こんにちはMAMADAYS バックエンド担当エンジニアの宮本です。
今回は私の所属している開発チームでkubernetes(以下k8s)の輪読会を行ったので、その内容を紹介していきます。 MAMADAYSのサービスやバックエンドシステムの全体像については MAMADAYSのサービスとバックエンドシステムのお話 にて紹介していますので、よろしければご覧ください。 現状MAMADAYSのバックエンドシステムはAWSのEKS上で運用されています。
しかしk8s周りを触っているのが特定のメンバーのみとなっており、チーム内で知識にばらつきがありました。
またそのメンバーも体系的な学習を行っているわけではなく、十分な理解がない状況でもありました。
そのためメンバー内のSREから「チーム全体でk8sへの理解を深める必要があるのではないか」という意見が出され、チーム全員で輪読会を行う流れになりました。
私のいるバックエンドチームはweb開発も行っており、web担当メンバーも自主的に参加し実施されました。 参加しているメンバーが同じ書籍を事前に読んできて、その内容について意見を交わす会です。
事前に決められた担当者が本の内容を要約し、他のメンバーが理解できるような形で発表を行います。
複数人で同じ書籍をそれぞれの視点から読み解くため、個人では理解が難しい部分をフォローしあうことで、よりメンバー間での知見が深まるようになります。 社外も含めた輪読会は実績もなくハードルが高いため、今回はチームメンバーの知識のベースアップと実際に業務で用いている部分を見比べながら行うことに重きを置くようにしました。
またコロナの感染状況も考慮して、Zoomを使ったオンライン開催となりました。 インプレス社から出版されている Kubernetes完全ガイド 第2版 を用いて行われました。 本書はk8sに関する機能でアプリケーションエンジニアが利用する可能性が高いものを網羅的に解説されており、様々なユースケースが紹介されています。
体系的に説明されていて図による視覚的な理解を得やすく、サンプルが添付されているためこちらを利用することとなりました。 輪読会の進め方は様々ありますが、今回は知識のベースアップが目的のためチームメンバーが週一回入れ替わりで担当。事前に対象となるページを決めて、その内容をスライドにまとめて議論していく方針を取りました。
このときの進行役としては発案者であるSREのメンバーが執り行ってくれました。 全体の流れとしては以下のとおりです。 業務を圧迫しないように、毎週金曜日開催で水曜日の時点で間に合わない場合はスキップも可としています。
緩くですが確実に進めれるようにしました。 輪読会は週1ペースで全19回にわたり緩く行われ、読破までには6ヶ月弱かかりました。
本書に書かれていることはもちろんためになりましたが、さらに輪読会をする上で得た経験としては以下のとおりです。 メンバーによってはベースの知識の差で理解度のブレがありましたが、メンバー内でしっかりと深堀りをしていくことで埋め合わせができました。
チーム全体の知識のベースアップができたのはとても大きかったです。 また書籍の内容については新しい発見もあり、プロダクトで生かせる機能が数多くありました。
例を上げると、Pod起動時のヘルスチェックを 書籍のボリュームが多く、読破までの時間がかかってしましました。
ですが、下手に章を飛ばしたりすることなく全体的に学ぶことができました。 また業務や参加メンバーのスケジュールによっては調整が必要でした。
なのであまりかっちりとした予定は組まずに緩く進めるのは重要だったと思います。 以上、社内でのk8s勉強会の簡単な報告となります。
なんとなく理解している状況は継ぎ接ぎの対応で済ましてしまうため、しっかり時間をとって学ぶことは大変有意義となりました。
k8を新規に採用したり運用している場合は、体系的に学ぶことで今後のユースケースに対応しやすくなると思います。 社内でのk8sの勉強会を検討している方に参考になれば幸いです。
社内でkubernetesの輪読会を開催しました
はじめに
経緯
輪読会とは
利用した書籍

運用
実際やってみて
良かったこと
Startup Probe で行うことができ早速導入しました。大変だったこと
最後に
Google I/O 2021で発表されたアプリ内購入の新機能について

はじめに
はじめましてDELISH KITCHEN Androidエンジニアの友部です。 私は現在、プレミアムチームに所属しており、主にAndroidの課金が関係している施策などを担当しています。 今回はGoogle I/O 2021で発表されたアプリ内購入の新機能について書いていきたいと思います。
DELISH KITCHENのプレミアムサービスについて
まず、少しだけDELISH KITCHENの話をさせてください。 DELISH KITCHENではプレミアムサービスとして、有料で利用できる機能やコンテンツを提供しています。主な内容は以下で、1ヶ月のアプリ内購入によるサブスクリプションで販売をしています。プランとしては6ヶ月、1年のものも販売していますが、ひと月あたりの金額が安くなるといったもので、内容は同じものです。
機能
- 人気ランキング
- 広告非表示
- 1週間献立
- すべての栄養成分表示
- お気に入り無制限
コンテンツ(限定レシピ)
- ダイエット
- 作り置き
- ヘルスケア
- ベビー
今回発表された新しい販売方法について
今回のGoogle I/Oでは新しく3つのアプリ内購入の販売方法が発表されました。
1つ目がMulti-Quantity Purchases2つ目がMulti-line Subscriptionsそして3つ目がPrepaid Plansです。
Multi-Quantity Purchases
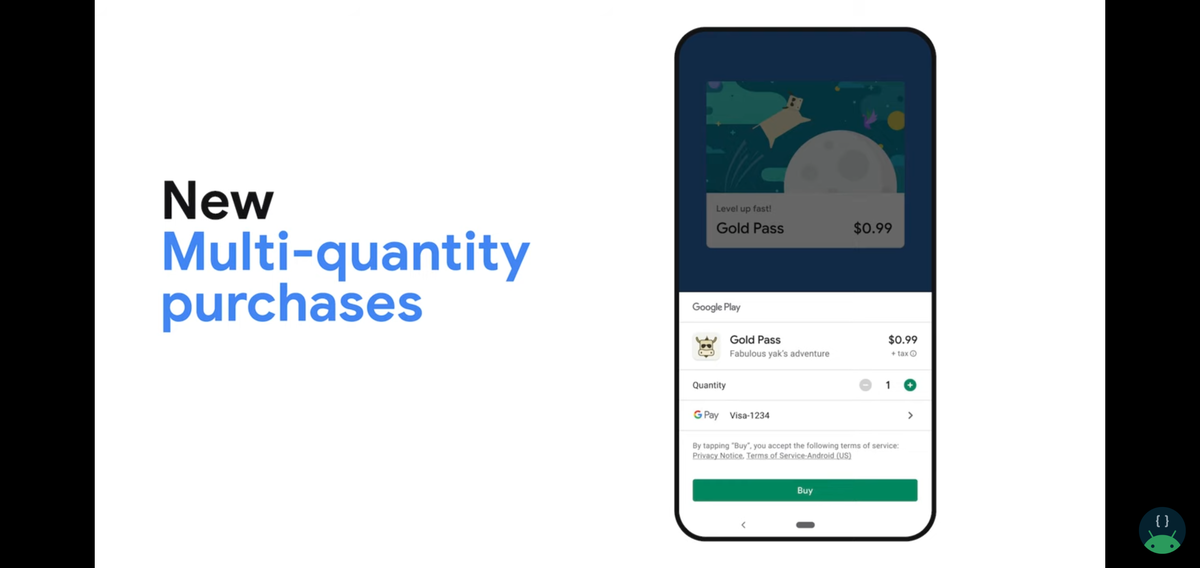
消費型の商品を複数選択し、購入できるようになります。
今まではある商品を1個売り、10個セット売り、20個セット売り…としていたものをユーザーが必要な個数だけ選択し購入できるようになります。ユーザーにとっては嬉しい仕組みになりそうです。 動画の中ではPlay Consoleより設定できるとのことですがまだ項目が表示されていないためもう少し待つ必要がありそうです。現在DELISH KITCHENでは、そのような消費型の商品は存在していないため出番はないかもしれません。
Multi-line Subscriptions

1つのサブスクリプションの一部として、複数のサブスクリプションを販売することができます。
今まで1ユーザーに対して、1つの商品しかサブスクリプションとして提供しないのが主流でしたが(別の商品はアップグレード、ダウングレード扱い)、機能を個別に切り出してユーザーに選択して購入してもらうといったことが可能になります。 例えばDELISH KITCHENの場合なら、限定レシピを分割して提供し、ダイエット、作り置き、ヘルスケア、ベビーをそれぞれをサブスクリプションの商品として販売します。ユーザーは必要なレシピを選択し、購入するといったことができるようになります。 それに加えて、別のジャンルが欲しくなった場合は追加で購入したり、不要になった場合は削除したりできます。
Prepaid Plans
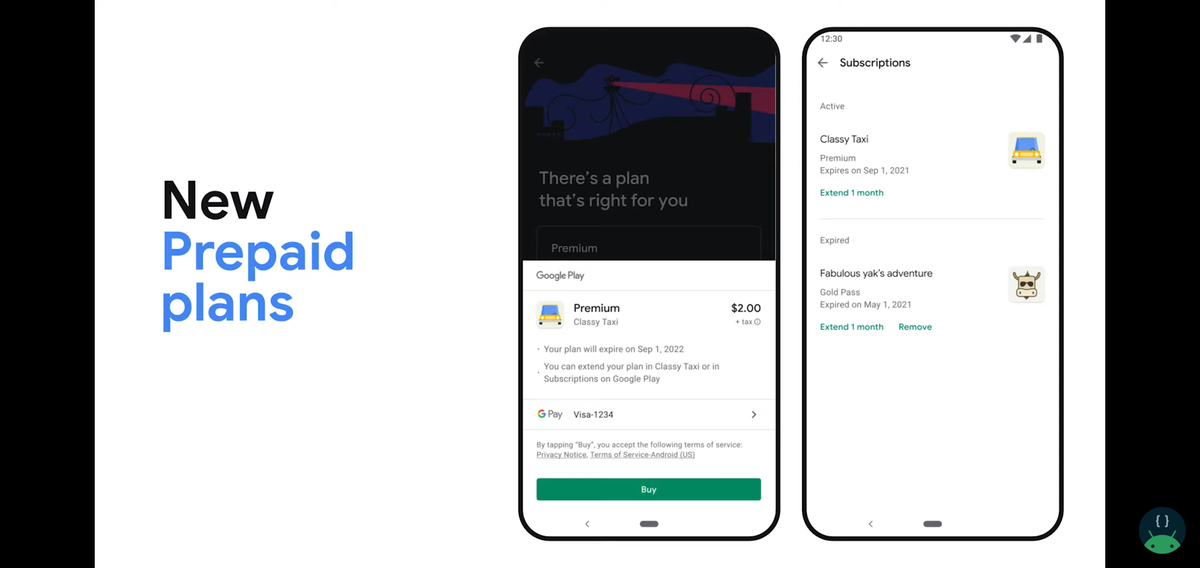
一定期間、ユーザーにコンテンツへのアクセスを提供できるようになります。
ユーザーにプレミアムサービスの一部を切り出して提供することで、プレミアムサービスの価値を感じてもらった上で通常のプレミアムサービスを購入してもらうといったことが可能になります。
具体的には、機能の広告非表示の部分だけを提供したり、限定レシピのうちいくつかだけを提供したりするようなイメージです。
有効期限が切れそうになるとユーザーに通知が届くので、そのタイミングでアップデートしてもらえるようにするのが良さそうです。このPrepaid PlansはReal-time developer notificationsやSubscription APIなどもサポートされます。
最後に
2021/5/18にこれらの発表があり、Billing Library 4.0は提供されたもののこれらの機能自体はまだ使えないようです。
しかし、Googleが公式に提供しているアプリ内課金のサンプルコード(Google Play Billing Samples) にもこれらの機能を示唆するコメントがコード内に記載されていたので間もなく使えるようになるでしょう。公開されたら実際に使ってみて次の機会にブログに書いていけたらと思います。
最後までお読みいただいてありがとうございました。
参考:Grow your business with new engagement and monetization features | Session
Core Web Vitals 改善のお話

Core Web Vitals 改善のお話
はじめに
こんにちは。MAMADAYS Web 担当の櫻井です。 以前のエブリーエンジニアブログにて Google の Core Web Vitals (以降 CWV) についてご紹介しました。今回は CWV のパフォーマンス改善について、MAMADAYS の Web チームが実際に行ったこと、またその結果についてをご紹介したいと思います。
ゴールとしては CWV の3指標 FID, LCP, CLS を合格基準にすることと、ベンチマークしているサイトよりも優れた数値に改善する*こととしました。
*Google の公式 FAQ によると、CWV が検索ランキングシグナルとして使われるケースは"tie-breaker"の役割が強いようで、ひとまずは競合の中で上位に入り込むことがページパフォーマンスの恩恵を受ける第一歩となります。 - What is the page experience update and how important is it compared to other ranking signals?
