 # Apache AirflowのPoCをした話
# Apache AirflowのPoCをした話
はじめに
弊社『DELISH KITCHEN』のデータプラットフォーム上では、日々発生するデータをLakehouseプラットフォームに集約しており、Databricks上で処理される多数のETLジョブが存在しています。しかし、現在利用しているジョブ管理ツールでは、Databricksのジョブ同士の依存関係を細かく設定することが出来ず、実行ジョブが肥大化してしまう問題があります。
これらを適切な粒度で依存関係を設定出来るようにするため、DAGによるワークフロー定義が可能なApache Airflowを導入しました。その際に行ったPoCでの所感をお話します。
Lakehouseプラットフォームについてはこちらの記事で紹介されています。
Delta LakeとLakehouseプラットフォームによるデータウェアハウス設計
現状
Databricks Jobsによる管理
弊社ではデータ分析基盤として主にDatabricks を利用しており、ETLバッチジョブの多くをDatabricks Jobs を用いて管理・運用しています。
ETLバッチジョブの各タスクの依存関係や実行順を定義するワークフローは、DatabricksのNotebook上で定義されます。これらのジョブのスケージュール、アラートなどの設定はDatabricks JobsのWeb UI上から行っています。
これらのジョブは次のサンプルコードのように、Notebook上で定義して処理されます。
// Bigqueryからイベントの生ログを転送し、イベント毎に保存するジョブ // task01,02が順次実行される dbutils.notebook.run("./bronze/01_ExtractEventDataFromBQ") dbutils.notebook.run("./silver/02_TransferAppEventToDelta")
次の図のように、Web UI上からスケージュールなどの設定をします。
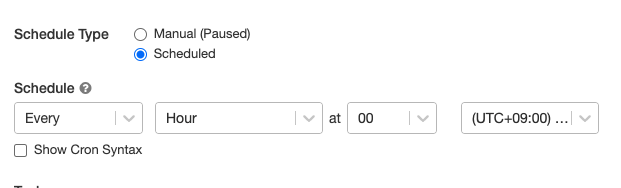
実際のアプリケーションのジョブでは、以下のようなデータ処理が実行されています。
- BigQuery上のApp/Webのイベントの生ログを転送後、イベント毎に分解して保存
- S3上に保存されるサーバーログをイベント毎に保存
- 各事業部のKPIを計算
Databricks Jobsによるジョブ管理の問題点
これらのDatabricks Notebookで処理されるジョブには、ジョブ間の依存関係を設定できない問題が存在します。この問題は、処理方式がCRONとなっており、時間制御によるジョブスケジュール管理ツールのため、他のジョブの状態を考慮していないことから発生しています。
