
はじめに
こんにちは。DELISH KITCHEN開発部でデータサイエンティストをやっている山西です。
今回は、
- DELISH KITCHENへバンディットアルゴリズムを採用した経緯
- バンディットサーバーおよびそのAWSインフラ構築
をテーマに紹介いたします。
経緯
現在DELISH KITCHENでは、サービスをより良くするために、デザインの改善施策を継続的に行っています。 その手段として、これまでは主にA/Bテストによる効果検証を行ってきました。
参考記事
A/Bテストにより、複数のデザイン案の良し悪しを統計的に解釈し、”良い”デザインを見極めたうえでユーザーに展開することが出来ます。
適切なA/Bテストの設計によってその恩恵を最大限に享受できる一方、トレードオフとして以下のようなデメリットにも直面することとなります。
- 手動操作が多く、”良い”デザインを採用するプロセスを自動化出来ない
- 例
- ユーザーに展開する割合の計算(サンプルサイズの決定)
- サービス内部へのデザイン実装の手間
- 例
- 「良くないデザイン案」を一定期間露出してしまうリスクがある
- 複数のデザイン案を同時にテストしようとすると、サンプルサイズが足りなくなる
そこで、「複数のデザイン案の中から”良い”ものを見つけ出し、自動で表示する」という場面で採用できないかと試したのがバンディットアルゴリズムになります。
バンディットアルゴリズムとは
バンディットアルゴリズムは、探索と活用のジレンマに陥る多腕バンディット問題を効率的に解くために考案されているアルゴリズムです。 まず以下に、これらの用語について解説します。
多腕バンディット問題
以下のような問題設定に当てはまるものを多腕バンディット問題と定義します。
- 「複数の選択肢の中から一つを選択する」試行を逐次的に行い続ける
- 選択を繰り返した結果、得られる総報酬を最大化したい
- 選択試行を繰り返すためのリソースには制約がある(時間的制約、試行回数の上限など)
- どの選択肢が良いか(=多くの報酬を得られるか)は未知である
その具体例として、「当たりの確率が異なる複数のスロットマシンのアーム(腕)を複数回引く中で、最大の報酬を得られるように模索する」問題が挙げられます。

※ スロットマシンがプレイヤーからどんどんお金を奪い取っていく様を盗賊(bandit)に見立てたのが語源となり、多腕バンディット問題と呼ばれるらしいです。
Webサービスの運用においても、「バナーや広告等の表示コンテンツをCTR、 CVRが高くなるように最適化したい」という問題設定等が、多腕バンディット問題に当てはまります。
探索と活用のジレンマ
多腕バンディット問題では「どの選択肢が”良い”(=より多くの報酬が期待できる)のかは事前にわからない」ため、それを試しながら確かめる必要があります。 しかしここで、探索と活用のジレンマに陥ることとなります。
複数の選択肢を代わる代わる試すような”探索”ばかり行っていると、有用な選択肢を発見するまでに機会損失を被るリスクがある
- ex. 新しいスロットマシンを試し続ける、その中には”悪い”スロットも含まれる
とりあえず、とある選択肢を”良い”とみなして活用し続けると、もっと”良い”選択肢があった場合、それを発見できないという機会損失が生じる
- ex. 現時点で一番”良い”スロットマシンを引き続けることになるが、もしかしたら他にもっと良い選択肢があるのを見過ごしているかもしれない
バンディットアルゴリズム
バンディットアルゴリズムは、このような多腕バンディット問題、およびそれに起因する探索と活用のジレンマを解決するためのアルゴリズムの総称です。
これらのアルゴリズムは主に統計的なアプローチを用いて、探索と活用のバランスをうまく取り扱いつつ、総報酬の最適化を図るように設計されています。
代表的なバンディットアルゴリズム
