
こんにちは。
開発本部のデータ&AIチームでデータサイエンティストをしている古濵です。
引き続き、私がフルコミットしているDELISH KITCHENのレシピレコメンドについてまとめていきます。
前回の投稿の続きのような位置づけです。
私自身の苦悩も含めた思考過程と実際に取り組んだことについてまとめていきます。
背景
DELISH KITCHENではユーザの嗜好に寄り添ったアプリのパーソナライズに向けた開発をしています。
大きく3つの課題を解決するために、アプリのパーソナライズに注力しています。
受動的に提示するレシピのパーソナライズ不足
サービスの成長に伴い、ユーザ数もレシピ数も増えているのに対して、アプリのロジック部分は更新されていない状態が続いています。
そのため、ユーザが好みのレシピの発見の機会を増やすために、レシピのレコメンドの開発を進めています。
ロジックの癒着
DELISH KITCHENでは、一部の機能がサーバー側の簡易な集計ロジックをもとに提供しているため、サーバー側の実装と密結合となっている部分があり、データ&AIチームが継続的にロジックの改善に集中できない状態です。
そのため、データ&AIチームがオーナーシップを持ってロジックを開発し、サーバーエンジニアがロジック改善に伴う修正を対応せずとも運用できる状態を目指しています。
ML活用が部分的にしか行われていない
ユーザの行動データやレシピの栄養素データなど多くのデータが利活用できる状態なのに対して、MLをプロダクトに活用する動きが部分的にしかできていません。
そのため、MLをプロダクトに活用する事例づくりや、ML基盤の構築が必要となっており、データ&AIチーム総手で取り組んでいます。
直近のML事例は以下をご覧ください
レシピレコメンド開発の道のり
構成
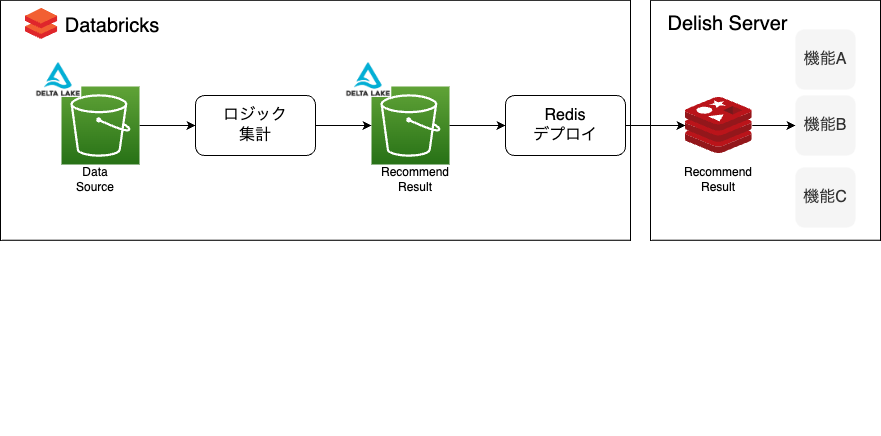
対象面は、最近見たレシピからおすすめの枠です。
レシピレコメンドの全体構成は以下のとおりです。
Data Sourceとなるdelta lakeからデータを読み込み、ロジック用の集計をdatabricksのnotebookで実装します。
実装した結果をレコメンド結果としてdelta lakeに保存し、そのデータと同じフォーマットのデータを推論結果のデータストアとして、Delish ServerのRedis(ElastiCache for Redis)内にデプロイします。
このパイプラインをデイリーのバッチで実行し、推論結果をサーバー側で取得して、DELISH KITCHENアプリで表示できるようにしています。
最初にやったこと
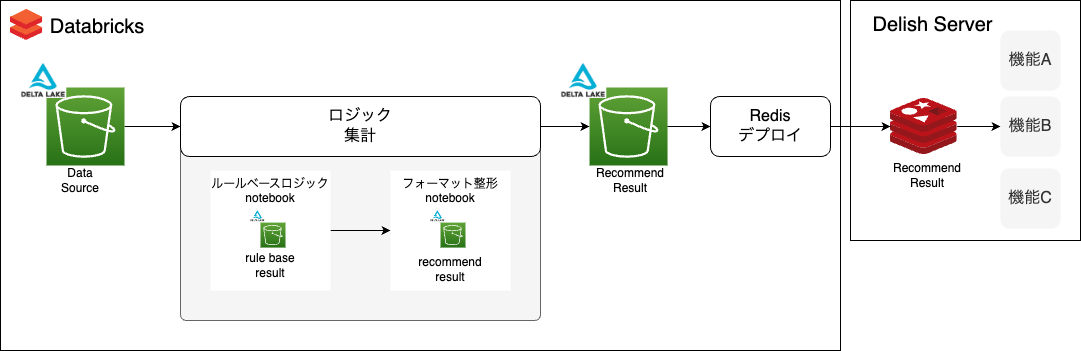
ルールベースのベースライン
まず、ルールベースのベースライン作成をしました。具体的には、ルールベースロジックnotebook内で、ユーザごとに検索経由で視聴した動画の中で長く再生したレシピ順にレコメンドする集計をしました。
集計データをrule base resultとしてdelta lakeに保存します。
Redisへデプロイするためにフォーマット整形も別のnotebookで実装し、recommend resultとして保存します。
最近見たレシピからおすすめ、というタイトルともシナジーもあり、ユーザにとってもわかりやすいレコメンドになったと思います。
数年間更新されていなかった既存ロジックと、ルールベースのベースラインを比較するためにA/Bテストしました。
結果として大きく改善しましたが、以下の2点のことがわかりました。
既存ロジックとルールベースのベースラインでは、レコメンド対象のユーザ数が異なることが判明し、ルールベースのベースラインが改善したというよりも、レコメンドを展開しているユーザ規模を増やすことができたことが改善の大きな要因だということ