ジョブの完了をトリガーとしたジョブの実行ができず、トリガーとなるジョブのワークフロー内に後続ジョブの実行を定義する必要があります。
ジョブのワークフロー内に別のジョブ実行を定義することは、本来ジョブが持つ関心事を曖昧にし、データワークフローの見通しが悪くなるだけでなく、データワークフロー管理の観点やジョブ肥大化の観点などにおける様々な問題を引き起こします。
例えば以下のような3つのジョブがあるとします。
- アプリのログを保存する
- アプリ内検索のKPIを計算する
- アプリ内課金のKPIを計算する
検索、課金のKPIを計算するジョブは、アプリログを保存するジョブの完了を実行条件として要求します。
3つのジョブの流れを図に起こすと次のようになります。
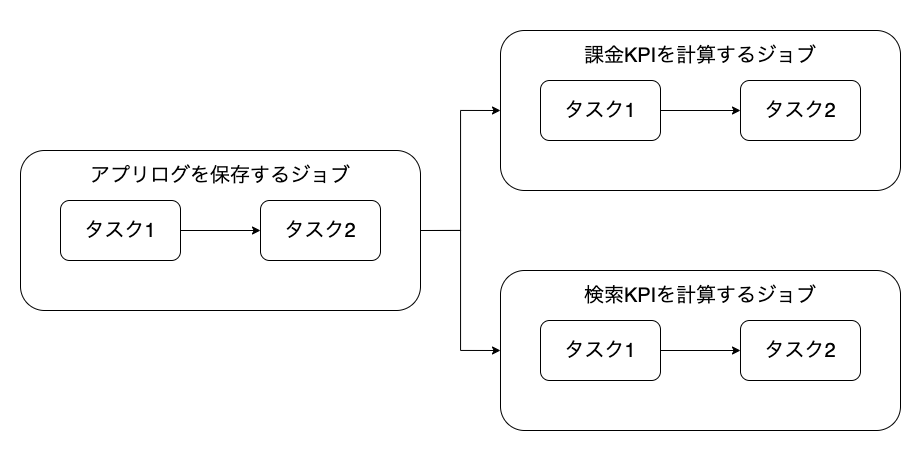
各ジョブには論理的な繋がりがなく、関心事毎に個別のジョブとして定義・管理されている状態が望ましいですが、Databricks Jobsでは依存関係の設定ができないため、本来は個別に定義されるべきジョブが1つのジョブとして定義されてしまいます。
例えば、アプリログを保存するジョブの完了をトリガーに、各KPIを計算するジョブの実行が不可能なため、1つのジョブ内でそれぞれのジョブを定義することになります。
次の図はそれぞれのジョブが同一のノートブック内に1つのジョブとして定義されている状態を表します。
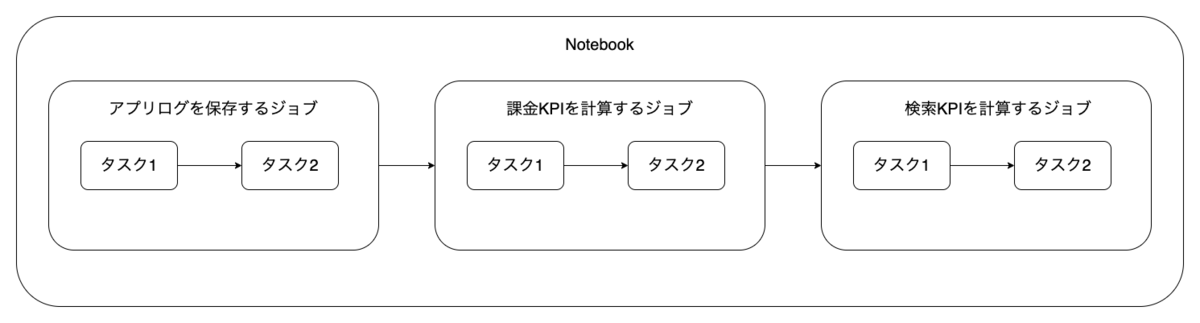
単一のジョブとして定義された各ジョブは、順次実行されるため実行時間が長くなるだけでなく、ジョブ毎に要求される適切な計算資源の割当ができません。そのため最も重い処理に要求される計算資源を長時間使い続けることになります。大きな計算資源を長時間使用することは、ジョブの運用に要求されるコストを増加させるため望ましくありません。
例えば、KPIの計算はアプリログを保存するジョブと比較して計算資源を要求しませんが、ジョブをまとめて定義してしまったことで、必要な計算資源よりも大きな計算資源が割り当てられてしまい、不必要なコストの増加が起こります。
このように、関心事によって適切な粒度でジョブを分割し定義されていない状態は以下のような問題を引き起こします。
- ジョブの肥大化による実行時間の長期化
- ジョブの計算量に応じた適切な計算資源の分配ができない
- 上記2つに起因するコストの増加
- 将来的なワークフロー変更に対応できない
- データワークフローの見通しの悪化
Apache Airflowの導入
ジョブ間の依存関係を設定できない問題を解決するため、Apache Airflow を導入します。
Apache Airflowはジョブ間の依存関係を設定できるだけではなく、GCP、AWS、Databricksなどの弊社で利用している様々なサービスへのタスク実行をサポートしているため、検討することにしました。
