
はじめに
こんにちは。DELISH KITCHENでデータサイエンティストをやっている山西です。
今回は、挑戦WEEKにて実践したDELISH KITCHENユーザーのクラスター分析事例についてご紹介いたします。
挑戦WEEKとは
「弊社開発メンバーが通常業務から離れ、技術的に何かに集中して挑戦する」という位置付けの1週間です。
詳細はCTOの今井が下記記事にて説明しておりますので、よろしければ併せてご覧ください。
tech.every.tv
本記事の想定読者
- Webサービスの分析従事者(PdM, データサイエンティスト, データアナリスト)
- クラスター分析の実務例に興味がある人
- レシピ提供サービスの分析事例に興味がある人
- サービスが手がけるドメイン知識を活用した分析事例に興味がある人
説明しないこと
- クラスタリングアルゴリズムの統計/機械学習的性質の詳細
- 扱ったデータの具体値に触れるような説明
やったこと
「ユーザーが普段見ているレシピの栄養情報を用いたクラスター分析」を行いました。
出来たもの
普段DELISH KITCHENにアクセスするユーザーを、3つの栄養クラスタ(レシピ嗜好別に分けたグループ)に分類しました。
各栄養クラスタの特徴をまとめたものが下表になります。
| 栄養クラスタ名 | 特徴 | 仮説 |
|---|---|---|
| 主食も取り入れ層 | ・他クラスタに比べて、見ているレシピのカロリーが高い傾向 | ・量としてのボリュームが多いレシピを良く見ている? ・DELISH KITCHENで主食主菜系を積極的に作っている層? |
| 材料メイン層 | ・脂質比率が相対的に高い ・糖質の相対的割合が低いカロリーが特筆して高いわけではない |
・ご飯や麺物はあまり探してないが、付け合わせの主菜とかはよく探している? ・材料ベースで検索する傾向? ・糖質を控えている人も混ざっているかも |
| スイーツトレンド層 | ・他クラスターに比べて、見ているレシピひとつひとつのカロリー低め ・糖質高め, たんぱく質低め |
・お菓子など, 全体量は少ないものの栄養構成としては糖質高めなものが好き? |
ここから、この分析をするに至った動機、および具体の分析の流れを順に紹介していきます。
動機
「DELISH KITCHENという料理動画メディアならでは活かせるデータの価値にあまり向き合えていないな」という課題感が、今回の”挑戦”につながりました。
