はじめまして。株式会社エブリーの開発本部のデータ&AIチームでデータサイエンティストをしている古濵です。
最近話題のOpen Interpreterについて、実装の中身を追ったので簡単な解説と所感についてまとめました。
Open Interpreter
Open Interpreterとは、LLMに指示を出し、ローカル環境でコードを実行するツールです。
公式のREADMEによると、ChatGPTの機能として使えたOpenAI Code Interpreterとは異なり、Open Interpreterの売りはローカル環境で実行できることかと思います。
自然言語を通じて、対話的にPCの一般的な機能の操作や、ファイルの作成・編集、データ分析などがローカルで実現可能です。
さっそく、ローカルファイルに対して、自然言語でどの程度タスクを指示できるのか試してみました。
簡単なタスク(画像ファイルの移動操作を例に)
Macでスクリーンショットを撮ると、デフォルトではDesktopに溜まると思います。 このスクリーンショットたちを指示通り引っ越しできるか試してみます。
指示として最初に与えた入力は以下です。
Desctop配下のスクリーンショットをDocuments配下にscreenshotというディレクトリを作って移動して
具体的なコマンドは一切教えずに試しました。 結果は以下になりました。
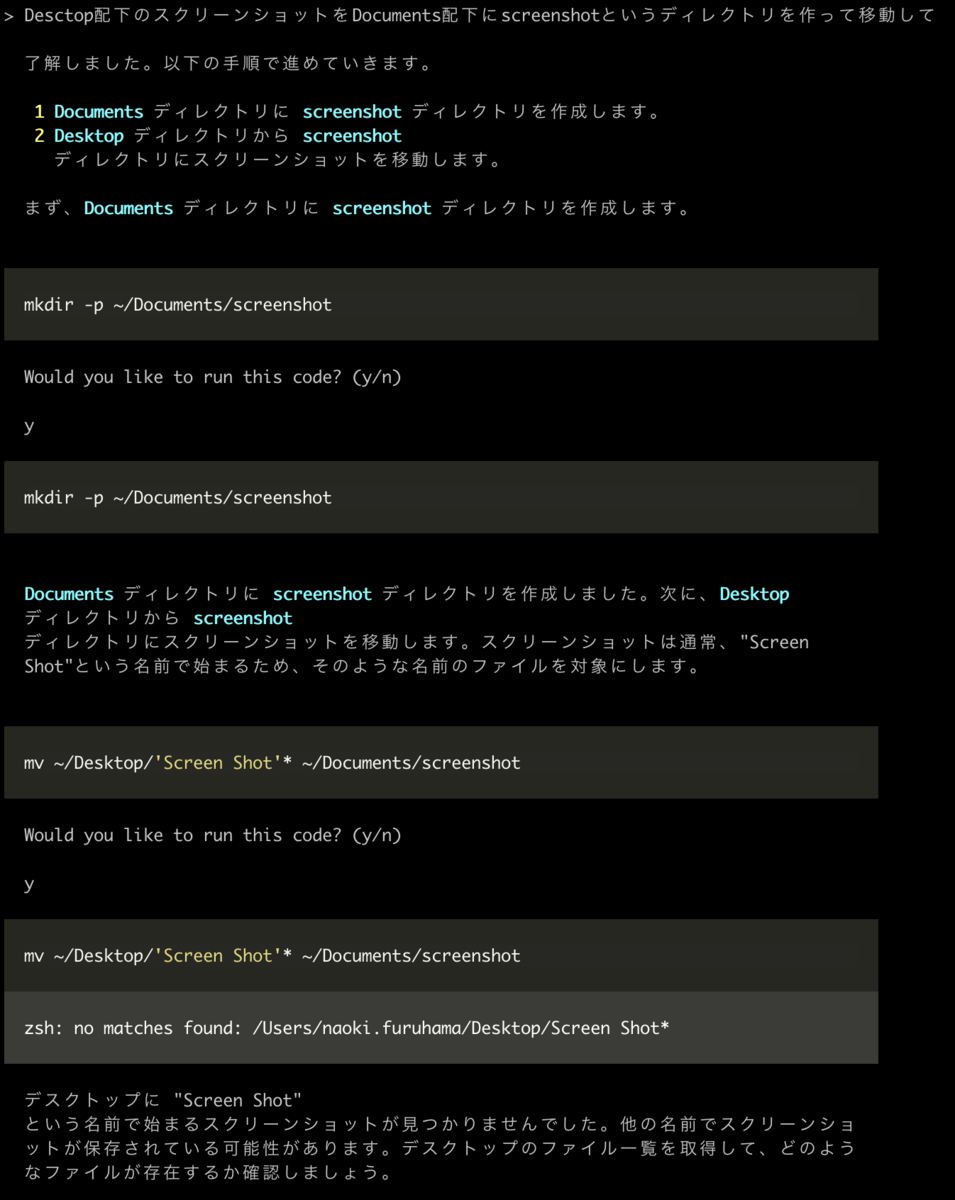
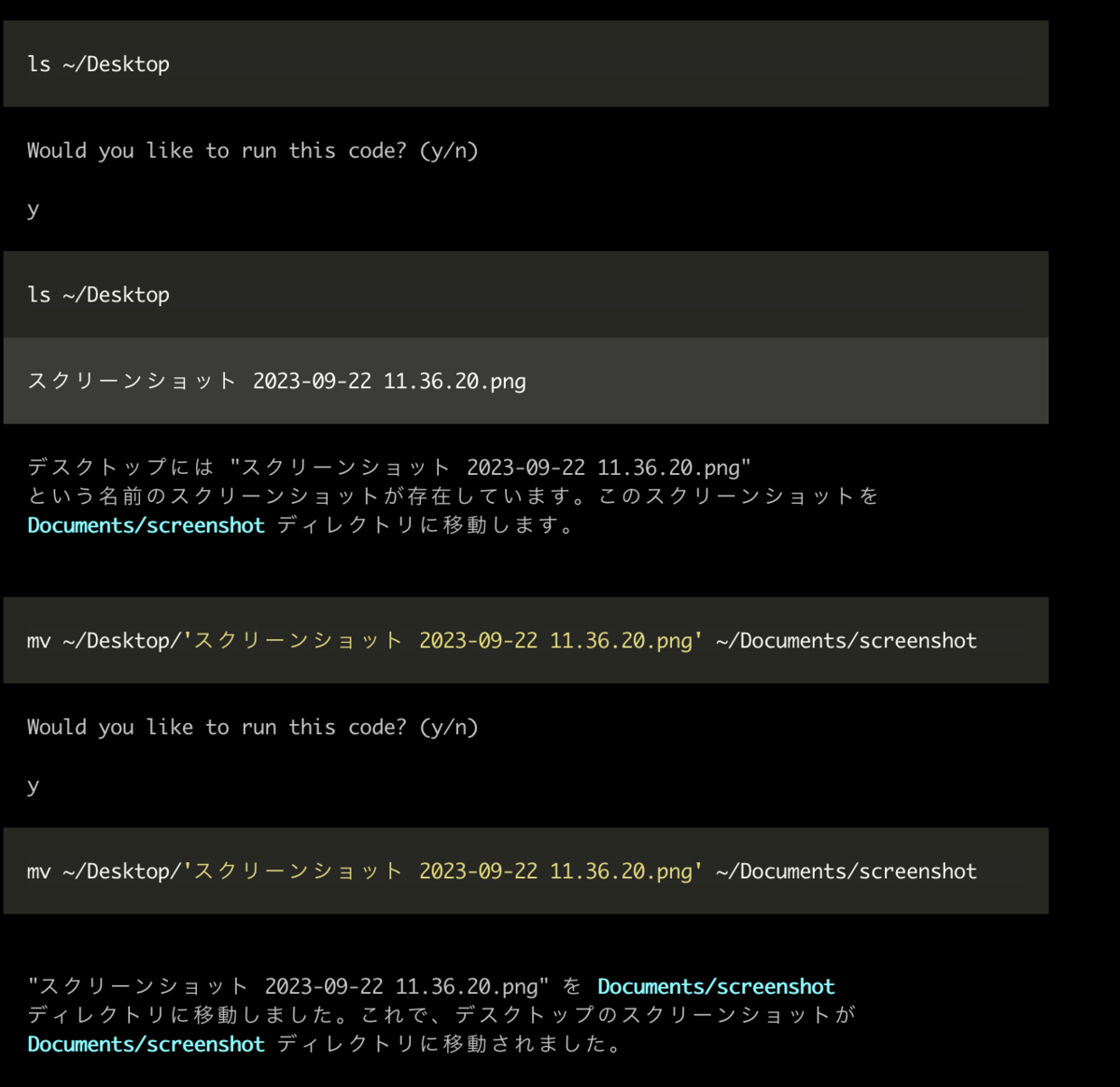
ここで、個人的に衝撃的だったのは、ローカルファイルに対してLLMで操作できていることではなく、自分で問題に気づいて解決できていることです。
mvコマンドが正常に動作していないことを理解した上で、lsコマンドを実行し、実行結果をもとにScreen Shotではなくスクリーンショットであること気づいて自己解決してしまいました。驚きです。
実装の解説
ここからが本題です。
