
こんにちは。ビッグデータ処理基盤の物理レイヤーから論理レイヤーの設計実装、データエンジニアやデータサイエンティストのタスク管理全般を担当している、Data/AI部門の何でも屋マネージャの @smdmts です。
この記事は、弊社のデータ基盤の大部分を支えるDelta LakeとLakehouseプラットフォームによるデータウェアハウス設計の紹介です。 Databricks社が主体となり開発しているDelta Lakeをご存じでしょうか?
Delta Lakeは、Apache Sparkを利用したLakehouseプラットフォームを実装可能とするオープンソースです。 Lakehouseプラットフォームの詳細は、こちらの論文に記載されています。 Lakehouseプラットフォームとは、一つのデータレイクのプラットフォームにETL処理、BI、レポート、データサイエンス、マシンラーニングを搭載することで、性能面やコスト面・仕様変更に強いなど、多方面で有利に働くとされます。
Delta Lakeとは
Delta Lakeは、以下の公式サイトのdelta.io の図にあるとおり、S3やGCSなどのストレージレイヤーに機械学習や目的別に特化したデータ構造のアーキテクチャパターンです。 Delta Lakeは主にApache SparkからのRead/Writeをサポートしていますが、制約つきでPresto/Athenaによる読込もできます。
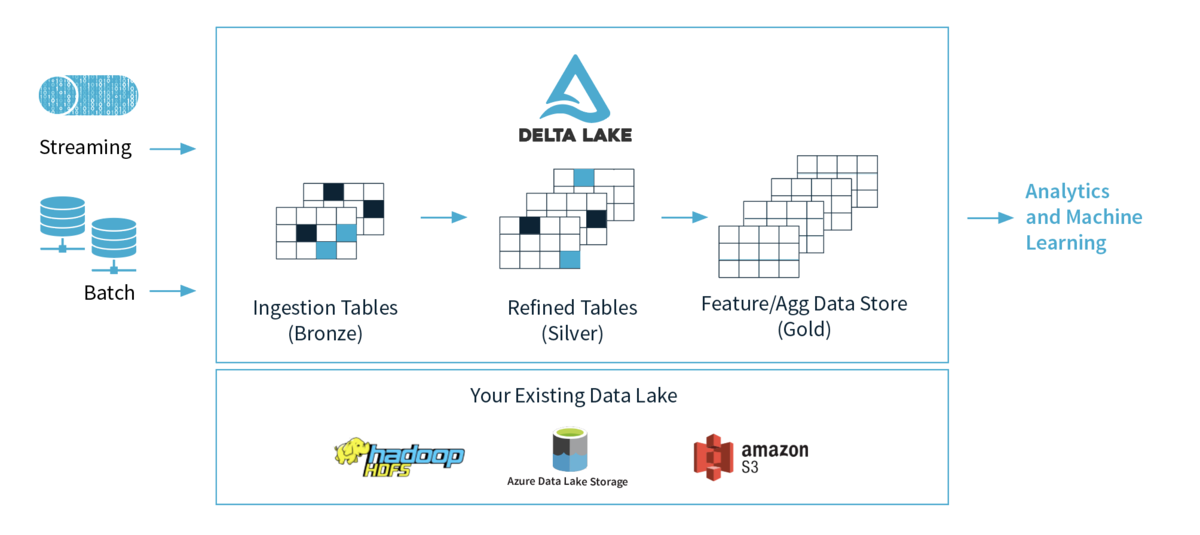
公式サイトで紹介されている以下の動画によると、Delta Lakeを利用した場合のデータ構造を、以下のように、Bronze、Silver、Goldと定義される三段階に構造を分離すると、より信頼性の高いデータレイクの構築可能にするとされます。
| ステージ | データの内容 |
|---|---|
| Bronze | Ingestion Tablesと呼ばれる、生ログを保存するステージ |
| Silver | Refined Tablesと呼ばれる、Bronzeテーブルをクレンジングした中間テーブル |
| Gold | Feature/Aggregation Data Storeと呼ばれる、目的別に特化したテーブル |
Delta LakeとLakehouseプラットフォーム
Delta Lakeに関わらずデータレイクで何らかのデータを取り扱う場合、アプリケーションのドメイン知識の考慮が必要です。 一般的なアプリケーションでは、ドメイン知識の原料となるユビギタス言語を元にデータモデルの設計がされますが、イベントソーシングを利用しない限り、ドメインモデルが出力するデータモデルの変更は可能です。 たとえば、DELISH KITCHENは、レシピ動画を視聴出来るサービスですが、「動画」と「レシピ」などのコアとなるドメインモデルがある事に対して、仕様変更などで「レシピ」に何らかの新しい付加情報となるデータモデルの変更や追加は可能です。
一方でデータ基盤におけるドメイン知識とは、KPIやKGIなどの観測したい対象を指します。 たとえば、動画におけるデータ分析のドメイン知識では「視聴数」や「視聴維持率」などがその対象となります。
データウェアハウスで管理されるイベントログは、基本的に過去に保存したデータモデルの変更は許されず、将来仕様変更が発生した場合でも、データ構造はKPIなどの観測したい事象に追随する必要があります。 そのため、以下のように各ステージ毎の領域別でドメイン知識の保有などの考慮が必要となります。
- Bronzeステージ(生ログ)
- データソースから発生するデータ構造を極力変更しないデータ領域
- 基本的に生ログで最小限の構文解析のみ行いドメイン知識を有さない
- Silverステージ(クレンジング/一次集計テーブル)
- データ構造の仕様変更などに追随するバッファーとなるデータ領域
- BronzeステージとSilverステージのデータを集計対象とする
- 生ログからイベント毎に分割するなど最小のドメイン知識を有する
- Goldステージ(最終集計テーブル)
- ビジネス上の価値が観測できる多くのドメイン知識を有するデータ領域
- SparkやPrestoなどから読み込まれる
- BIツールやMLなどから利用し、エンドユーザーの知識や知恵となり得る
このように各ステージ毎にデータが持つ役割を明確にすると、観測対象となるドメイン知識の全てがGoldステージに集約されます。 また、ドメイン知識の原料となるデータとして、SilverステージとBronzeステージにデータが保存されると明文化されます。
Bronzeステージには生ログが保存され、Silverステージにはイベント毎などで分割された最小限の粒度となるドメイン知識を有するデータが保存されます。 データが保持する情報の抽象度はBronze、Silver、Goldの順番に上がり、最終的にビジネスに何らかの役に立つドメイン知識となる情報がGoldステージで参照可能となります。