Apache AirflowではETLバッチジョブのワークフローをDAG(有向非巡回グラフ) として、1つのPythonファイルで定義します。これらのジョブのスケジュール、アラートなどの設定もDAGを定義したPython ファイル内で定義され、ワークフローだけではなくジョブの設定を含めたコードベースでの管理が可能です。
次のサンプルコードのように、Databricks上のジョブを実行するDAGを定義できます。
# need pip install airflow==2.0.2, apache-airflow[databricks]==2.0.2 import datetime from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator, DatabricksSubmitRunOperator from airflow.utils.dates import days_ago cluster_settings = {} with DAG( # アラート、スケジュールを設定 dag_id='example_databricks_jobs', default_args={ 'owner': 'admin', 'depends_on_past': False, 'email_on_failure': False, 'email_on_retry': False, 'retries': 2, 'retry_delay': datetime.timedelta(seconds=10) }, schedule_interval='@hourly', start_date=days_ago(2) ) as dag: task1 = DatabricksRunNowOperator( task_id='run_now_operator', job_id='65', # databricks > jobs > job ID notebook_params={'env': 'prd'} ) task2 = DatabricksSubmitRunOperator( task_id='submit_run_operator', json={ 'notebook_task': { 'notebook_path': 'Product/bronze/01_ExtractEventDataFromBQ', 'base_parameters': {'env': 'prd'} }, 'new_cluster': cluster_settings } ) # ワークフローを定義 task1 >> task2
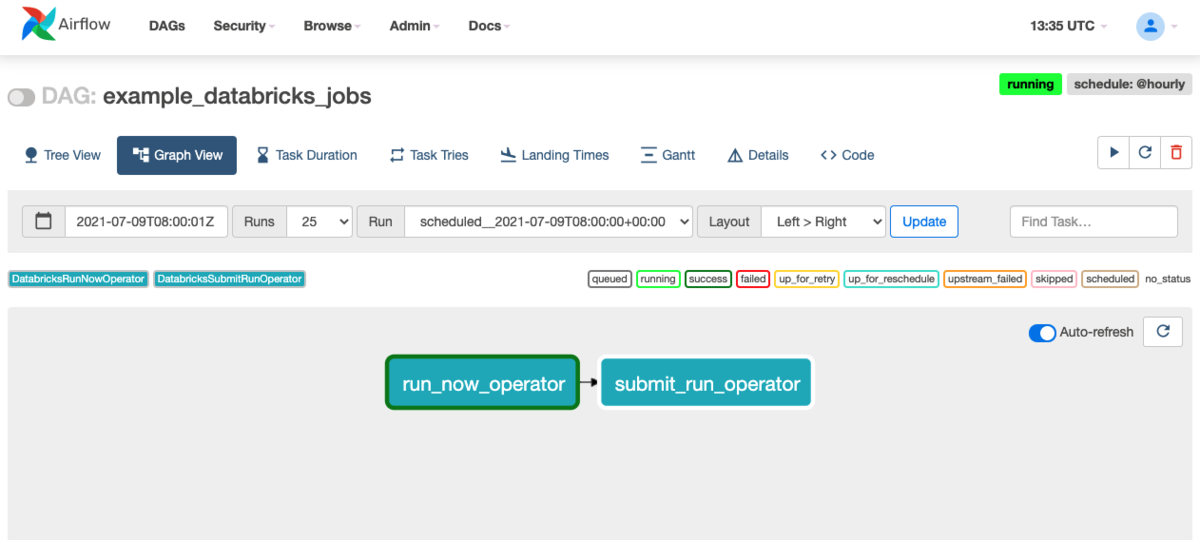