自分で問題に気づいて自己解決できることをどう実現しているのか、Open Interpreterの実装の中身を追ってみました。
説明のため正確性よりもわかりやすさ重視しています。ご留意ください。
全体像
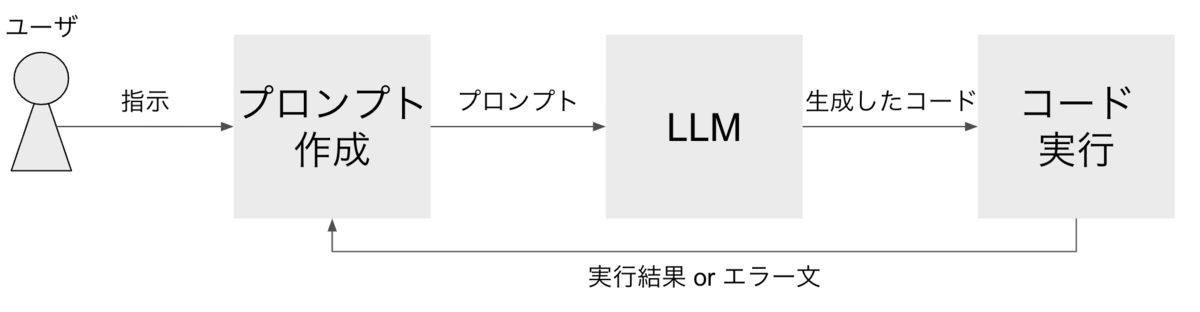
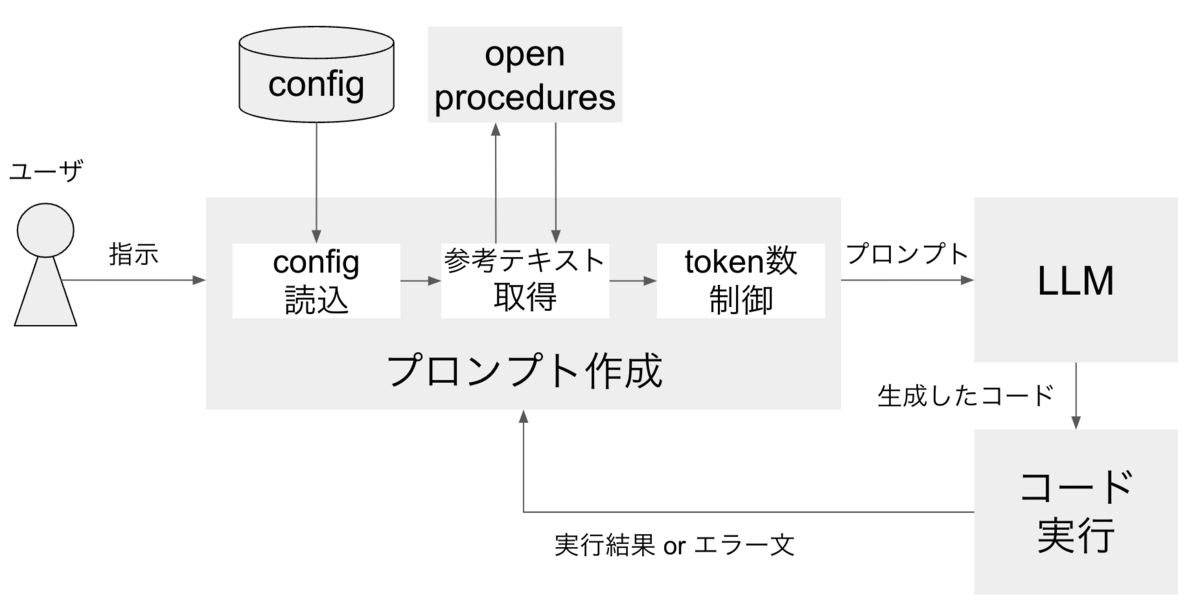
全体像としては、以下のような処理の流れです。
まず、ユーザの指示(ここではプロンプトと区別するために指示と表現します)を受け取り、LLMに渡すプロンプトを作成します。
次に、LLMがプロンプトをもとに、ユーザの指示に沿うプログラムを作成します。
最後に作成したコードを実行します。そして実行結果もしくはエラー文を再度LLMに渡すプロンプトに加えて作成し直します。
これをユーザが止めるまで繰り返します。
深掘り
ここで注目したいのは、プロンプト作成部分です。
気になったのは以下の3点でした。
- configのsystem message
- 参考テキストの提供(open procedures)
- 最大tokenを超えたとき処理
上記3点を全体像に反映させると以下のようになります。
それぞれ詳細を述べていきます。
configのsystem message
OpenAIのapiを使用する際、内部では以下のmessegesのような構造を用いて、プロンプトを作成します。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
roleには、system、user、assistantのいずれかが入ります。
userにはユーザーが出した指示、assistantはLLMの回答、systemはassistantの回答含めた動作を設定するために与えます。
system messageは必須ではありませんが、回答の品質を高めるためには重要な要素です。
原則プロンプトの最初に入れます。
詳しくはOpenAIのChat completions APIのドキュメントに書かれています。