Lakehouseプラットフォームのアーキテクチャは以下の図の通り、データレイクに対して一つのエンドポイントでさまざまなデータを参照可能とする仕組みです。 データレイク内のデータをドメイン知識の保有の有無など抽象度の異なるデータをBronze、Silver、Goldと分離すると、データガバナンスに良い影響をもたらす事が期待できます。

Delta Lakeと関心の分離
ビッグデータの処理基盤は入力元となるデータ源泉は多種多様でカオスになりがちですが、Lakehouseプラットフォーム内のデータ構造をBronze、Silver、Goldの各ステージでデータを蒸留すると、関心の分離が促進されます。 関心の分離はSoC(Separation of Concerns)とも呼ばれ、オブジェクト指向設計やモジュール設計で重要とされる「凝集度」や「結合度」の観点から重要な概念です。
Delta Lake内の各データ領域を利用者別に分類すると、以下のように分離できます。
Bronzeステージ(生ログ)
- データ入力部分を処理担当するインフラエンジニア
- SaaSによる外部入力データ連係を担当するデータエンジニア
Silverステージ(クレンジング/一次集計テーブル)
- ドメインモデルを構築するデータエンジニア
- 自分が担当したアプリ成果を確認するアプリケーションエンジニア
- 探索的データ分析を行うデータサイエンティスト
- 目的となるKPIの検討を行うプロダクトマネージャ
Goldステージ(最終集計テーブル)
- 機械学習のモデル精度をチューニングするデータサイエンティストや機械学習エンジニア
- 対顧客や経営層へのレポーティングを行うデータアナリスト
- 日々のKPIを観測する事業責任者や経営者、プロダクトマネージャ
データ領域における関心の分離は、各ステージのデータ設計や最終的な可視化対象の選定に当たる洞察に良い影響を与えます。 たとえば、アプリケーション開発者が開発した機能の状況を把握するためにはSilverステージを参照すれば、機能が正常に動作しているかを把握できます。 また、達成されるべきKGIに因果関係があるKPIがはっきりしない場合は、Silverステージのデータから探索的データ分析によりKPIの検討が可能です。
データが保持する抽象度がBronze、Silver、Goldと順番に上がることの裏返すと、Gold、Silver、Bronzeの順番にデータ量が増え探索可能となる情報が増えるということです。 一度集計してしまうと集計前のデータが欠落してしまうことから、新たな洞察を得たい時にはSilverステージより前のデータを利用したい場合もあります。 Goldステージのデータは特定の目的以外のデータは保持しないことからデータの持つ柔軟性は低いです。 観測したいKPIが未知の場合は、前ステージのSilverステージやBronzeステージのデータを集計し、Goldステージに昇格させるべきか検討する必要があります。
実際のアプリケーション運営の現場ではLTVなどのKGIに因果関係があるKPIを試行錯誤して発見に至るケースも多く、しばらくの間はBIツールからはSilverステージのテーブルをスキャンする事も珍しくありません。 一方でSilverステージはGoldステージと比較してデータ量が多くなることから、計算量や処理コストの観点では不利に働きます。 そのためSilverステージのスキャンで観測したいKPI決まると、Goldステージのデータを作成するバッチを作成し、BIツールからはGoldステージのテーブルを参照するようになります。
このように、データが保持する主な情報を各ステージ毎に分離すると、データ軸でも利用者毎の関心の分離が促されます。 「システムを設計する組織は、その構造をそっくりまねた設計を生み出してしまう」とコンウェイの法則の有名な一説がありますが、データ構造とその配置を定義するだけで、利用者毎の関心が綺麗に分離するのは興味深い事例ではないでしょうか。
Delta Lakeがデータレイクにもたらす恩恵
今回はDelta Lakeの機能詳細に触れませんでしたが、Delta LakeにはUpsertを可能とするMerge文、過去に保存した時点のデータに巻き戻すTime Travelなど様々な便利な機能が実装されており、Bronze、Silver、GoldのステージのETL処理を強力にサポートします。 たとえば、Bronzeステージは生ログのためアプリケーションの実装の都合で頻繁にカラム追加などのデータ構造が変更されますが、自動的にスキーマの変更を検出してマージするスキーマオートマージ機能は非常に便利です。
私が所属するデータ/AI部門のデータ基盤では、一部の機能をDelta Lakeを利用したLakehouseプラットフォームで実装していますが、仕様変更が頻繁に発生するデータ領域でもアジリティ高く即日〜三営業日程度で観測したいKPIを追加できる状況が実現できています。
データ構造をBronze、Silver、Goldとステージを分解するだけでも、データ利用者の関心の分離を促し、データガバナンスにも数多くの恩恵をもたらすため、データウェアハウス設計の参考にして頂ければ幸いです。
ここまでお読みくださり、ありがとうございました。