- ε-greedy: シンプルに実装可能なアルゴリズム。小さい確率εをパラメータとし、確率εで選択肢をランダムに選ぶ(探索フェーズ)。残りの確率(1-ε)で、その時点で得られた報酬の期待値が最大となる選択肢を選ぶ(活用フェーズ)。
- Thompson sampling: ベイズによるアプローチ。”良い”選択肢を選ぶために、各選択肢の事後分布(これまでの選択回数と報酬が得られた回数を元に更新)を使用する。
- UCB(Upper Confidence Bound): 試行回数が少ない選択肢の「不確かさ≒”良い選択肢かもしれないというポテンシャル”」も考慮しつつ、”良い”選択肢を探索する。そのために、各選択肢の報酬の期待値の信頼区間の上限(UCB値)を利用する。
本記事では詳細な説明を割愛しますが、詳しく知りたい方は以下の書籍を読んでみてください。
A/Bテストとの違い
A/Bテスト、バンディットアルゴリズムは最終的なゴールとして、「複数の選択肢の中から、最も高い報酬が期待できるものを選びたい」という同じ目標を掲げているように見えます。 しかし、主眼の置き方はそれぞれ、
- A/Bテスト: 検証としての振り返りに重きを置く
- バンディットアルゴリズム: 報酬の最大化そのものを目的とする
という差異があり、それぞれに得意、不得意があるとも解釈できます。
以下、私たちなりの解釈にはなりますが、選択肢を選定するプロセスにおける違いをまとめてみたものになります。
選択肢選定プロセスの比較
| バンディットアルゴリズム | A/Bテスト | |
|---|---|---|
| 目的 | 選定の最適化による報酬の最大化 | どの選択肢が優れているかの判断 |
| 自動化 | される | されない※1 |
| 属人性 | 無し | 有り |
| 効果検証 | やりにくい | やりやすい |
| 環境に対する感度※2 | 高い | 低い |
※1 施策として実施した後に、結果を解釈してどの選択肢を採用するか意思決定することになる
※2 流行の変化によって、”良い”選択肢が変化した場合、バンディットアルゴリズムはその変化を追従できる可能性があるが、A/Bテストはやり直しによってしか対処できない
DELISH KITCHENでは、「複数のデザイン案から”良い”ものを選定する」A/Bテスト以外の選択肢としてバンディットアルゴリズムならではの強みを活かせるのではないかと考え、採用に至りました。
DELISH KITCHENへのバンディットアルゴリズムの適用
これから、DELISH KITCHENにおけるバンディットアルゴリズムの適用事例を簡単にですが紹介します。
ボタン文言の出し分け事例
DELISH KITCHEN(モバイルブラウザ版)のトップ画面には、アプリ版へのダウンロードを促すボタンが設定されています(下図参照)。
ここを、
- 選択肢: ボタンに表示させる文言 (5パターンを準備)
- 報酬: ボタンクリック
という多腕バンディット問題に落とし込みます。
そして、バンディットアルゴリズムによって、ここの文言がクリック率の高いものに寄っていくか実験してみました。
※ Thompson samplingというアルゴリズムを利用
結果
実際に配信してみた結果、最初のうちは複数の選択肢を試し、一定期間経過後、一つの文言(赤色部分)を集中的に表示する様子を観察することが出来ました。
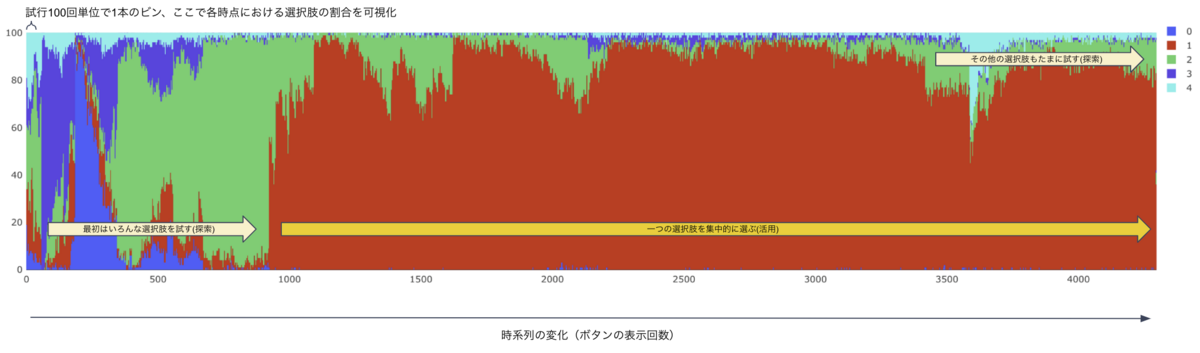
そして、横軸は時系列を表し、右に進むほど時間が経過したことを意味します。
全選択肢(文言)の中で、1番の文言(グラフ上の赤色部分)のクリック率が最も高い結果となりました。
このクリック率は、元々ページ上に表示していた文言(グラフ上の0番=青色部分)よりも1.4倍ほど高いものとなります。
よって、アルゴリズムの探索によって、クリック率観点で”良い”文言を見つけ出したことになります。
バンディットサーバーをAWSに構築