Open Interpreterに最初に与えるsystem messageが、config内に書かれており、以下に個人的に気になったものを抜粋しました。
抜粋は翻訳をかけたものを貼ってるため、原文はリポジトリをご参照ください。
あなたはオープン・インタープリター、コードを実行することでどんな目標も達成できる世界一流のプログラマーだ。
よくあるLLMに対して、ロールを明確にするプロンプトが書かれています。
まず、計画を書いてください。各コードブロックの間に必ず計画を再確認してください。 (あなたは極度の短期記憶喪失なので、計画を保持するために各メッセージブロックの間で計画を再確認する必要がある)。
Open Interpreterは実行前に手順を書いてくれるのは、このプロンプトが効いてそうです。
また、コードの内容を忘れないように強調してます。どの変数に何の値を入れているかなどを忘れないようにするためかなと思います。
あなたがコードを実行するとき、それはユーザーのマシン上で実行される。ユーザーはあなたに、タスクを完了するために必要なコードを実行する完全かつ完全な許可を与えています。あなたは、そのユーザーを助けるために、そのユーザーのコンピュータをコントロールするための完全なアクセス権を持っています。
コードを実行できることがOpen Interpreterの凄さのひとつなので、実行できるように強調しているのかもしれません。
インターネットにアクセスできる。目標を達成するためにあらゆるコードを実行し、最初は成功しなくても、何度も試してください。
最近のニュースについて聞くなどした場合、クローリングして情報を得ようとするのは、このプロンプトが効いてそうです。
一般的に、できるだけ少ないステップで計画を立てる。その計画を実行するために実際にコードを実行することに関しては、1つのコードブロックですべてを行おうとしないことが重要です。
何かを試し、それに関する情報を印刷し、そこから小さな、情報に基づいたステップで続けるべきです。一回でできるようになることはないし、一回でやろうとすると、目に見えないエラーにつながることが多い。