まずは計測してみる
パフォーマンス改善においては何よりもまず現状を計測してみることに始まります。今回はひとまず Page Speed Insights(以降 PSI)でサイトの状態を確認してみました。
MAMADAYS のとある記事ページを測定した結果、2021/01 時点では以下のようになりました。
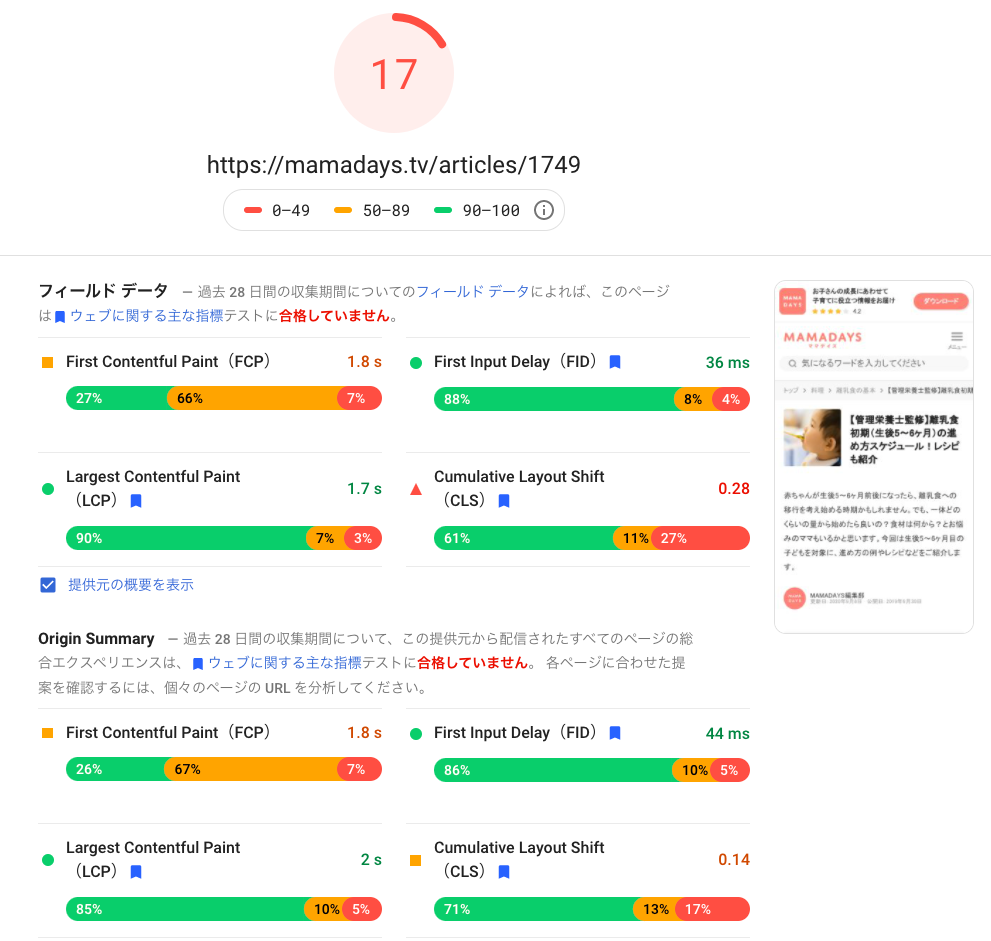
なお、結果の見方としては一番上の数字がこの時点で測定した Lab データから算出されるスコアです。直下の「フィールド データ」は現実のユーザの体験をビッグデータとして Google が蓄積したものを反映した数値です。そのため、上のスコアと下のフィールドデータには必ずしも連動しているわけではありません。
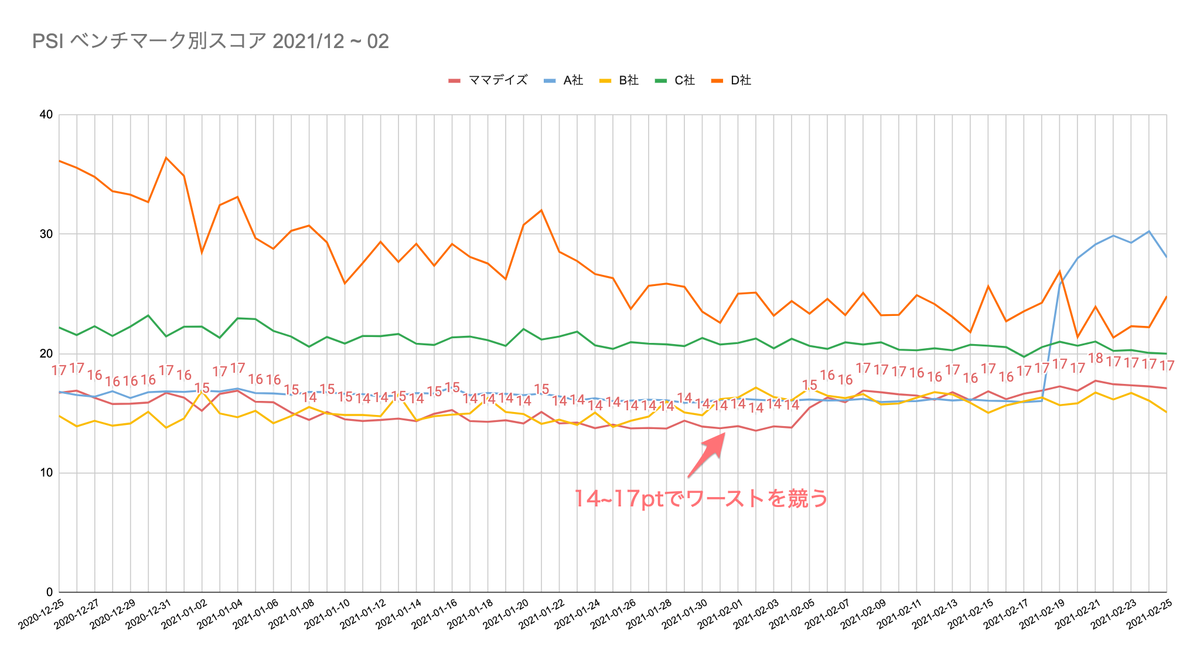
CWV は FID, LCP が Good 圏内で、CLS が Bad 圏内。そしてスコアは 17pt。これはベンチマークしているサイトのページと比較してもワースト1位を競う非常に悪いスコアでした。
また Web パフォーマンス改善にあたって、FID, LCP, CLS の各数値については改善の結果をリアルタイムで把握したいため、PSI で表示されるフィールドデータではなくラボデータを取得・蓄積すると良いでしょう。前回の記事で紹介したように MAMADAYS ではラボデータを BigQuery に蓄積し metabase でモニタリングするようにしています。ただし、CLS に関しては正しく値を取得できなかったため、特定の記事の Lab データを毎日取得するスクリプトを作成し、モニタリングを行いました。(API は PSI API を使用)
弱点を特定する
CWV の値をある程度把握できたところで、次にどこの改善に着手すべきかを特定します。
MAMADAYS では CWV 合格へ向けて CLS の改善はもちろん、スコアを底上げするために LCP の改善も目指しました。FID はこの時点で最も合格閾値を超過している(100ms)ため、注力しないことを決めました。
具体的な改善アクションを決める際には PSI や Lighthouse が非常に役に立ちます。これらは当該サイトの何がパフォーマンス的に悪いかを親切に文章で教えてくれる機能を有しています。 PSI の結果の画面をスクロールしてみるといくつかの項目で指摘されていました。
Remove unused JavaScript使用されていない無駄な JavaScript が読み込まれているようです。tree-shaking を適切に行い、デッドコードの除去をする必要があります。また、そもそも使われていない余分なコードをリファクタして削除するなどの整理をすると良さそうです。なお、今回はここの改善は行っていないため説明は割愛しますが、多くの場合ここを改善すれば大きく LCP が下がることが期待できます。
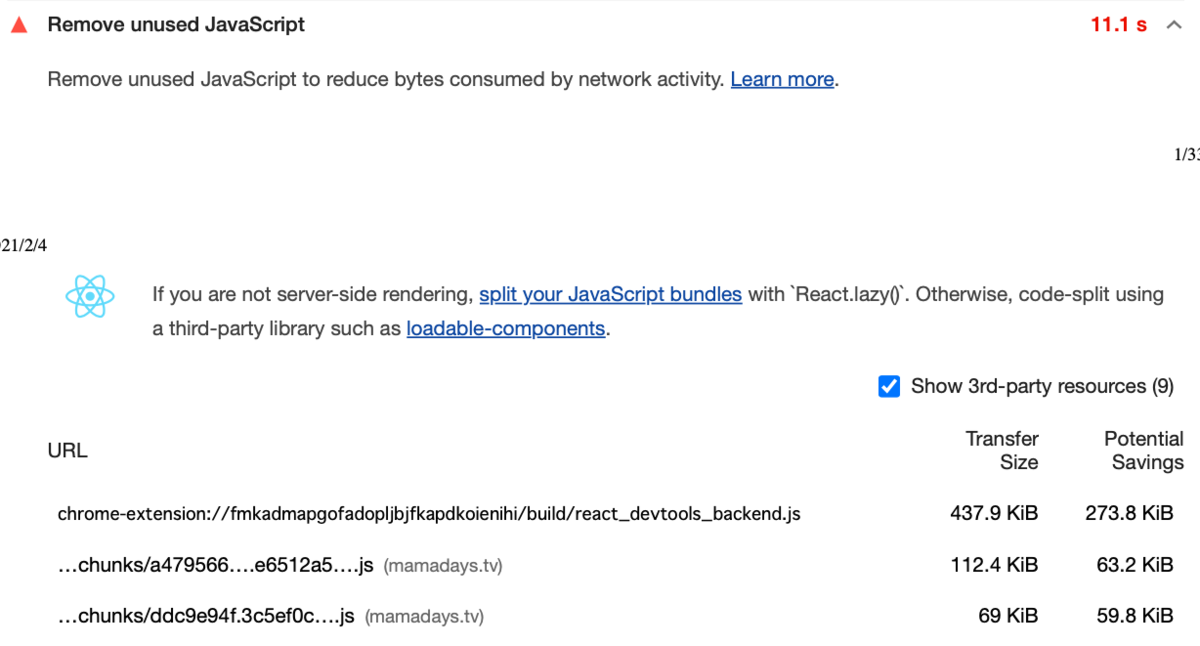
Defer offscreen images画像の遅延読み込みがされていないようです。ファーストビューに表示されない画像の遅延読み込みをする必要があります。特に
sp_footer_banner@3x.png,babyfood_merit_banner@3x.pngはファイルサイズが大きく、かつフッター部分に表示される画像なので必ず遅延読み込みをした方が良い画像です。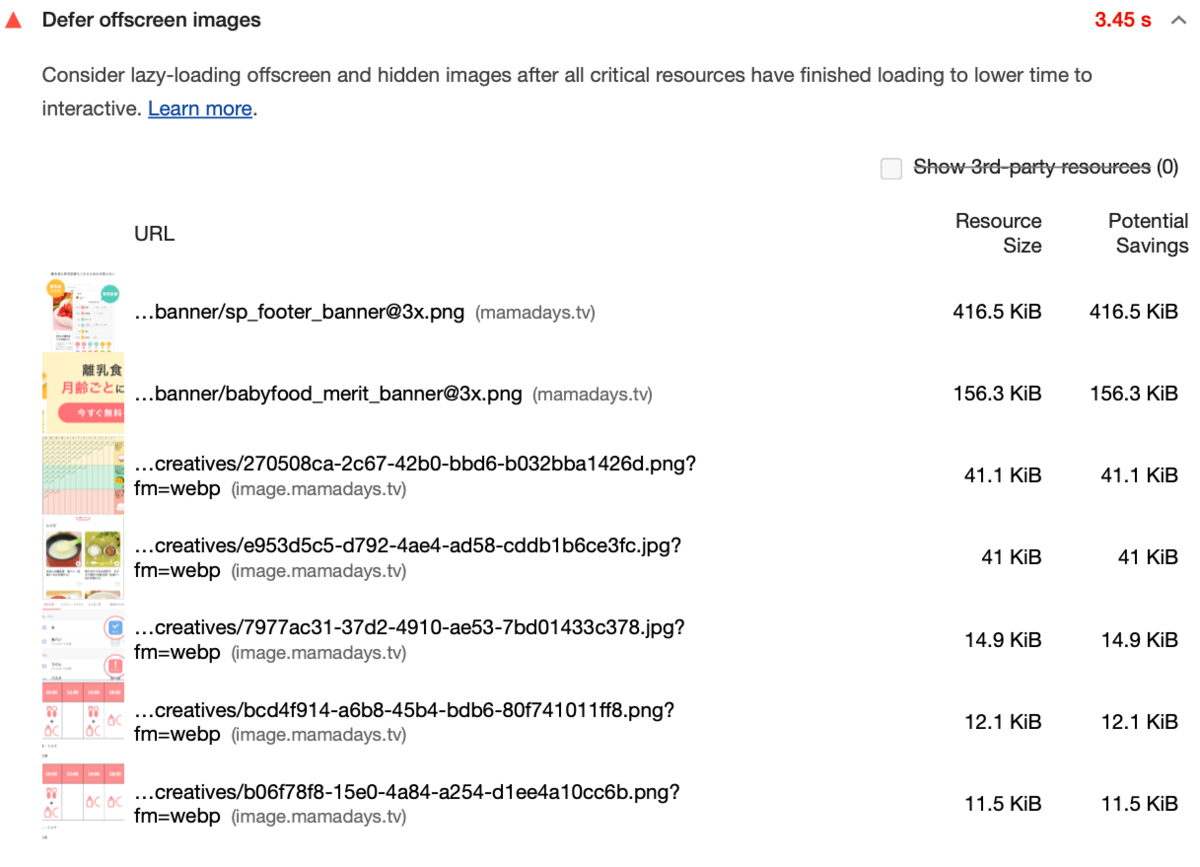
Remove unused CSS使用されていない無駄な CSS が読み込まれているようです。 特に
viceo-react.cssは使用率が 0%で、かなり無駄なロードになってしまっているようです。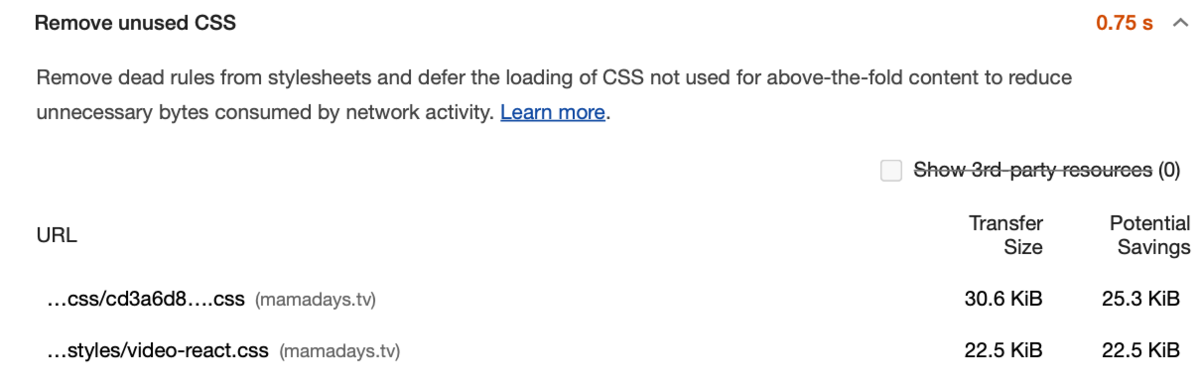
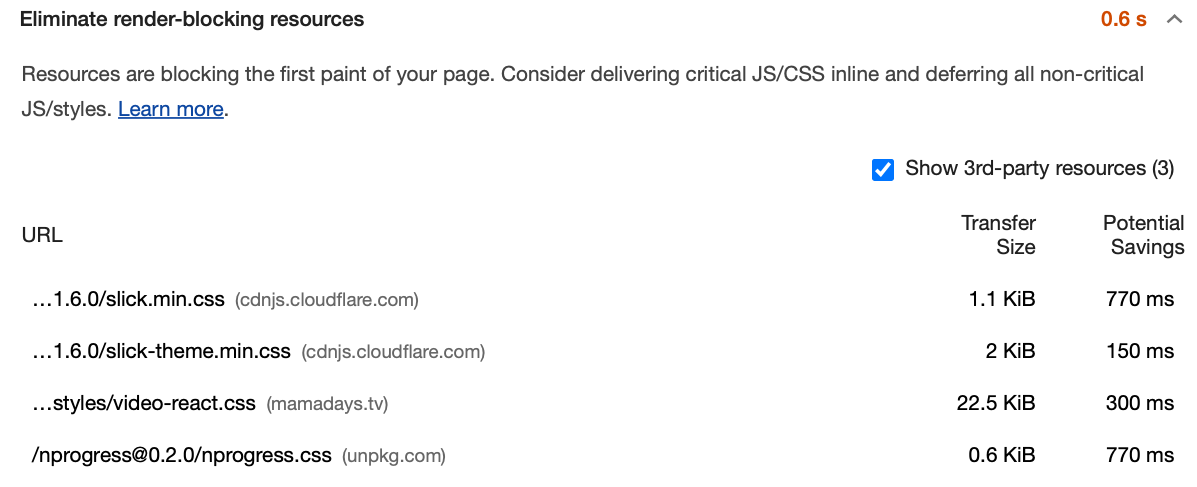
