エブリーでは、DELISH KITCHEN の Web を最初Riot.jsという SPA ライブラリと クローラー向けには静的な HTML を返すため、Express を使って SSR を行っていました。
この構成上コードが二重管理されており、新規ページや機能の開発、運用コストが大きくなっていました。
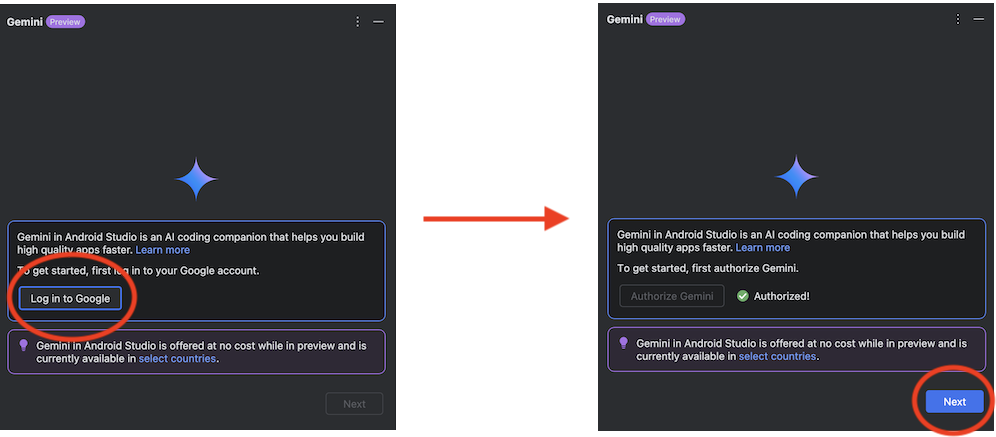
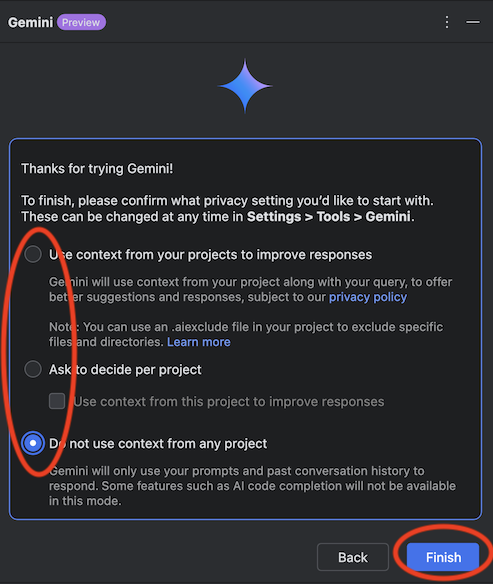
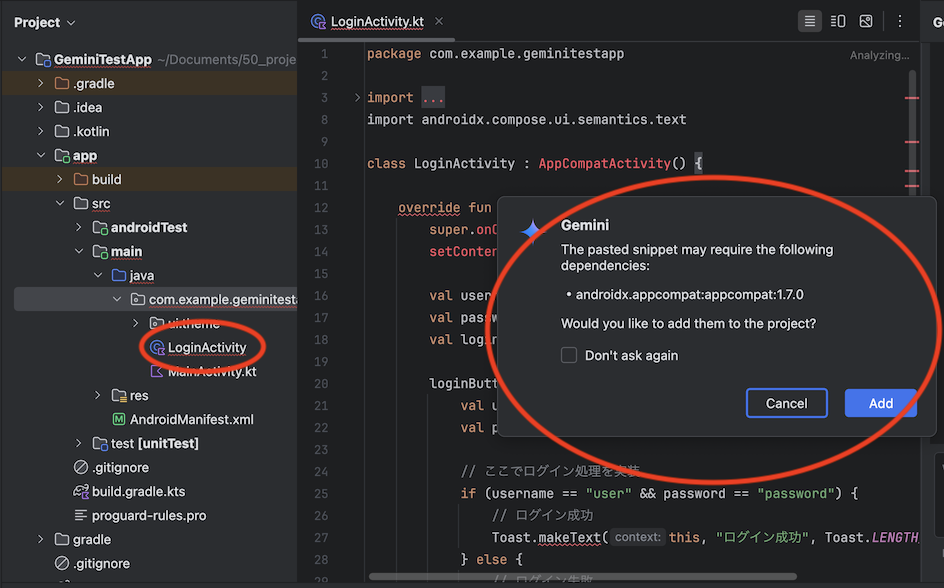
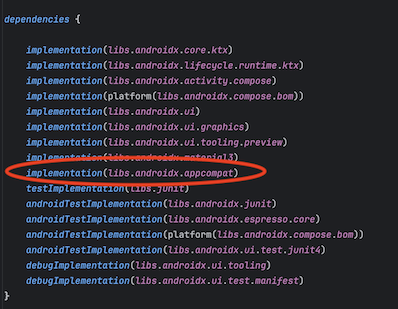