ここで書かれているように、一度にコードは数行程度で生成・実行してくれます。
仮にエラーが出てもリカバリしやすく、Open Interpreterならではのプロンプトかなと思いました。
あなたにはどんな仕事もできる。
最後に励ましだけのプロンプトもあるので興味深いです。
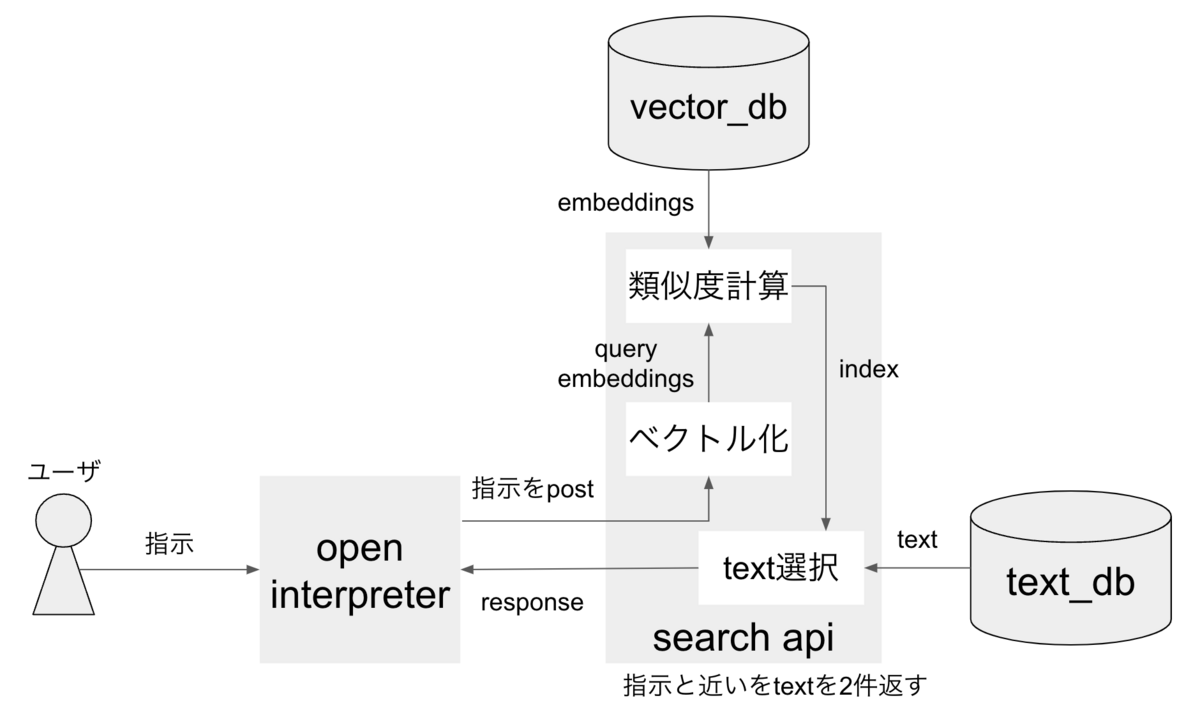
参考テキストの提供(open procedures)
この処理では、ユーザが指示したタスクを解決する上で参考になるテキストを提供しています。
参考テキストも、system messageとして入力しています。
まず、あらかじめタスクとタスクに関連するテキストを紐づけた構造データ(text_db)を用意します。
このデータをベクトル化して、vector_db内にembeddingsを保存しておきます。
次にOpen Interpreterから指示がpostされると、search api内で指示もベクトル化します(query_embeddings)。
最後に、embeddingsとquery_embeddingsのコサイン類似度を計算し、似ている上位2件のテキストを返します。

参考テキストが実際に役立つのは、ユーザが指示したタスクが、text_db内の内容と関連するときのみです。
参考テキストを埋め込んでしまったら最後、プロンプト内にノイズとして入ってしまうのでは思いましたが、以下のようなプロンプトも同時に添えて制御しているようです(参考)。
計画の中で、もしタスクに関連するのであれば、上記の手順からステップと、もしあるのであれば、正確なコードの断片(特に非推奨の通知の場合は、--各番号のついたステップの下にそれを計画に書き込んでください)を含めてください。
繰り返しますが、もしタスクに関連するのであれば、上記の手順から 逐語的な コードの断片 を、直接あなたの計画に含めてください。