Eliminate render-blocking resources初回レンダリングを遅くする読み込み方法のリソースがあるようです。MAMADAYS では CSS の読み込みが阻害要因となっており、読み込みタイミングの見直しが必要そうです。
Properly size images画像のサイズが最適でないようです。ここでも一番上の画像については 93%も太っているようなので、適切にサイズを制限する必要がありそうです。
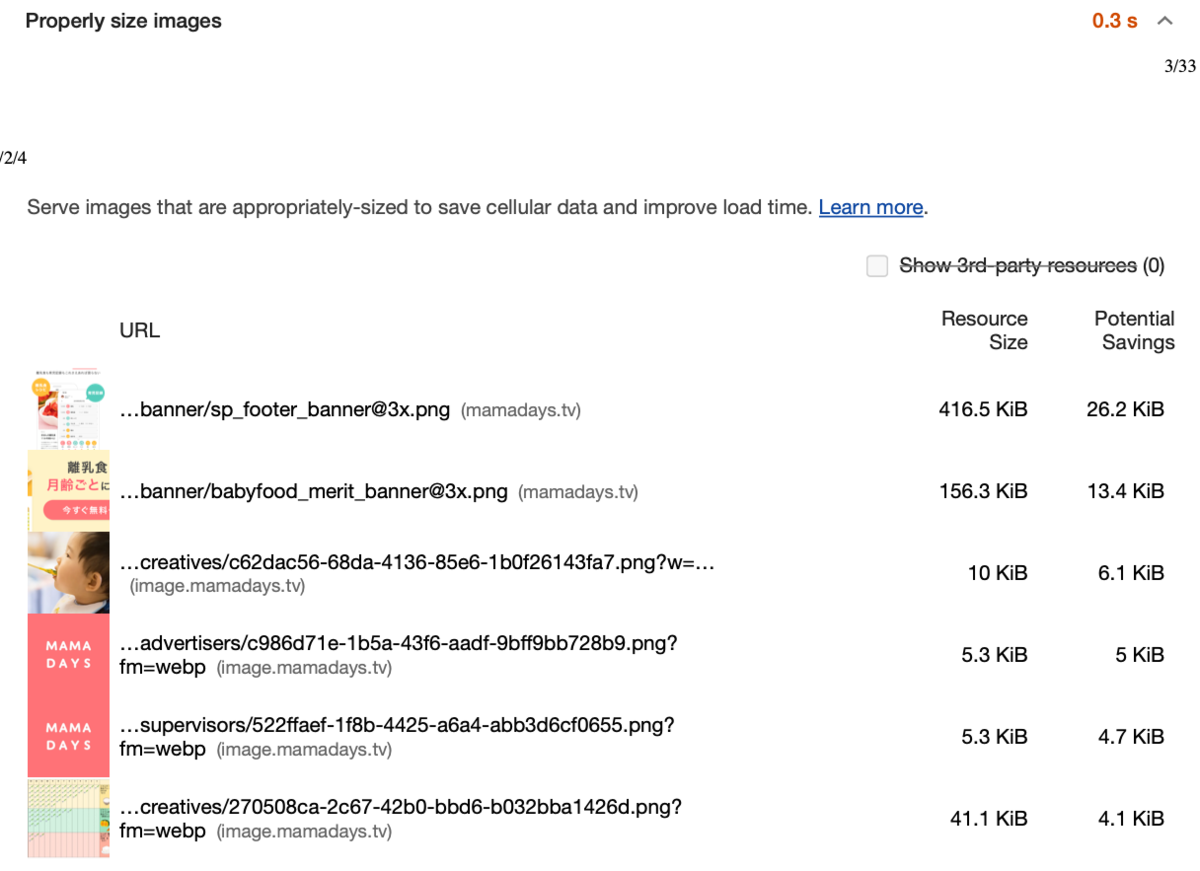
このように PSI で検査するだけで多くの改善ポイントがあることが把握できました。ただし PSI や Lighthouse ではフロントエンドの改善項目しか検査できません。例えば LCP についてはサーバーサイドやインフラの構成を見直すことでも十分に改善できることを念頭においた方がよいでしょう。
LCP の改善
LCP の改善では大きく改善が進んだポイントが3つありました。
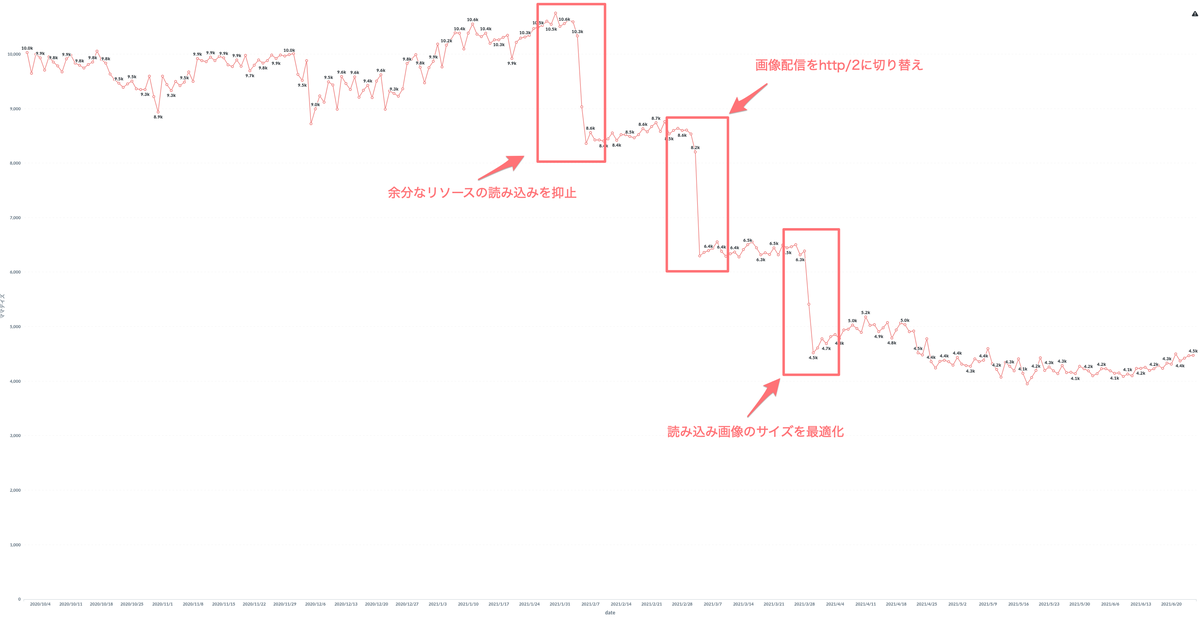
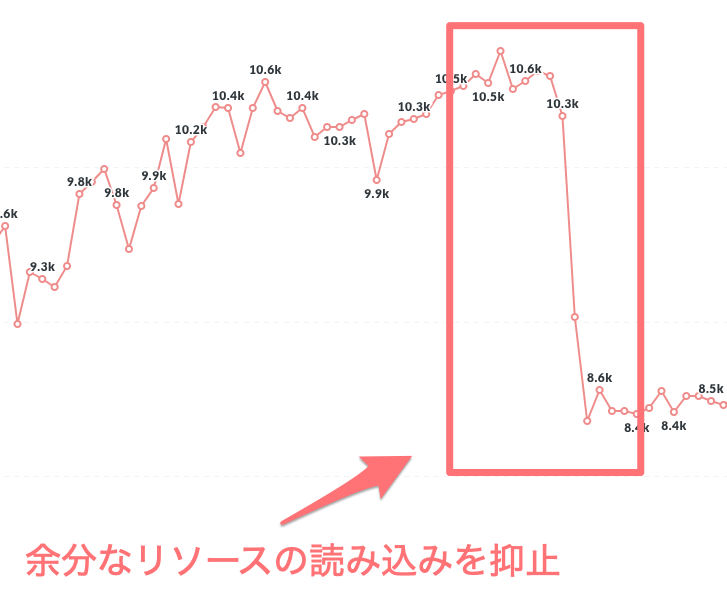
無駄なリソースの読み込みを除去
1つ目は2月頭の -2000ms ほどの改善です。
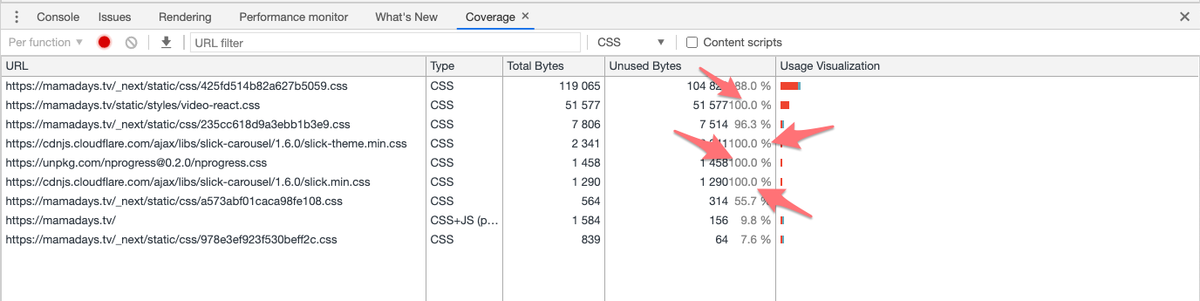
「Remove unused CSS」と「Eliminate render-blocking resources」について対応しました。上記の指摘では、カルーセルを実装する slickや、動画プレイヤーのvideo-reactが挙げられています。
Chrome Developer Tool の Coverage 機能で確認すると確かに無駄な CSS であることがわかります。
MAMADAYS では CSS を Next.js の CSS Modules で読み込みをしているため、これらの読み込み箇所を _app.js から実際に必要なコンポーネントに移動しました。これにより不要なCSSの読み込みが除去されたことがわかります。

http2 への切り替え
2つ目は3月頭の -2200ms ほどの改善です。
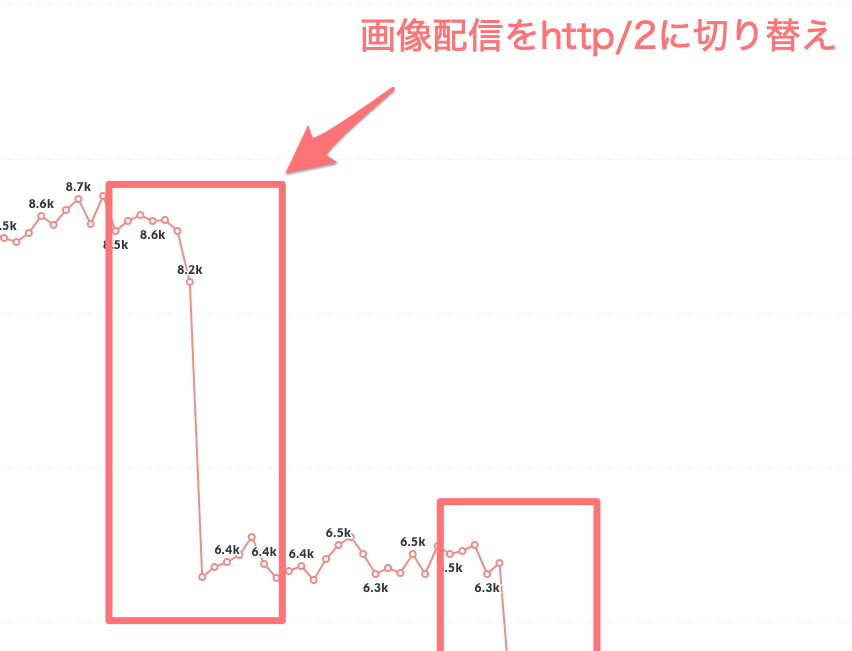
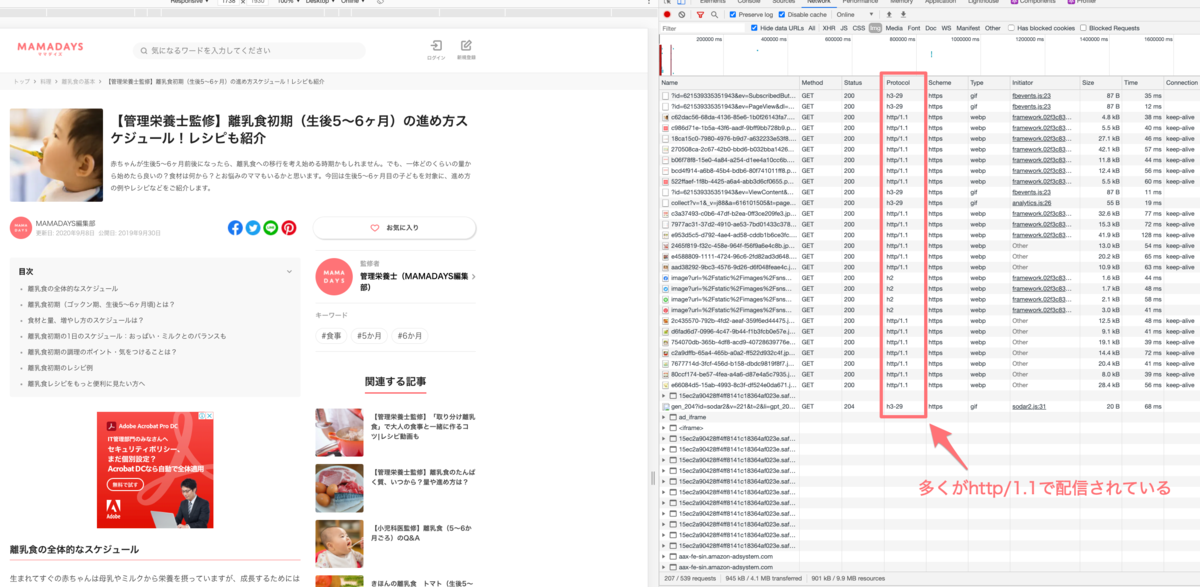
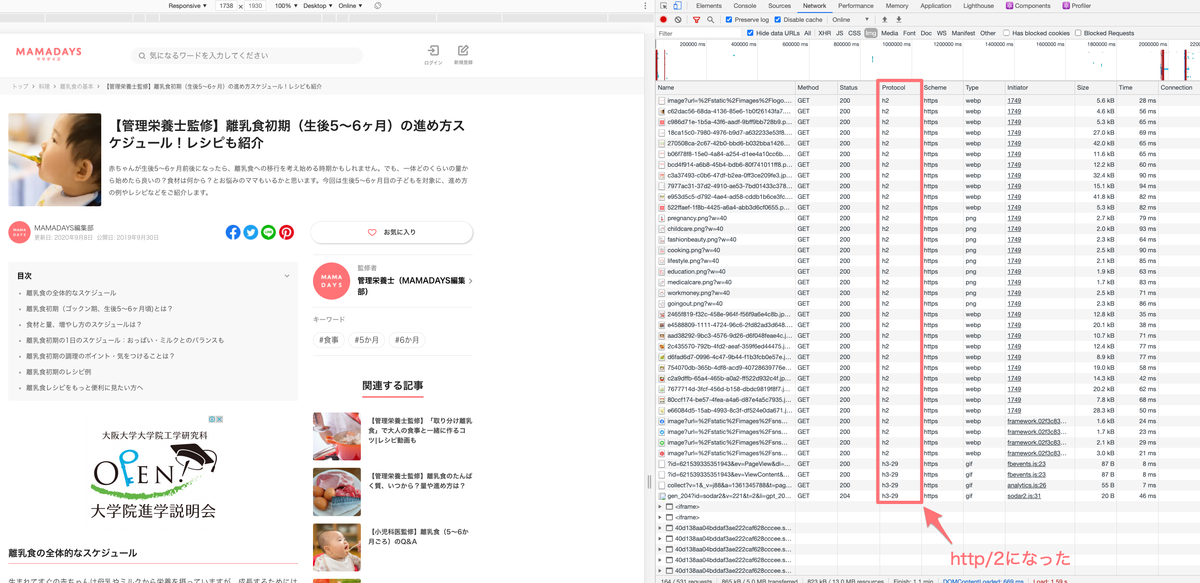
これは Web 内で使われる画像の配信元 CDN のプロトコルを http/1.1 から http/2 へ切り替えたことによるものです。この切り替え設定自体は2月頭に行っていたものですが、このタイミングで PSI がリクエストを http/2 で行うように変更されたため、数値に大きく改善が現れました。
ref: March 3, 2021 | PageSpeed Insights uses http/2 to make network requests
before
after
画像を適切なサイズで配信
3つ目は3月末の -1800ms ほどの改善です。
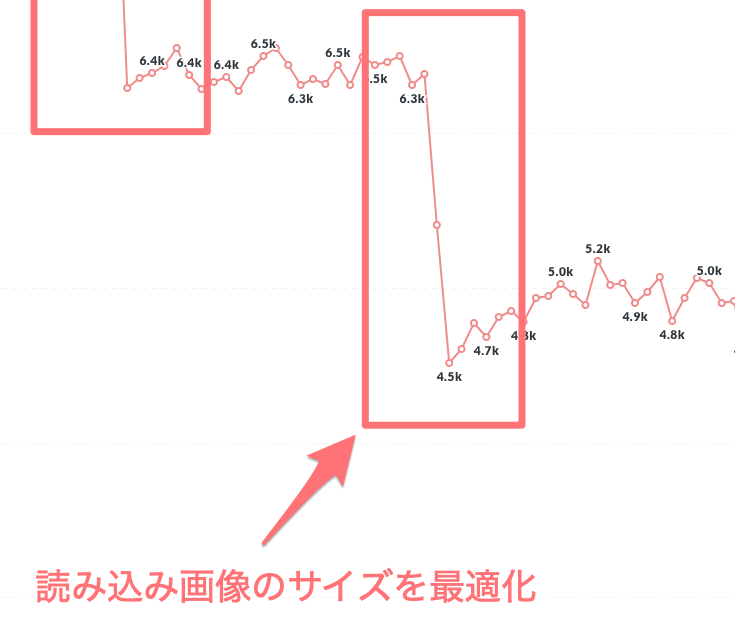
PSI での指摘項目にあった「Properly size images」に対応した結果でした。MAMADAYS では画像を CloudFront で配信しており、同時に Lambda Edge にてリサイズを行なっています。取得する画像の URL クエリパラメータに?w=400などサイズを指定することでリサイズできるようにしているため、これを使ってサイズの最適化を行いました。
以下はコードの抜粋ですが、sourceのmedia attributeで sp/pc 時の画像サイズを適切に切り分けました。Retina 対応のために 2x 時の指定もsrcset attributeで行うと良いでしょう。
また、リサイズと同時に画像タイプも WebP に変換することでよりサイズの軽量化を行なっています。
const spSize = [imgSize.sp, imgSize.sp * 2];