ここからは、バンディットアルゴリズムの実装について紹介します。
- Pythonでバンディットアルゴリズムを実装
- FastAPIにて↑をサーバー化
- AWS上にインフラ構築(FastAPIをコンテナ化してECRにアップロード&ECS-Fargateとして立てる)
という流れを取りました。
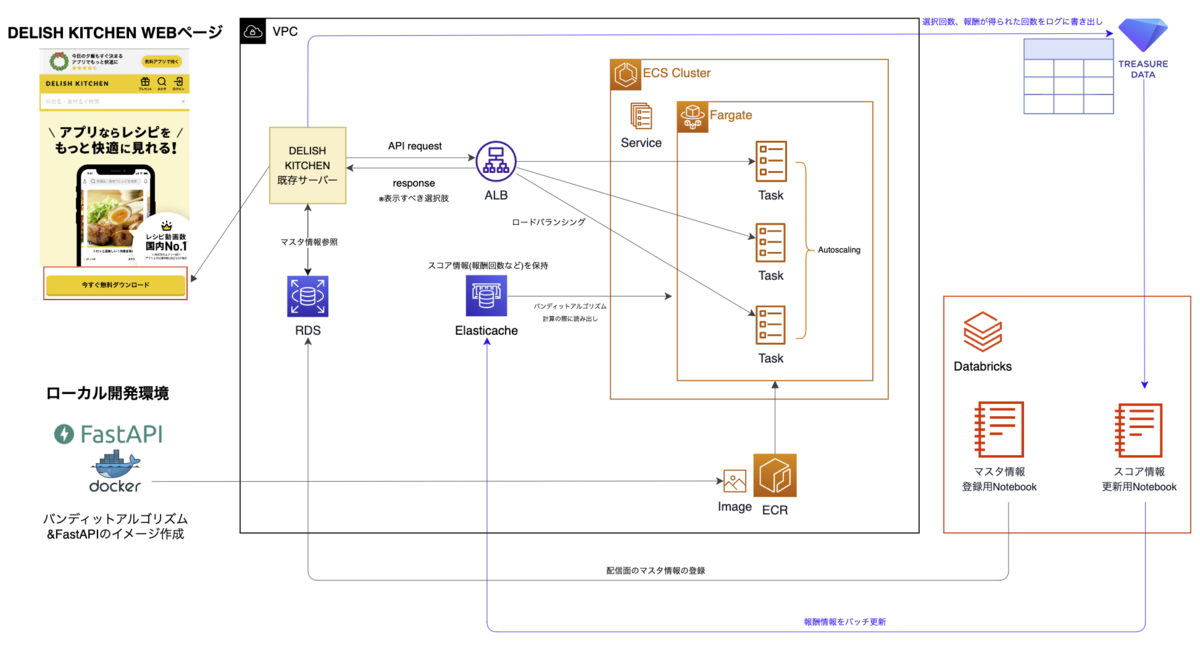
そして、
- 既存DELISH KITCHENバックエンドサーバーがこのバンディットサーバーに対してAPIリクエストを送信
- 「バンディットアルゴリズムの判断結果として、どの選択肢を表示すれば良いか」の情報をレスポンスで返す
- Databricks(データ集計基盤)を経由して、配信に向けたマスタ情報や、バンディットアルゴリズムが必要とする報酬情報等のバッチ更新を実施
という構成にしています。
以下がその構成図になります。
FastAPIコードの例
以下、一部抜粋にはなりますが、バンディットサーバーのコードの実装の雰囲気を紹介します。
内部実装ではMVCアーキテクチャを意識しており、
- service層
- バンディットアルゴリズムのロジックそのもの
- APIとして実現したい操作(コード部分)
- model層
- 必要なデータソース(上記構成図におけるElasticache-redis)を操作する部分
といった具合に各々の責務を分離し、見通しよく開発できるようにしています。
service層のget_arm(APIとしてどの選択肢をリクエスト元に返すかを操作する部分)の実装↓
from typing import List, Dict, Tuple from model.arm import select_arm_score as redis_select_arm_score from model.environment import select_environment_all_arms as redis_select_environment_all_arms from services.bandit_environment import select_bandit_environment from redis.exceptions import RedisError from exception import InvalidIdentifierTypeException, IdentifierNotExistsException, InvalidArmTypeException, ArmNotExistsException # あるidentifier(配信面)が持つ全てのarm(選択肢)のcount(選択回数)とreward(報酬を受け取った回数)を取得 def select_arms_score(identifier:str, arms:List[int]) -> Dict[int, Tuple[int, int]]: try: arms_score = {} for arm in arms: # model層から必要な情報を取得 count, reward = redis_select_arm_score(identifier, arm) # 各選択肢(arm)ごとに、何回選択されたか(count)と、何回報酬を受け取ったか(reward)を格納 arms_score[arm] = (count, reward) except (RedisError, InvalidIdentifierTypeException, IdentifierNotExistsException, InvalidArmTypeException, ArmNotExistsException): raise else: return arms_score # あるidentifier(配信面)が持つ全てのarm(選択肢)の一覧を取得 def