レコメンド対象に含まれていないユーザは、アプリ上で最近見たレシピからおすすめ枠が表示されていないということ
上記のような手探りの状態から始まりました。
とはいえ、ルールベースのベースラインを作って検証し、新たな課題を得ることができたと思います。
ルールベースのベースラインの限界
ルールベースのベースラインを作成した時点で、ルールベースの限界も感じていました。理由は2つあります。
1つ目は、動画をあまり再生しないユーザも一定数いることが見えてきたからです。
レコメンドをする順序を再生秒数の多い順にしていましたが、動画をあまり再生しないユーザにとっては、嗜好に添わないレシピが上位に表示されることになります。
それは、DELISH KITCHENのユーザは、動画を見るためにアプリを使っているわけではなく、レシピを探すためにアプリを使っているからではないかと推測しています。
あくまで動画はレシピを選定するための手段にすぎず、目的はレシピを探すことであり、Youtubeなどの動画サービスとは異なる思考が必要だと感じました。
そのため、動画を再生せず、材料などが見れるレシピ詳細を見てからレシピを選定しているユーザもいると考えました。
2つ目は、実装コストに対して、大きな改善は望めないと思ったからです。
多くのルール作成したり、レコメンド順序を細かくチューニングするなどすれば、より良いレコメンドができるかもしれませんが、その実装をするコストに対して改善の幅は小さいだろうと感じていました。
実際に、ルールベースのベースラインにレシピ詳細の表示ログを追加してA/Bテストしたところ、大きな改善はしませんでした。
MLロジックに向けての情報収集
ルールベースに限界を感じていたため、MLロジックに向けての情報収集を始めました。
まずは、ブログ記事を読み漁り、引用されている論文など目を通しました。
MLの導入やレコメンドのアルゴリズムに関して多くの知識があったわけではなかったため、基礎や体系的に学べる書籍を購入して読み進めました。
また、Kaggleなどコンペティションで実施された解法なども参考になりました。
コンペティションの場合、コードが公開されているケースが多くあり、コードを読んで理解する助けになりました。
情報収集した気づきとして、書籍で紹介される協調フィルタリング(行列分解など)のような手法は、コンペティションの解法ではメインで使われていないということです。
あくまで主軸となっていたのは、Two-stage Recommender Systemsと呼ばれる、候補生成とリランキングの2つからなる手法でした。
候補生成の一つとして協調フィルタリングなどが使われているケースはたくさんありましたが、メインとして使われている解法は多くなかった印象でした。
Two-stage Recommender Systemsは、大規模なユーザ x アイテムの組み合わせを全て扱うのではなく、ユーザ一人当たりに対して候補を生成し、その候補を並び替え(リランキング)するという手法です。
手法の肝としては、情報検索における検索クエリの結果が候補であり、検索結果をどの順序で並び替えるかがリランキングに該当するのかなという所感を受けています。
正しくは確認できていないですが、Covington Paul, Adams Jay, and Sargin Emre. 2016. Deep neural networks for Youtube recommendations. In RecSys. 191–198.で提案された手法が有名であり、その後Two-stage Recommender Systemsという言葉が広まったかなと思います。
Two-stage Recommender Systemsを実装するために、まず、どのような候補を生成できるかのアイデアを一覧化しました。