const pcSize = [imgSize.pc, imgSize.pc * 2];
<source
type='image/webp'
media='(max-width: 767px)'
srcSet={`${src}?w=${spSize[0]}&fm=webp, ${src}?w=${spSize[1]}&fm=webp 2x`}
/>
<source
type='image/webp'
media='(min-width: 768px)'
srcSet={`${src}?w=${pcSize[0]}&fm=webp, ${src}?w=${pcSize[1]}&fm=webp 2x`}
/>
<source type='image/webp' srcSet={`${src}?w=${pcSize[0]}&fm=webp, ${src}?w=${pcSize[1]}&fm=webp 2x`} />
<img
src={`${src}?w=${pcSize[0]}&fm=jpg`}
alt={alt}
loading={loading}
{...(hasSize ? { height, width } : null)}
className={classnames(css.image, className)}
/>
改善したものの数値に影響がなかったもの
PSI の指摘項目のうち、数値に影響があまり現れないものもあります。
例えば「Defer offscreen images」は 確かに対応した方が良いものですが多くの場合、遅延読み込みするべき画像はファーストビュー外の画像になるため、LCP の対象になるものが少ないです。そのため効果があまり現れなかったのでしょう。この辺りは改善コストを省みて実施するかを判断するのがよいでしょう。
巨人の肩に乗る(大切)
MAMADAYS Web は React 製で、フレームワークに Next.js を使用しています。Next.js はパフォーマンス観点の積極的な改善を行っており、v10.1 ではバンドルサイズが 58%も縮小されたことで純粋にロードするファイルサイズが小さくなり、LCP の向上につながります。このようにコミッティーの勢いがあり積極的に改善が行われているフレームワーク・ライブラリを選定することもパフォーマンス改善において重要になるでしょう。
Announcing Next.js 10.1:
— Vercel (@vercel) March 29, 2021
• 3x Faster Refresh (200ms faster per save)
• 58% Smaller Install (54% fewer deps)
• Webpack 5 as opt-in flag
• Apple Silicon (M1) Support
• Next.js Commerce @Shopify Integration
• More <Image> layout and loader optionshttps://t.co/swmB7h2sOg
CLS の改善
CLS の改善では主に画像の領域確保と広告の領域確保を行いました。
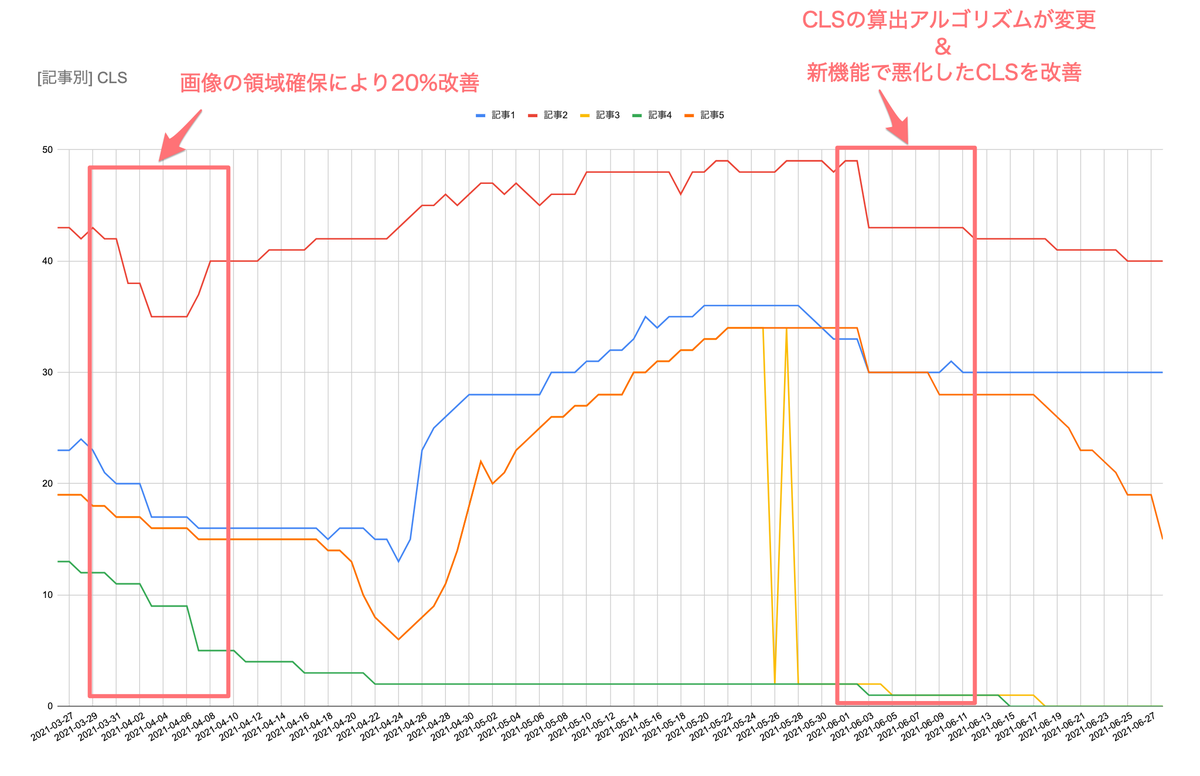
3月末の時点で画像のサイズ最適化と同時に width と height を指定して領域の確保を行いました。これにより 20%ほどの改善ができました。
その後に数値が大きく上ぶれてしまっているのですが、これは新機能として CLS と相性の悪い機能を実装したことによるものです。これについてはその後改善を行ったり、CLS の算出アルゴリズムが変わったことで元の水準まで戻していますが、新機能を実装する際には Web パフォーマンスの観点からも慎重に検討を行いたいところです。
CLS の算出アルゴリズムが変わったことで CLS が向上