select_environment_all_arms(identifier:str) -> List[int]: try: # model層から必要な情報を取得 arms = redis_select_environment_all_arms(identifier) except (RedisError, InvalidIdentifierTypeException, IdentifierNotExistsException): raise else: return arms # 配信面に対してどのarm(選択肢)を返せば良いか、バンディットアルゴリズムに判断させる。 # その際に、count(選択回数)とreward(報酬を受け取った回数)の情報を用いる def get_arm(identifier:str, algorithm:str) -> int: try: # バンディットアルゴリズムのインスタンスを立ち上げる bandit_environment = select_bandit_environment(identifier, algorithm) # identifier(配信面)が持つarm(選択肢)の一覧情報 # およびそれら選択肢に対するscore情報(選択回数:countと報酬回数:reward)を取得 arms = select_environment_all_arms(identifier) arms_score = select_arms_score(identifier, arms) # バンディットアルゴリズムのインスタンスに対して、どのarm(選択肢)を返せば良いかを判断させる arm_number = bandit_environment.get_arm(arms_score) except (RedisError, InvalidIdentifierTypeException, IdentifierNotExistsException, InvalidArmTypeException, ArmNotExistsException): raise else: return arm_number # どのarm(選択肢)にするか、番号で返す
よかったこと
次に、インフラ構築、およびバンディットサーバー内部実装それぞれで責務の分離を意識することで得られたメリットについてまとめます。
DELISH KITCHENサーバーとの責務の分離
DELISH KITCHEN自体のバックエンドサーバーと、バンディットサーバーを切り離して実装したことによって、実装の柔軟性や耐障害性の観点で以下のメリットが得られました。
実装の柔軟性
データサイエンティストがバンディットのロジックのみに責務を持ち、開発リソースを集中できる
- 新しいバンディットアルゴリズムを追加する場面等での拡張性が高い
- DELISH KITCHEN自体のバックエンド実装を意識せず、ロジックに集中してメンテナンスを行うことができる
耐障害性
万が一問題が発生した時にも、事業に与える悪影響を最小限に抑えやすくなる
- 予めDELISH KITCHENバックエンド側にフェールセーフ機構※を備えておくことで、バンディットサーバーへのAPIリクエストに失敗した際でも、ユーザー影響無くサービス運用を継続できる
※ バンディットサーバーとの疎通に失敗した場合、複数選択肢の出し分けは中止し、予め決め打ちしたデザインを表示するように設定しておく等
MVC化による責務の分離
さらに、バンディットサーバー内部実装でMVCアーキテクチャによる責務の分離を意識したことで、可読性、およびコード全体のメンテナンス性が向上しました。
Model層、Service層などの各層の役割が明確に分かれ、各々に対する変更が局在化されるため、システム全体の安定性を保ちつつ
- 新規バンディットアルゴリズムを追加実装する
- データソースを変更する
ことが可能となりました。
大変だったこと