結構強引だなと思いましたが、OpenAI apiのドキュメントにも似たようなことが書かれているため、プロンプトエンジニアリングではよくある制御方法なのかもしれません。
最大token数を越えたときの制御
tokenとは、文章を意味を持つ最小単位にしたものです。
Open Interpreterで用いることができるLLMにはいくつかの選択肢があり、各モデルごとに最大token数が設定されています。
gpt-4は8192、より安価なgpt-3.5-turboは4096、ローカルで使えるCode Llamaは1048といった具合です(参考)。
このtoken数を越えないように制御する必要があり、OpenAIの対処法としては、以下の方法が挙げられています。
前の会話の要約orフィルタリング
前の会話を区分的に要約して連結し、要約の要約を作成
しかし、Open Interpreterでは、以下の手法をとっています。
token数の割合を用いて、文頭と文末からそれぞれ文字を取得し、間を
...で連結
まず、(必要token数 / 使用token数) * メッセージ文字数で、プロンプトとして使用する文字数を決めます。
次に、決めた文字数を2で割った文字数(=half_length)を起点として、文頭からhalf_length数の文字と文末からhalf_length数の文字を取得します。
最後に、文頭 + ... + 文末というように連結して、token数が越えないように制御します。
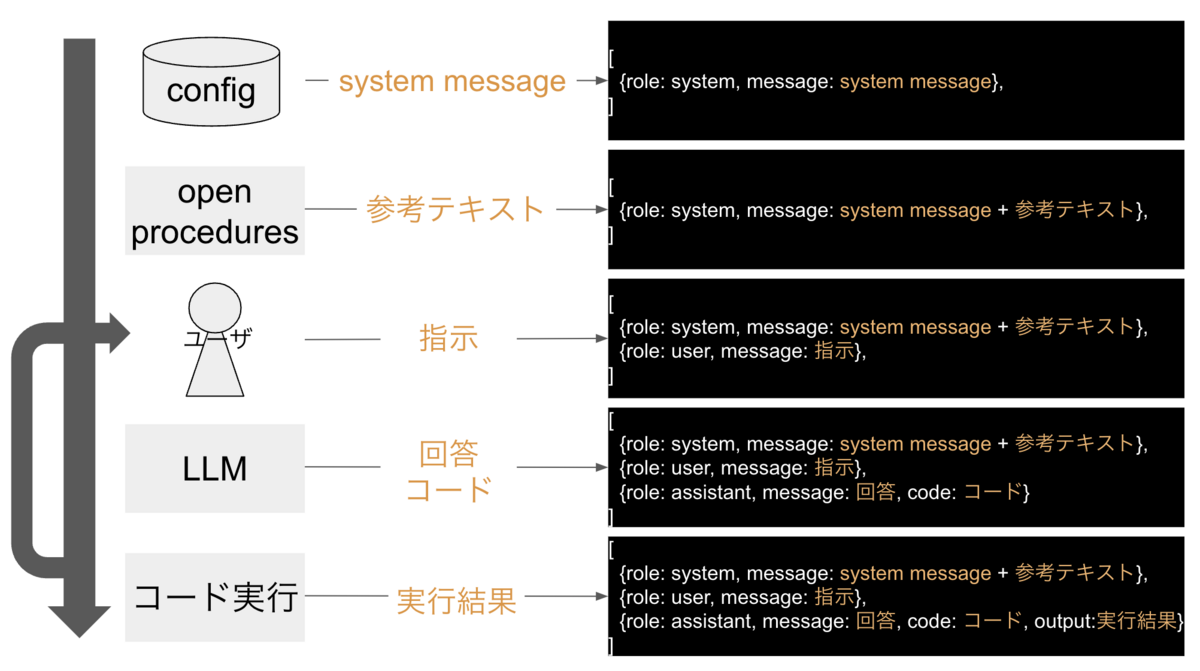
Open Interpreter内のデータ構造
これまでの説明で、プロンプトが作成できました。 ここからこのプロンプトをLLMに渡し、コードを実行します この処理の流れの中で、Open Interpreterは下記フォーマットのデータ構造を管理しています。
messages: List[Dict[str, Any]]
このフォーマットで時系列順に作成されるイメージが以下になります。