普段は、機能利用率や継続率等のアプリ内行動指標、プレミアム課金機能の事業成果を測るKPI等、主にWebサービスとしての文脈で分析を行うことが多いです。
その一方で「料理」というコンテンツの肝となる体験に焦点を当て、より解像度高くユーザーニーズに迫るような分析もしてみたいという思いもありました。
そこで今回は「ユーザーが視聴しているレシピの栄養素情報」に着目し、これを探索的に分析して新たな示唆が得られないか実験してみました。
その結果行き着いたのがクラスター分析です。
クラスター分析とは
ここでいうクラスター分析は、データをクラスタリングすることにより、データ内の隠れたパターンや構造に関する示唆を得ることを目的とした分析です。
クラスタリングとは、データを似た特徴を持つグループにまとめる作業です。こうしてまとめられたグループをクラスタと称します。
今回は計6種類の栄養項目(カロリー、たんぱく質、脂質..等)を用いて、ユーザーを「よく似た栄養構成のレシピを視聴する集団」にクラスタリングします。
こうして出来たクラスタを分析により観察することで、新しい知見を得られないか試してみます。
機械学習手法による自動クラスタリングの恩恵
しかし、判断軸が多い&正解が定められていないこの作業を仮に人力で行おうとすると多大な労力が必要となります。
そこで、与えられたデータの中から機械的に法則を見出す(教師無し機械学習をする)ようなクラスタリングアルゴリズムを用いれば、この作業を自動化することが出来ます。
世には様々なアルゴリズムがありますが、今回はその中でも特に広く使用されているK-means法を採用しています。
参考: ITエンジニアのための機械学習理論入門 第6章 k 平均法:教師なし学習のモデルの基礎 | クラウドエース株式会社
分析の流れ
今回の分析の流れの全体像を、図と共に解説します。
概観としては
- 「ユーザーが直近で見ているレシピの平均的な栄養素情報」を集計
- このデータを使って、K-Meansアルゴリズムを用いたクラスタリング(ユーザーのグループ分け)を実施
- 出来たクラスタを観察し、ユーザーのレシピ嗜好に関する示唆を得られないか分析
という流れになります。
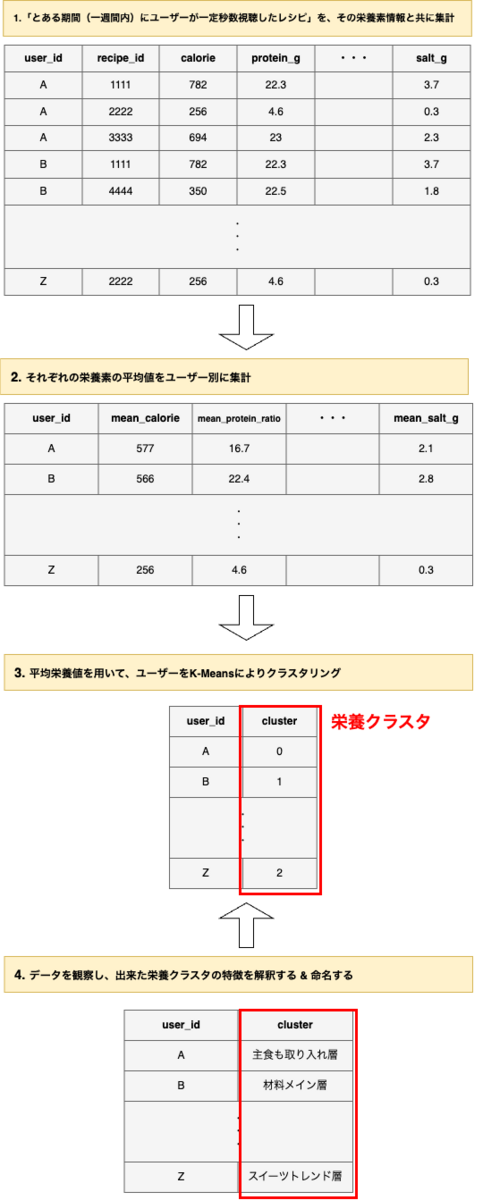
