ユースケースに最適な基盤モデルを簡単に試すことができる
- 調整や検索拡張生成 (RAG) などの手法を使用してデータに合わせて非公開でカスタマイズ可能
- サーバーレスであるため、インフラストラクチャを管理する必要がない
ワークショップの流れ
当日の流れとしては簡単な自己紹介から始まり AWS の方に今回のテーマである Amazon Bedrock(以下、Bedrock とします) について、Bedrock を利用するにあたり必要となる知識について講義をいただきその後ワークショップ用にご準備いただいたソースを使い各自で使ってみるという流れでした。
その中で学んだ Bedrock とその周辺知識について以下に簡単に紹介します。
Bedrock は、生成 AI アプリケーションの構築に必要な幅広い機能を有していますが、そもそも AI とは、人間のように学習し、理解し、反応し、問題を解決する能力を持つ技術のことを指します。
また基盤モデルとは、大量のデータから学習し、広範な知識と能力を持つ大規模な機械学習モデルのことで、その特徴は、入力プロンプトに基づいて、さまざまな異なるタスクを高い精度で実行できる点にあります。
タスクには、自然言語処理 (NLP)、質問応答、画像分類などがあり、テキストによるセンチメントの分析、画像の分類、傾向の予測などの特定のタスクを実行する従来の機械学習モデルと比べて、基盤モデルはサイズと汎用性で差別化されています。
基盤モデルが可能とすることは以下の通りです。
言語処理
基盤モデルには、自然言語の質問に答える優れた機能があり、プロンプトに応じて短いスクリプトや記事を書く機能さえあります。また、NLP 技術を使用して言語を翻訳することもできます。
視覚的理解
基盤モデルは、特に画像や物理的な物体の識別に関して、コンピュータビジョンに適しています。これらの機能は、自動運転やロボット工学などのアプリケーションで使用される可能性があります。また、入力テキストからの画像の生成、写真やビデオの編集が可能です。
コードの生成
基盤モデルは、自然言語での入力に基づいて、さまざまなプログラミング言語のコンピュータコードを生成できます。基盤モデルを使用してコードを評価およびデバッグすることもできます。
人間中心のエンゲージメント
生成 AI モデルは、人間の入力を使用して学習し、予測を改善します。重要でありながら見過ごされがちな応用例として、これらのモデルが人間の意思決定をサポートできることが挙げられます。潜在的な用途には、臨床診断、意思決定支援システム、分析などがあります。 また、既存の基盤モデルをファインチューニングすることで、新しい AI アプリケーションを開発できます。
音声からテキストへ
基盤モデルは言語を理解するため、さまざまな言語での文字起こしやビデオキャプションなどの音声テキスト変換タスクに使用できます。
一方で基盤モデルが苦手とすることもあります。
- 基盤モデルは大量の GPU を消費する(=コストがかかる)
- 適材適所の基盤モデル利用が重要
- Hallucination
- 嘘の情報を答えてしまう
- プロンプトのトークン数の制限
- プロンプトに含められるトークン数には基盤モデルによって制限がある
- 回答に冪等性がない
- 特定の入力に対して毎回同じ結果を返すとは限らない
(ワークショップ内資料より引用)
これら基盤モデルの苦手ポイントを解決するために有効な手法の一つとして RAG(Retrieval Augmented Generation)が挙げられます。 RAG とは外部の知識ベースから事実を検索して、最新の正確な情報に基づいて大規模言語モデル(LLM)に回答を生成させることができます。 次節では実際に RAG を用いてタスクを実行してみます!
実際に使ってみた
Amazon Bedrock の Knowledge Bases for Amazon Bedrock(以下、Knowledge Bases とします) を使用すると、Bedrock の基盤モデルを、RAG のために企業データに安全に接続することができるとのことで実際に使ってみました!
Knowledge Bases ではデータソースとしてS3を指定し埋め込みモデルを選択します。(今回はAmazon Titan Embeddingsを選択)
そしてベクトルデータベースについては新しいベクトルストアを作成するか、他で作成したベクトルストアがある場合にはそれを設定することもできます。今回は初めての利用ということで新しくベクトルストアを作成しました。
データソースには弊社のサービスであるトモニテで 2023 年 8 月に実施された「トモニテ子育て大賞 2023」と昨年実施の「MAMADAYS 総選挙 2022」の内容を保存しました。(1 つのバケットに 2 つのオブジェクトがある状態です。)
※2023 年 8 月にブランドリニューアルを行ったことから名称が異なっております
関連記事はこちら
tech.every.tv
使ってみた結果がこちらです!