候補の肝となるeventログをデータソースとして、SQLで集計可能な候補を中心に整理しています。
後述する候補生成モジュールでは、このアイデア一覧をもとに、候補を生成するためのクエリを一元管理しています。

候補生成のアイデアを整理する中で、ルールベースのベースラインである検索経由で視聴したレシピを候補の一つとして扱えるのではという考えが浮かびました。
Two-stage Recommender Systemsであれば、検索経由で視聴したレシピとレシピ詳細を表示したレシピの2種類をそれぞれ候補として扱い、ルールベースにおける並び替えの限界を、MLロジックでリランキングすることでユーザの嗜好にあった順にレコメンドできると考えました。
Two-stage Recommender Systemsの実装
候補生成
まずは、候補生成をするパイプラインの作成から始めました。
全体構成としては、ルールベースロジックのnotebookが候補生成notebookに置き換わります。
候補生成notebookでは、複数の候補を一括で生成するために、候補生成モジュールを用いています。
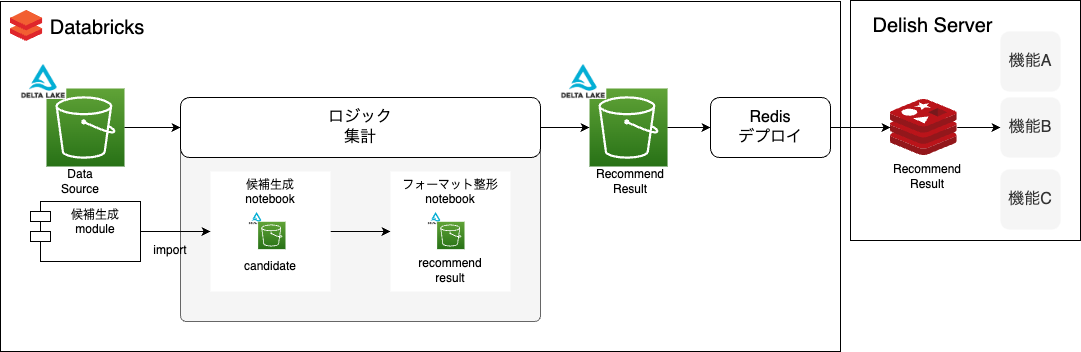
候補生成モジュールを作成した経緯として、レコメンド開発をしていく上で、今後多くの候補を作るだろうと予測していたためです。
DELISH KITCHENで全てのレシピからレコメンドする場合、ユーザ一人当たり5万レシピ強になります。
候補生成は、このレシピの数を減らす役割がありますが、特定の候補からだけでレコメンドした場合、特定の人気レシピや上位のポジションに位置するレシピばかりがレコメンド対象になる可能性があります。
本ブログ執筆時点では、検索経由で視聴したレシピとレシピ詳細を表示したレシピを候補にしていますが、さらに複数候補からの組み合わせでレコメンドしたいケースも出てくると考えました。
そこで、候補生成モジュールを作成し、候補生成に関する集計ロジックを一元管理することにしました。
使い回しやすい 2-stage recommender systemの デザインパターンを考えて実装した話 を参考に、Candidate、QueryGererator、Evaluatorのクラスを作成し、これを候補生成モジュールと呼称します。
Candidateに対して、それぞれQueryGereratorとEvaluatorが依存しています。
メインとなるCandidateは、以下のメソッドを持っています。
- generate
- QueryGereratorからクエリ(=query)をstringを受け取り、spark.sql(query)を実行
- QueryGereratorでは、候補を生成するためのクエリと、クエリがアウトプットするスキーマを保持
- クエリはspark.sql()で実行可能なクエリであり、スキーマはpyspark.sql.typesのStructTypeで定義
- evaluate
- Evaluatorクラスで定義された評価関数を使って、生成した候補とground truthを比較
- 評価関数には、precision@k, recall@k, map@k等
- validate
- generateで生成したデータや、evaluateで評価するデータに対して、簡単なバリデーションを実施
- バリデーションにはdataframeの空チェック、カラム数チェック、カラム名チェック、カラムの型チェック等
候補生成モジュールを用いて候補生成notebookを実行し、候補を生成します。
サンプルコードとしては、以下のとおりです。
from src.recommend_system.candidate_generation.candidate import Candidate
ground_truth_table = spark.sql(...)