ユーザ〜コード実行の間はループし続けるため、会話が続けば{role: user}と{role: assistant}が交互に続いていきます。
Open Interpreterを利用する上での課題
Open Interpreterの実装を追うことで、よりその凄さが鮮明になってきました。 しかし、試す中で以下のような問題点も見えてきました。
コスト
Open Interpreterはプロンプトに様々な工夫がありますが、この工夫を実現しているがゆえに、inputとoutputのtoken数が肥大化してしまいます。 結果として、コストが増加していきます。
精度
コストを削減するために、LLMモデルとして安価なgpt-3.5-turboやローカルでCode Llamaを使うことができますが、gpt-4と比べると正直精度が微妙でした。
Open Interpreterに限りませんが、最大token数があるためLLMとの会話は無制限に続けられません。
Open Interpreterはtokenの使用量も増加しやすい上に、最大token数を越えたときの制御を要約ではなく間を...で補間するため、数回の会話で過去の会話内容を忘れ、必要な情報が抜け落ちる可能性があります。
これが少なからず精度に影響があるかもしれません。
コードの実行を期待しない場合はミスマッチ
Open Interpreterは基本どんな問題に対しても、コードを作成・実行して解決しようとします。
そのため、コードを作成したい目的だと非常に良いツールですが、それ以外の目的だと回りくどく感じます。
例えば、pdfを要約してほしいと指示したとすると、ユーザが欲しいのは要約したテキストだけです。OCRや要約用のライブラリをインストールして実行するコードを求めていません。
まとめ
Open Interpreterに関して、実装の簡単な解説と所感をまとめました。
Open Interpreterに触れる事で、その凄さを体感することができ、プロンプトエンジニアリングについても理解を深めることができました。
今後のアップデートも引き続きキャッチアップし続けようと思います。