質問内容:mamadays 総選挙、トモニテ子育て大賞それぞれのデカフェ飲料部門の最優秀賞について教えてください
回答:
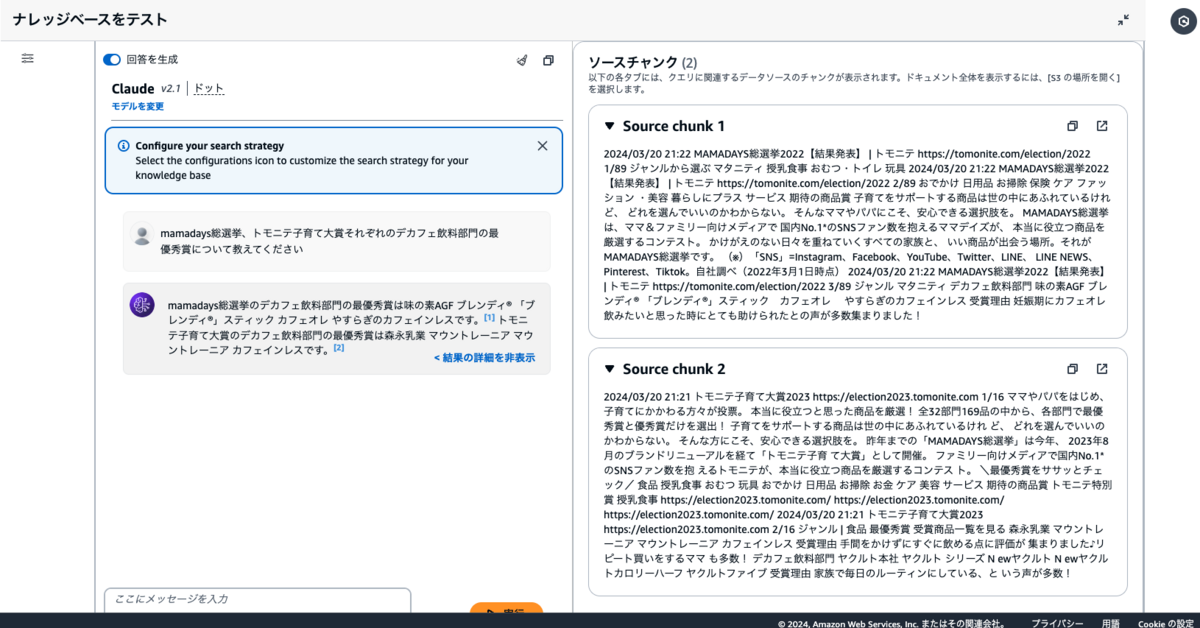 ※Knowledge Bases for Amazon Bedrock 実行結果のスクリーンショット
※Knowledge Bases for Amazon Bedrock 実行結果のスクリーンショット
実際のコンテンツ:(左: MAMADAYS総選挙 2022、右: トモニテ子育て大賞 2023)
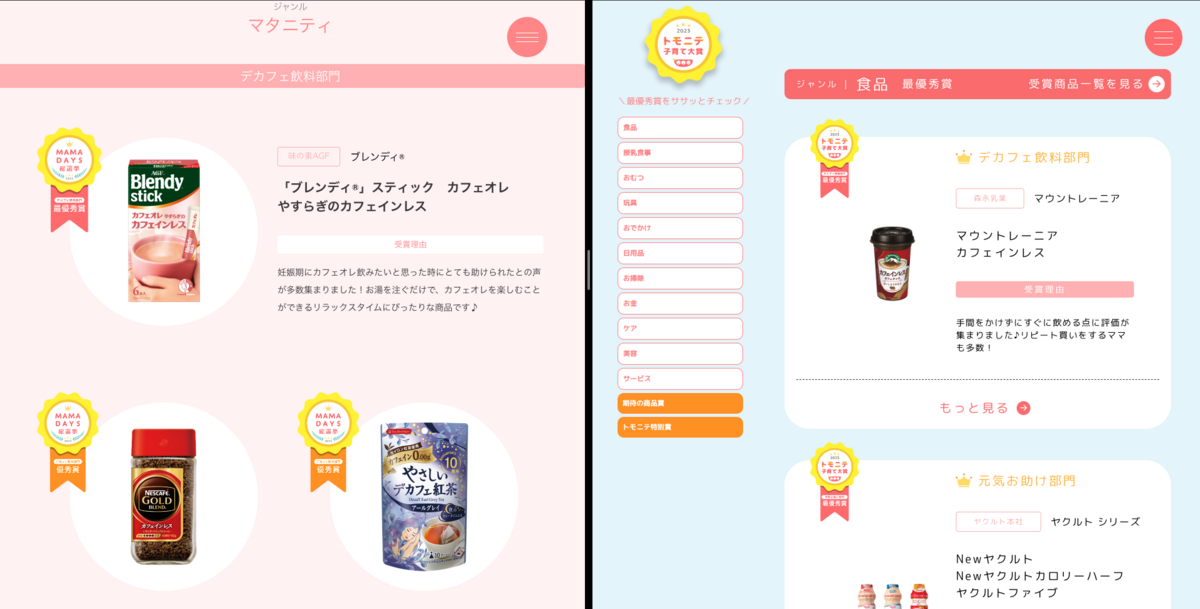 ソースを明示した上で質問に回答しており、2 つのバケットから異なる情報を引き出すことができていました!
ソースを明示した上で質問に回答しており、2 つのバケットから異なる情報を引き出すことができていました!
ただ質問によっては片方の情報のみ回答したり、異なる回答をすることもありましたが今回は web ページをそのまま pdf 化して保存しただけだったのでページ内の情報を適切にテキスト化した上でソースとして保存すればより回答の正確性は向上するのかなと思いました! 現に、ほとんど文字の羅列である企画書をソースとして保存しその内容について回答を求めた場合はほぼほぼ適切な情報を返してくれていました。
ワークショップでの学び
普段は SE として業務に関わっていることもあり AI や機械学習に関わる機会は少ないですが今回のワークショップは Bedrock の深い理解を得ることができ、非常に有意義な時間となりました。学んだことを社内に持ち帰り業務に役立てていきたいと思います。
終わりに
ワークショップの開催にあたり、多くのリソースを提供していただいた AWS の皆様に心から感謝申し上げます。