2021/06 に Lighthouse8 がリリースされました。これを機に CLS の算出アルゴリズムが変更になりました。元々は CLS はページ滞在中全てのレイアウトシフトを累計したものになっていましたが、変更後は 5 秒間の内に発生したレイアウトシフト群の合計の中で最も値の大きいもの、というようになりました。これにより多くのサイトで CLS が改善し、MAMADAYS もその恩恵を受けることができました。詳細については以下をご参照ください。
https://web.dev/cls/#what-is-cls
スコアロジックにも変更あり
また Lighthouse8 ではスコアロジックが変わりました。各指標のスコアに反映される重み付けが変更になったのですが、以下のようになりました。 特に CLS が3倍になっているため、従前よりもレイアウトシフトを起こさない実装を心がける必要があります。
| 指標 | 従前 → 変更後 |
|---|---|
| First Contentful Paint | 15% → 10% |
| Speed Index | 15% → 10% |
| Largest Contentful Paint | 25% → 25% |
| Time to Interactive | 15% → 10% |
| Total Blocking Time | 25% → 30% |
| Cumulative Layout Shift | 5% → 15% |
https://web.dev/performance-scoring/
改善の結果
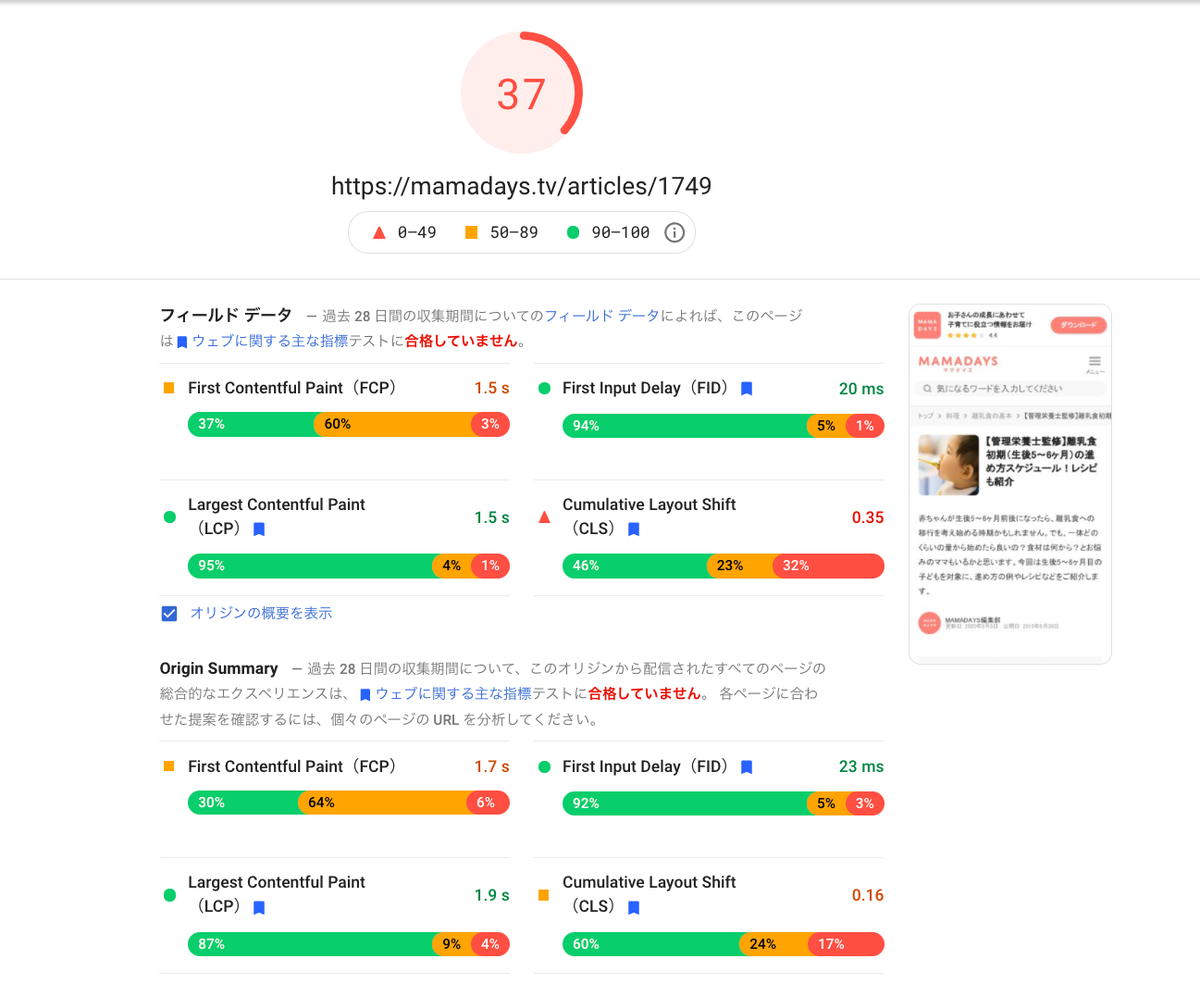
この時点での PSI を測定してみると以下のようになりました。
フィールドデータは遅れて徐々に反映されるため、変化がないように見え少々分かりにくいですが、特に LCP の改善が効いたことで 20pt ほどスコアが向上しました。
これによってベンチマークしているサイトの中でもランキング上位を推移するようになりました。
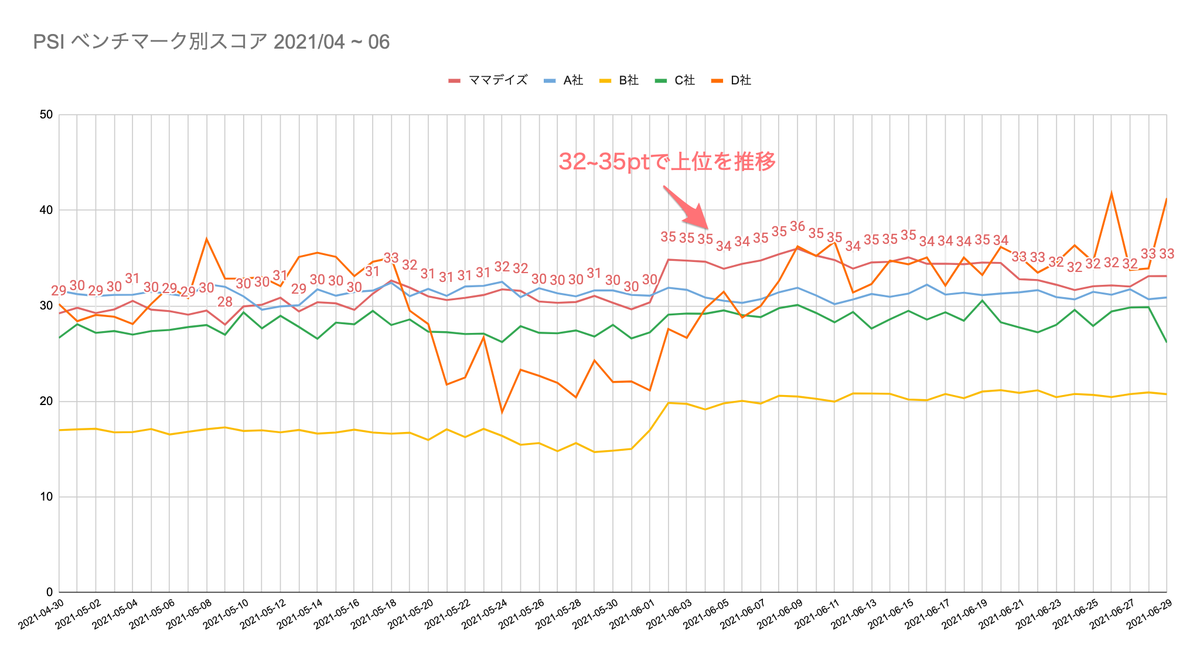
今回はランキング上位に入ることはできましたが、CWV の合格基準に達することはかないませんでした。合格基準を満たせるように、MAMADAYSでは今後も改善を重ねていきます。
まとめ
今回はほとんどがフロントエンドにフォーカスした改善でしたが、より改善を進めるためにはサーバーサイドアプリケーションの改善やキャッシュの改善を行う必要があります。MAMADAYS では今後も継続的によりよい UX を提供するためパフォーマンスの改善を続けていきます。よい UX を作ることやパフォーマンスの改善に興味がある方・造詣が深い方はぜひ RECRUIT | every, Inc. までご連絡ください。
DELISH KITCHEN のデータベースの現状と Aurora を導入した話

はじめに
DELISH KITCHEN のデータベースについて紹介します。
サービスやバックエンドシステムの全体像については DELISH KITCHEN のサービスとバックエンドシステムのお話 - every Engineering Blog で紹介しています。よろしければご覧ください。
概観
DELISH KITCHEN ではサービスの大半のデータの保存に Amazon RDS を使用しており、データベースエンジンとしては主に MySQL を使用しています。サーバーがいくつかに分かれておりデータベースもそれぞれにありますが、今回はレシピやユーザーの情報の入ったメインのデータベースの話をします。
DELISH KITCHEN は規模としては月間総利用者数※ 5200 万人のサービスです。
※ DELISH KITCHEN のアプリ、Web、SNS、サイネージなど全ての提供内容における総利用者数のこと。
オンメモリキャッシュ
レシピなどのマスタ系のデータについては、更新頻度が低いことからサーバーアプリ内にオンメモリキャッシュを持ち、定期的に更新するというアプローチを取っています。管理画面外からのアクセスにはそのキャッシュを利用しており、トランザクション系のデータの読み書きについてはキャッシュは行わずサーバーから RDB へ読み書きを行っています。
RDB 負荷分散