candidate = Candidate(
delta_schemas=delta_schemas,
user_col="user_id",
item_col="recipe_id",
candidate_col="candidate_recipes",
ground_truth_col="recipe_ids"
)
candidate_names = candidate.catalog_schema.keys()
for candidate_name in candidate_names:
candidate.generate(
candidate_name,
date
)
candidate.evaluate(
candidate_name,
ground_truth_table,
eval_topk=[3, 8, 10],
mlflow_eval_cache_name=candidate_name
)
results = candidate.generated_candidates[candidate_name]
results.write \
.format("delta") \
.mode("overwrite") \
.option("mergeSchema", "true") \
.save(f'path/{candidate_name}')
candidate_namesに生成する候補名となるkeyが格納されます。
これは、QueryGeneratorクラスで定義した、候補を生成するためのクエリとクエリがアウトプットするスキーマをもとに、Candidateクラスのcatalog_schemaに格納されます。
QueryGeneratorクラスの、候補を生成するためのクエリとクエリがアウトプットするスキーマは、以下のような定義をしています。
新規で候補を追加したい場合、以下のような実装を追加するだけでOKです。
class QueryGenerator:
def __init__(self, delta_schemas: DeltaSchema):
self.catalog = {
"検索経由の視聴": {
"query": {
"func": self.fetch_検索経由の視聴,
"params": { "days": 30 }
},
"schema": StructType([
StructField("user_id", StringType()),
StructField("recipe_id", LongType()),
StructField("seconds", DoubleType()),
])
},
...
}
...
def get_query(self, candidate_name: str, date: str) -> str:
...
return query
def fetch_検索経由の視聴(self, from_date: str, to_date: str) -> str:
return f"""
SELECT
user_id,
recipe_id,
sum(seconds) AS seconds
FROM
...
WHERE
event_date BETWEEN '{from_date}' AND '{to_date}'
AND ...
GROUP BY
1,
2
"""
リランキング
生成した候補から得られたuser_id x recipe_idの組み合わせを用いて、リランキングをします。
リランキングでは、教師あり機械学習を用いてリランキングモデルを作成し、予測結果を降順でソートして上位k個をレコメンド対象とします。
今回は、LightGBMを使ってリランキングモデルを作成しました。

候補群の作成
まず、各候補をfull outer joinして、user_id x recipe_idの組み合わせとなる候補群を作成します。
今回の場合は、検索経由で視聴したレシピとレシピ詳細を表示したレシピの2種類の候補になります。こうして作成された候補群がリランキングの対象となります。
特徴量の作成
次に、リランキングモデルの学習をするための特徴量を作成します。
特徴量は、ユーザの行動データやレシピの栄養素データなどを使って作成します。
行動データは動画の表示及び視聴やレシピ詳細の表示、最後のアクセスからの経過日数、アプリ内の様々なタップログを用いています。