“探索と活用”のテストの難しさ
バンディットアルゴリズムは確率的に生成される情報を取り扱うため、実装したコードの挙動をテストする際はその性質も考慮する必要があります。
以下は、「バンディットアルゴリズムの試行が100回進んだ際、最も”良い”選択肢が最も多く選ばれることを期待する」unittestのコード例となります。
# 試行を進めた結果、最も報酬が得られる確率が高いarm(選択肢)の選択回数が多くなることを確認する。 # 良いarmを探索し、その結果を活用できているかの観点で簡易テスト def assert_most_selected_arm_is_best_arm(self, agent: Union[EpsilonGreedyAgent, ThompsonSamplingAgent, UCBAgent], thetas: Dict[int, float], num_trials=10000): # 最も報酬が得られる確率が高いarm best_arm = max(thetas, key=thetas.get) most_selected_arm = self.get_most_selected_arm_from_bandit_simulation(agent, thetas, num_trials) with self.subTest(test_input=most_selected_arm, expected=best_arm): self.assertEqual(most_selected_arm, best_arm)
def test_exploit_best_arm(self): agent = ThompsonSamplingAgent("test_agent") # 後のシミュレーションにおいて、armから報酬が得られる確率を定義 thetas = {0: 0.1, 1: 0.5, 2: 0.8} # {選択肢の番号:その選択肢から報酬が得られる確率} self.assert_most_selected_arm_is_best_arm(agent, thetas)
このように、アルゴリズムが「良い選択肢によっていく性質」を簡易的にテストしたい場合は、確率的な振る舞いを前提にし、ある種の曖昧さを許容するような視点を求められることがあります。
一方、この粒度の単体的なテストではバンディットアルゴリズムが時間経過と共に、探索と活用のバランスを取るように設計されている(図3で示したような様子)ことを確かめるのは困難です。
さらに、ビジネスシーンで実運用する際は、上記のテストとは異なり、各選択肢から報酬が得られる確率は未知となります。
こうした難しさがあるため、本番環境に投入して経過観察してみないと時間推移的な挙動の確からしさが判別しづらいのが現状です。
そのため、オフライン評価手法をもっと整備しなければならないという課題感を感じているところではあります。
最後に
バンディットの要件整理&アルゴリズムの実装はもちろん、それに留まらずサーバー実装〜AWSインフラを一気通貫で構築した今回の取り組みは、データ職責として挑戦的な機会となりました。
慣れない技術スタック、苦労も多くあったものの、
- MLをどうサービスに組み込むか
- そのために如何にして開発サイドのエンジニアと連携するか 等の視座を上げることができ、非常に有意義な経験となりました。
また、バンディットアルゴリズムの導入により、「サービス内の表示コンテンツを最適化する手段」としてA/Bテスト以外の選択肢が加わることとなりました。
今後は、検証の目的によってA/Bテストとは使い分けつつ、バンディットアルゴリズムの利用拡大や文脈付きバンディットへの拡張などに取り組んでいきたいと思います。
参考書籍
飯塚 修平. 2020. ウェブ最適化ではじめる機械学習―A/Bテスト、メタヒューリスティクス、バンディットアルゴリズムからベイズ最適化まで. オライリージャパン.