MySQL レプリケーションを利用して複数のインスタンスへ負荷を分散しています。また、マスタ系とトランザクション系の DB インスタンスを分けており、トランザクション系の方の RDS インスタンスタイプを大きめにしています。
Amazon Aurora の導入
最近読み込み頻度が高く、レコード量が将来的に数千〜億単位になることが見込まれ、かつ読み書きのレイテンシがアプリの初期描画速度に影響するために相応に低いことが求められるデータの保存方法を考える機会がありました。 書き込みは素直なテーブル構造にするとランダムインサートとなり、通常の RDS ではレコード量増加に伴って書き込みのレイテンシは増えていくことが想定されました。
そこで、レコード量が増加しても I/O が低下しにくい Amazon Aurora MySQL を導入しました。導入にあたり簡単な負荷試験をして RDS (MySQL) との比較を行いましたのでその概要を紹介します。
Aurora と非 Aurora RDS の負荷試験による比較
ランダムインサートを行う下記のような簡素な Go のコードを実行し、レコード量増加に伴った INSERT のスループットの変化を確認しました。
func main() {
insertedCount := int64(0)
insertStart := time.Now()
countMutex := sync.RWMutex{}
wg := &sync.WaitGroup{}
for i := 0; i < 8; i++ {
wg.Add(1)
go func() {
sess := getSession() // DB セッションを作成
for insertedCount < 10000000 {
// 主キーをランダムに発行した適当なレコードを INSERT
record := genNewRecord()
if _, err := sess.InsertInto("test_table").Columns("col_a", "col_b").Record(record).Exec(); err != nil {
panic(err)
}
countMutex.Lock()
insertedCount++
if insertedCount%100000 == 0 { // 100000 レコードごとに経過時間を出力
fmt.Println(insertedCount, time.Now().Sub(insertStart))
}
countMutex.Unlock()
}
wg.Done()
}()
}
wg.Wait()
os.Exit(0)
}
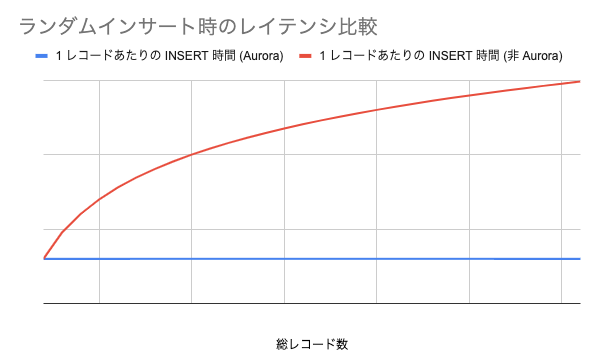
結果的に、レコード量が増えても Aurora ではまるでスループットは一定でしたが、非 Aurora では対数的ではありますが顕著な増加が見られました。(グラフはイメージです)
導入決定〜使用開始まで
Aurora RDS インスタンスの作成、サーバーアプリからの接続までについては非 Aurora のそれとあまり変わりませんでした。DB インスタンスがたとえ 1 つのみでも Aurora クラスターが作成され、Web コンソールの DB 一覧を見るとクラスタ配下にインスタンスがあると表示されます。
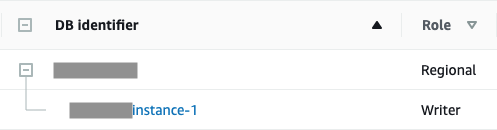
MySQL 互換なので、接続後は通常の MySQL エンジンと(完全ではないようですが)同じように使用できます。導入後のパフォーマンスについてはまだレコード数が多くないのであまり大きなことは言えませんが、期待通り動作しています。
Aurora を監視する
Aurora は非 Aurora の RDS と比べて取れるメトリクスが変わってきます。How to Collect Aurora Metrics | Datadog に非常にわかりやすくまとまっていたので、参考にして以下の項目に合致するメトリクスをモニタリングしています。
- Query throughput
- Query performance