栄養素データは、DELISH KITCHENのレシピのメタデータにあるカロリー、たんぱく質、脂質、糖質などの栄養素を使っています。
栄養素データはDELISH KITCHENのWebサイトで公開されており、ユーザがレシピを選定する上で重要な指標になっていると考えています。
目的変数の設定
次に、正解ラベルを用意します。
これを目的変数とします。
今回の学習では、候補生成時点よりも未来の時間軸にユーザが視聴したレシピを正解ラベルとします。
そのため、正解ラベルは視聴した=1、視聴していない=0を持ちます。
正解ラベルは、最近見たレシピからおすすめの枠で視聴されたレシピのみに限定せず、アプリ上の全ての枠で視聴された動画を対象としました。
その理由は以下の3つです。
- 最近見たレシピからおすすめの枠は、ユーザにレシピを再度見てもらうための枠だと位置づけており、ユーザが興味を持ちそうなレシピを広く反映させたいため
- 最近見たレシピからおすすめ枠の視聴レシピだけでは、すべての枠で視聴されたレシピの数に比べて、正解ラベルの数が少なくなるため
- 最近見たレシピからおすすめ枠経由のレシピだけを用いると、正解ラベルが既存ロジックのバイアスの影響を受けるため
学習
次に、候補群に対して、特徴量と正解ラベルをleft joinして学習データを作成します。
学習データをもとに、再視聴の有無を予測するための二値分類問題として、LightGBMで学習します。
正解ラベルは視聴していない=0の方が圧倒的に多いため、0となる方をダウンサンプリングしています。
学習後、mlflowを使ってモデルを保存します。
予測
次に、学習データと同じ特徴量を使って、最新の候補群に対して予測します。
予測結果を降順でソートし、上位k個がリランキングモデルにおけるレコメンド対象になります。
評価
最後に、同じ候補群を用いて、ルールベースのベースラインとリランキングモデルの性能を評価します。
ルールベースのベースラインは再生秒数で降順にソートし、上位k個がルールベースのベースラインにおけるレコメンド対象になります。
リランキングモデルとルールベースのベースラインの各評価指標もmlflowで記録し、モデルの性能を比較できるようにしています。
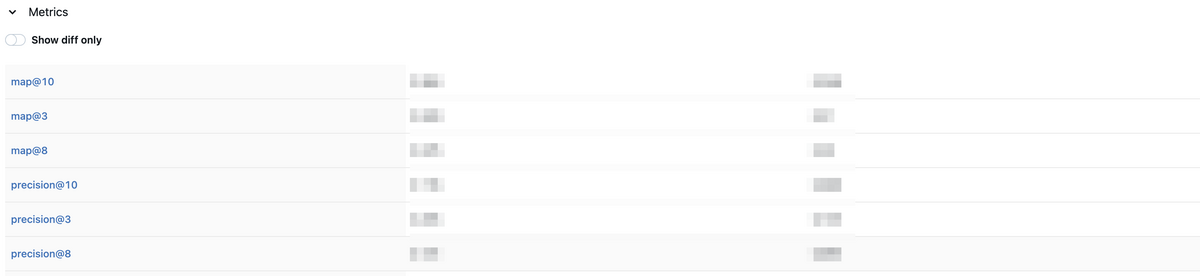
A/Bテスト
controlをルールベースのベースライン、testをTwo-stage Recommender Systemsによるレコメンド、としてA/Bテストしました。
A/Bテストの結果、ある指標において、リランキングモデルによるレコメンドがルールベースのベースラインよりも改善されたことがわかりました。

まとめ
本ブログでは、DELISH KITCHENのレシピのレコメンドにTwo-stage Recommender Systemsを導入するまでの道のりについてまとめてきました。
現時点では検証段階であり、あくまでTwo-stage Recommender Systemsの一通りの実装をしただけに過ぎません。
リランキングモデルの目的変数の設定は深く検討できておらず、特徴量も既存のものを使いまわしているため、モデルの性能は十分とは言えません。
バイアスの考慮なども含めるとチューニングして改善する余地は多くあります。
そんな未だ手探りの状態とも言えますが、ユーザの嗜好に寄り添ったアプリを目指した改善が少しずつできていると思います。
CTOの今井が過去のブログでも記載している「事業を推進する開発組織になる」を目指して、データ&AIチームとして、引き続きプロダクトに寄り添った開発を進めていきたいと考えています。
私個人としても、MLをプロダクトに導入するという非常に挑戦的な取り組みをできており、裁量を持って開発をできていることに成長を実感しています。
データ&AIチームでは一緒に働く仲間を募集しています! 動画メディアでAI/MLプロダクトの推進にご興味のある方はぜひ、以下のURLからご応募ください。
corp.every.tv

 リプレイス前の実装は上記図のようになっていました。
リプレイス前の実装は上記図のようになっていました。 リプレイス後のインフラ構成は上記図のようになる予定です。
リプレイス後のインフラ構成は上記図のようになる予定です。