こうして作成したクラスタを以後、栄養クラスタと呼んでいくことにします。
クラスタの観察
ここからがクラスター分析の集大成です。
出来上がった3つのクラスタを定量、定性の観点を組み合わせつつ多角的に観察してみます。
どのように分類されたか
まずは3つの栄養クラスタがどのように分類されたかを、「各クラスタのユーザーが視聴するレシピの平均栄養値」で可視化します。
※ この時点ではまだクラスタに名前が無いため、0,1,2の番号で識別します。
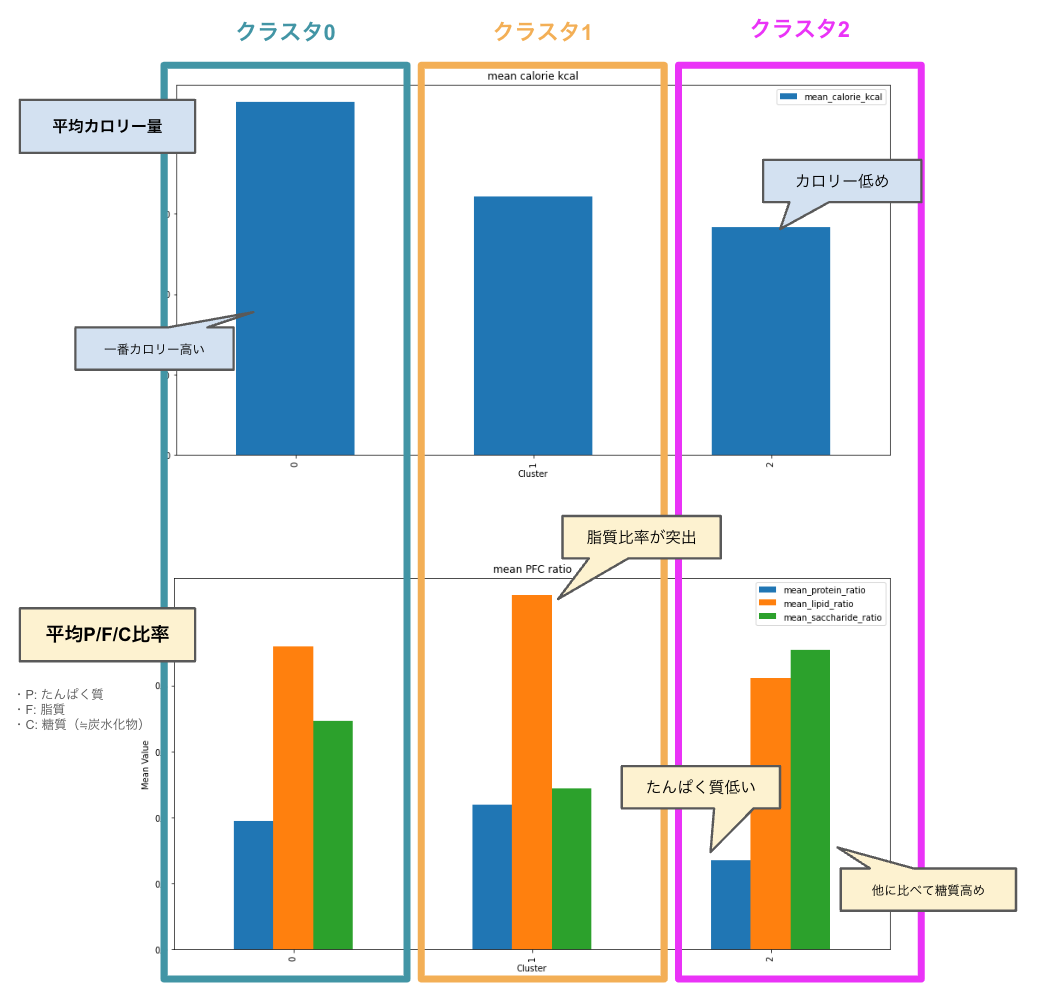
下:視聴レシピの平均たんぱく質対エネルギー比率(青)/平均脂質対エネルギー比率(橙)/平均糖質対エネルギー比率(緑)
図の注釈にあるように、
- クラスタ0はカロリーが高め
- クラスタ1は脂質が高め
- クラスタ2は糖質が高め
などの傾向が相対比較で見て取れます。
「どんなレシピに興味を持っていそうか」目視で把握
次に、各栄養クラスターが視聴しているレシピ名をもとにワードクラウドを作成してみます。

これも図内の注釈に書いての通りですが、どんなレシピやキーワードに興味がもたれやすいかがなんとなく見えてきました。
観察結果をもとに、栄養クラスタを命名する
これらの観察結果を統合し、それぞれ以下の仮説をもとに名前を付けました。
- クラスタ0: 平均カロリーが高め & 主食系のレシピも視聴されやすい
→ 主食も取り入れ層 - クラスタ1: 脂質高め(≒糖質は相対的に低め)& 材料系の頻出語が多い
→ 材料メイン層 - クラスタ2: 糖質高め & お菓子系の頻出語が多い
→ スイーツトレンド層
こうして、本記事冒頭出来たもののセクションにて紹介した栄養クラスタの概観を把握することができました。
(この分類がどこまで妥当かの判断は後続分析に委ねるものの)やってみた側としては「それっぽいな」という所感を得ました。
活用事例
前述の通り、これらの栄養クラスタは「ユーザーのレシピへの嗜好」をある程度反映出来ているようにも見えます。
その可能性を確かめるべく、「DELISH KITCHENアプリ内でのレシピ検索用推薦キーワードの出し分け」のロジックに栄養クラスタを利用する実験を行ってみました。
そして、これがユーザーの検索行動にどのような変化が生じたか、A/Bテストによる効果検証を行いました。
参考: tech.every.tv