- Resource utilization
- Connections
- Read replica metrics
最後に
DELISH KITCHEN のデータベースについての紹介でした。DELISH KITCHEN ではレシピ動画サービスの安定稼働に向けて改善を続けています。お読みいただきありがとうございました。
参考
今すぐできるレビュワーに優しいPull Requestをつくる7つのポイント
はじめまして。DELISH KITCHEN開発部の桝村です。DELISH KITCHENのWEBフロントやAPIサーバーの開発等に携わっています。 突然ですが、みなさんは本日もPull Requestを使ってレビュー依頼しましたか?もしくは、誰かからレビュー依頼を受けましたか? チーム開発におけるコードレビューというものは、プロダクトの品質向上やチーム内での知見共有に貢献しているものの、チームがコードレビューに対して相当な時間や労力をかけているのも事実かと思います。 加えて、レビュー対象の実体でもあるPull Requestの品質は、作り手である実装者に大きく依存しており、コミットから説明文まで自由に作れる反面、レビューしやすいPull Requestを作成しないと、より一層自身やチームに大きな負担がかかる可能性があります。 そこで、今回はレビュワー目線に焦点を当てて、レビューしやすいPull Requestをつくるために自分が心がけていることを紹介させて頂きます。
簡単かつすぐに改善できるポイントをまとめたので、ぜひ参考にして頂けると幸いです。 WhyとWhatが不十分な場合、レビュワーはそれらをコードから想像せざるを得なかったり、実装者へ直接確認する手間が生じて、大きな負担になる可能性があります。また、WhyとWhatが区別されず混合している場合も、実装内容の難易度や複雑性により、実装者とレビュワーの認識に齟齬が生じ得ます。 WhyとWhatをそれぞれきちんと記載することで、レビュワーは、本来のレビュー内容である、仕様通りかどうか、改善の余地はあるか等の確認作業に集中でき、よりコードレビューをしやすくなります。 また、Pul Request自体が履歴的な情報としてリポジトリ内に残り続ける点で、実装に関するドキュメントとしての役割も担います。よって、WhyとWhatをきちんと記載することは、長期的に見てもチームにとって非常に貴重な財産になります。 加えて、以下のような情報があると、実装内容の正当性を容易に検証できたり、アウトプットがひと目で分かる点で、よりレビュワーが実装概要を理解しやすくなります。 説明文が各項目について整理されず文章のみで構成されている場合、読み手であるレビュワーは実装内容の要点を理解するのに時間がかかり、大きな負担になる可能性があります。 説明文では以下のようにマークダウン記法を使用できるので、見出しや箇条書き、コード埋め込み等のスタイルを利用することで、レビュワーは、実装概要をひと目で理解でき、よりコードレビューをしやすくなります。 参考: Basic writing and formatting syntax また、Pull Request TemplatesというPull Requestの説明文に対して開発者に含めて欲しい情報をカスタマイズし、標準化できる機能があり、これを使用すると、レビュワーにとって見やすい説明文になるだけでなく、実装者にとっても構造化する手間がなくなったり、何を記載すれば良いか明確になる点で導入するメリットが非常に大きいです。 参考: Creating a pull request template for your repository コミットの粒度がバラバラであったり複数の変更が入った曖昧なコミットである場合、レビュワーはどんな変更をしているのか把握しづらく、大きな負担がかかる可能性があります。 機能実装やバグ修正、リファクタ等、まずは単一の課題や目的を単位としてコミットすることで、レビュワーは、変更概要や意図を正確かつ容易に理解でき、よりコードレビューをしやすくなります。 