定義したDAGによるワークフローは、ダッシュボード内のGraph Viewによって可視化できます。データワークフローが可視化されることは、依存関係の素早い把握に繋がり、多数のジョブの運用を助けます。
次の画像は上記のDAGによるワークフローが可視化されたもの表しています。
ジョブ間の依存関係の考慮
Apache Airflowでは、ExternalTaskSensorモジュールという他のDAGに定義されているタスクの実行結果(成功/失敗)を検知するモジュールを使用することで ジョブ間(DAG間)の依存関係を設定できます。
このモジュールを後続として実行したいDAGの最初のタスクとして定義すると、アプリログを保存するジョブの終了後にKPIを計算するジョブを実行するなどのジョブの依存関係を設定したワークフローを表現できます。ジョブの実行結果を検知するタスクを後続のワークフロー内に定義することで、トリガーとなるジョブ内に後続ジョブの実行を定義する必要がなくなります。
ジョブのワークフロー内に別のジョブ実行を定義する必要がなくなったことは、ジョブが持つ関心事を明確にし、データワークフロー管理の観点やジョブ運用の観点などに様々な利点をもたらします。
次の図のようにジョブを個別のDAGとして定義できます。
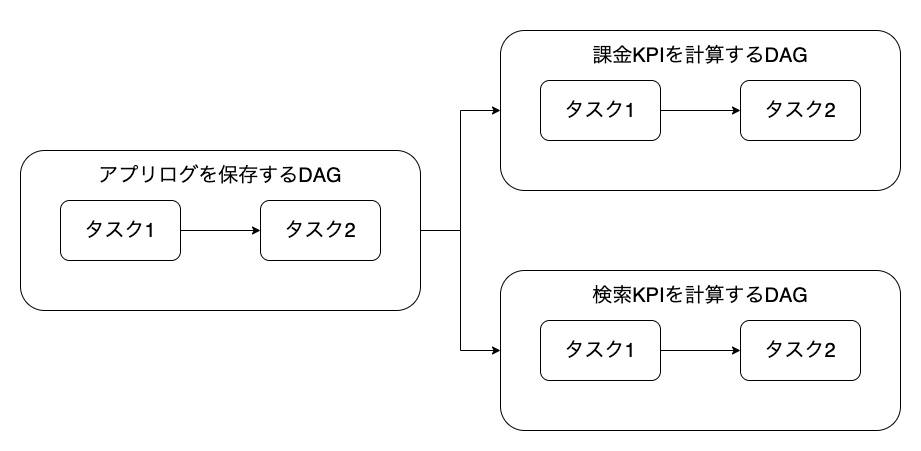
ジョブを個別に定義することで、並行実行による実行時間の短縮や、ジョブごとの適切な計算資源の割当により、不必要な計算資源を長時間使い続けることがなくなります。 必要な計算資源を必要な時間だけ使用することにより、ジョブの運用に要求されるコストが最適化されます。
例えば、アプリのログを保存するジョブには大きな計算資源を、各KPIを計算するジョブには小さな計算資源を割り当て、KPI計算を並行して実行することで、ジョブ全体での実行時間の短縮と計算資源の適切な割当により運用コストを抑えることができます。
このように関心事が分離され、適切な粒度でジョブを分割することで以下のような恩恵を受けます。
- ジョブの計算量に応じた適切な計算資源配分
- 上記によるコスト削減
- ジョブの並列実行によるワークフロー全体で見た実行時間の短縮
- ワークフロー変更に対する柔軟性
- データワークフローの見通しの好転
最後に
以上、ETLバッチジョブの管理ツールとしてApache AirflowをPoCした話でした。
Apache Airflowを導入したことで、ジョブ間の依存関係を考慮したワークフロー定義が可能になり、適切なジョブの定義によりで様々な恩恵を得ることができました。
ジョブを関心事毎に適切な粒度で定義することで、各ジョブの見通しがよくなる、コストが最適化されるなどの恩恵を享受でき、多数のETLバッチジョブを長期に渡る管理・運用を可能とすることが期待されます。