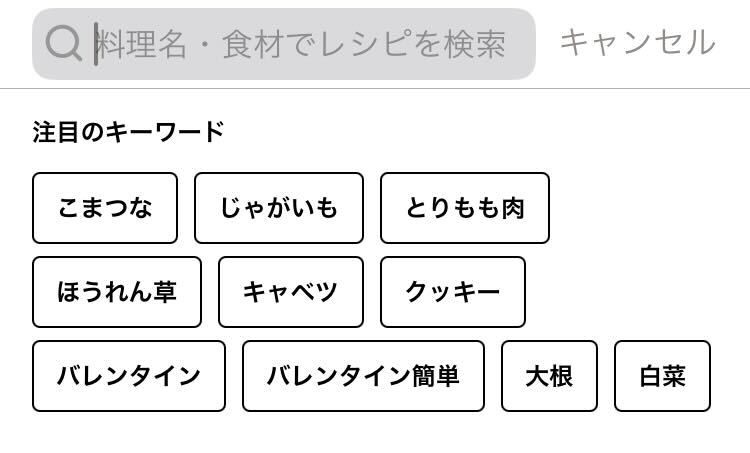
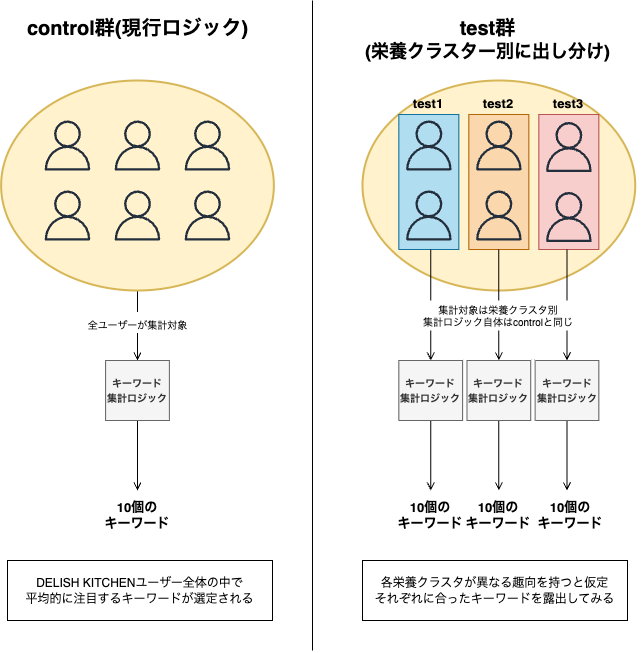
対象面
DELISH KITCHENアプリ 検索サジェストの「注目のキーワード」
新規ロジックの実装とA/Bテスト
- 「注目のキーワード」の集計ロジック自体は現行と同じものを用いる
- 集計対象の集団を、ユーザー全体(control群) vs 栄養クラスターに絞り込んだもの(test群)
という問題設定に落とし込み、A/Bテストを実施しました。
そして、結果の良し悪しを観察するゴール指標として注目のキーワードタップ率※を設定しました。
※ A/Bテスト期間中に一度でも注目のキーワード欄をタップするユーザーの割合
結果
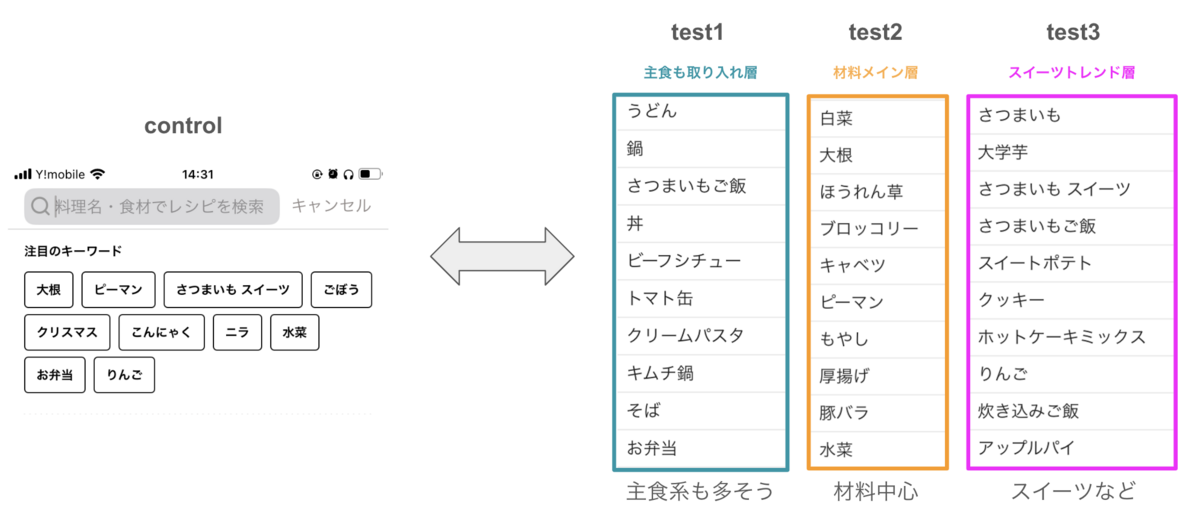
露出されたキーワード
キーワードタップ率の変化
- 主食も取り入れ層(test1), スイーツトレンド層(test3)で、キーワードタップ率が有意に変化しました。
- 一方、材料メイン層(test2)では、タップ率の変化はほとんど認められませんでした。
A/Bテストやってみての所感
箇条書きですがまとめます。
- 栄養クラスタを用いることで、露出される注目のキーワードの雰囲気がガラリと変わりました。
- 今まで埋もれていた、ユーザー嗜好別の注目に今までよりも肉薄できた可能性があります。
- 3つのうち2つのクラスタでタップ率が大幅に向上したため、従来よりもユーザーが求めるキーワードを先回りして提示できた可能性があります。
- ついでに、こういう変化に反応しやすいクラスタとそうでないクラスタが浮き彫りになりました。ここも深掘り分析しても面白そうな所感です。
まとめ
この記事では、ユーザーのレシピに対する栄養嗜好を活用したクラスタリングの事例と、それをアプリのロジックに組み込むことでユーザーの行動変化を促した事例を紹介しました。
シンプルな栄養項目を用いただけでこのような成果を得られたことから、DELISH KITCHENが保有するデータの潜在的な可能性を改めて感じました。
今回開発した「栄養クラスタ」は、アプリのロジックだけでなく、ユーザーセグメント分析など様々な分野での応用が考えられます。
今後もレシピメディアとしてのドメイン知識にも目を向けつつ、データの眠る価値を引き出すための取り組みを継続していく予定です。