加えて、以下のようにコミットメッセージにPrefix (テキストの先頭につける文字) をつけると、どのカテゴリの修正をしたのか、プロダクションコードに影響があるコードかがひと目でわかるようになり、よりコードレビューをしやすくなると思います。 Pull Requestが大きすぎる場合、レビュワーは単純に時間や労力がかかるだけでなく、既存のコードへの影響範囲が大きくなるゆえに問題点の発見も困難になり、大きな負担がかかる可能性があります。 適切な大きさに分割すると、レビュワーは、影響範囲もより限定的になるため、レビューが楽になったり、その精度も上がり、よりコードレビューをしやすくなります。Pull Requestの粒度としては、自分の場合、スコープ、つまり機能セットを絞り込み、1つのPull Requestで解決するタスクを減らすことを意識しています。 特定のコードについて説明が必要な場合があると思います。例えば、実装したものの自信がなく注意深くレビューをお願いしたい時やコードのみで実装の意図が伝わりにくい時、知見を共有したい時などです。そういった場合、インラインコメントを記載すると、レビュワーは、自ずとコメント周りのコードを注意深く確認したり、早期に問題提起・解決策の話し合いができ、よりコードレビューをしやすくなります。 参考: Adding line comments to a pull request また、実装者が躊躇せず積極的に発信することが、有意義な議論やコミュニケーションが生み、結果的にチームの成長や開発効率の向上に繋がると思います。 テストがない場合、レビュワーは実装内容の仕様をソースコードのみから読み取る必要があり、大きな負担がかかる可能性があります。 テストがきちんと書かれていると、ただソフトウェアの品質を向上させるだけでなく、ソースコードの仕様(期待する処理結果)に関するドキュメントとしての役割も担うため、レビュワーは、その仕様や振る舞いを容易に読み取ることができ、よりコードレビューをしやすくなります。 コードレビューにて実装者のレスポンスが遅い場合、レビュワーは返信が無くて気になったり、コメント内容を忘れる等により、レビューの効率を下げ、大きな負担がかかる可能性があります。 そこで、実装者が簡単かつ最初にできることは、レビュワーによるコメントにいち早く気づくことです。Slackとの連携機能を使用することで、レビュワーによるコメントやレビューを任意のチャンネルへ通知させることができ、少しでも早く返信できるようになります。 今回は、チーム開発において、レビュワーに優しいPull Requestをつくるポイントをまとめてみました。
冒頭でお話ししたとおり、チーム開発ではコードレビューは結構な時間と労力がかかります。裏を返せば、メンバー一人一人がレビューしやすいPull Requestの作成を心がけることで、チームの開発速度が大きく改善する可能性があると思います。 今回紹介させて頂いたポイントを実際の開発現場で試して頂けると嬉しいです。 ここまでお読みいただき、ありがとうございました。
はじめに
今すぐできるレビュワーに優しいPull Requestをつくる7つのポイント
1. WhyとWhatをそれぞれ記載する
2. 説明文は構造化する
### Why
- 実装背景
### What
- 実装内容
- 実装内容詳細(その1)
- 実装内容詳細(その2)
### Ref
- 関連PRへの参照リンク
### Check
- [ ] レビュー依頼前に必ず実施すること(その1)
- [ ] レビュー依頼前に必ず実施すること(その2)
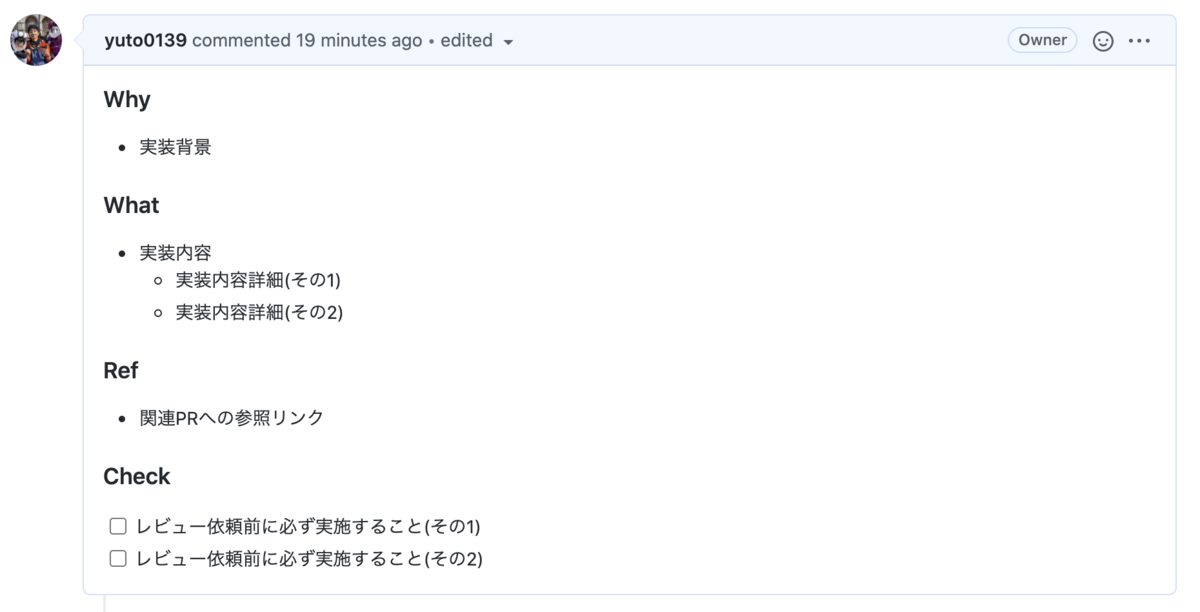
3. コミットは課題を解決した単位で行う
4. Pull Requestは適切な大きさに分割する
5. 個別説明が必要な箇所は積極的にコメントをつける
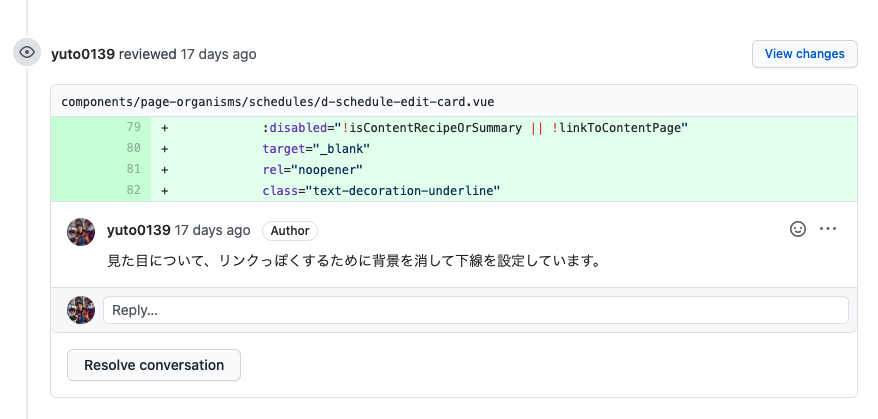
6. テストを書く
7. Pull Requestでのコメントを Slack に通知させる
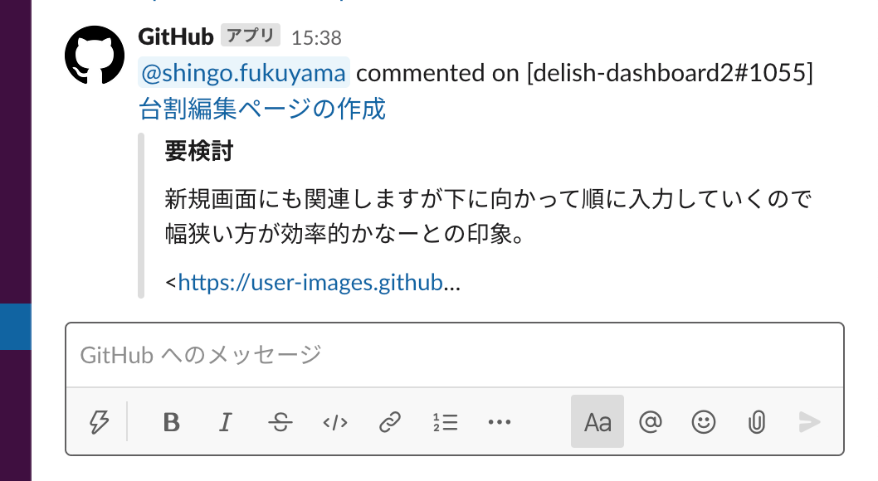
さいごに