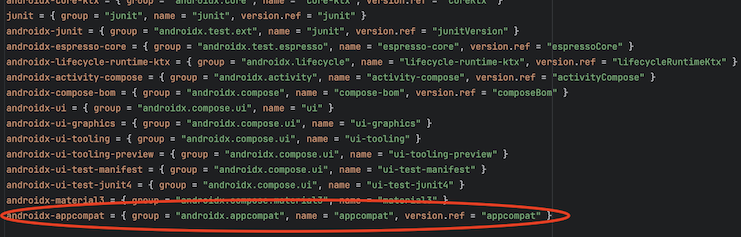
昨今 AI がますます普及し業務で AI を活用する事例も増えてきましたが、Google が提供している Gemini が Android Studio の一機能として提供されていることをご存知でしょうか?
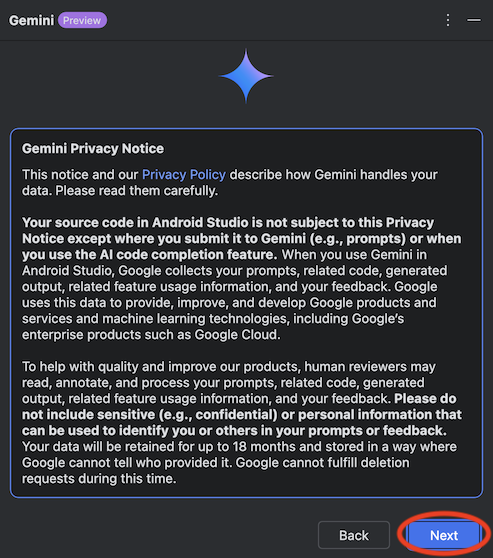
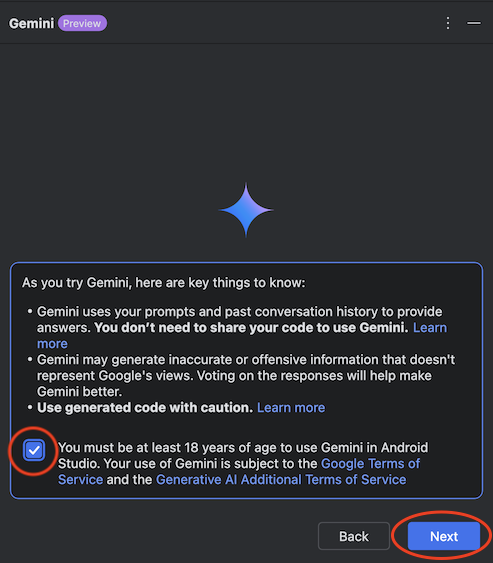
2024/9/13 時点ではまだプレビュー版ではありますが無料で公開されていますので、今回は実際に使用した際の環境構築手順、使用感などをまとめてみたいと思います。
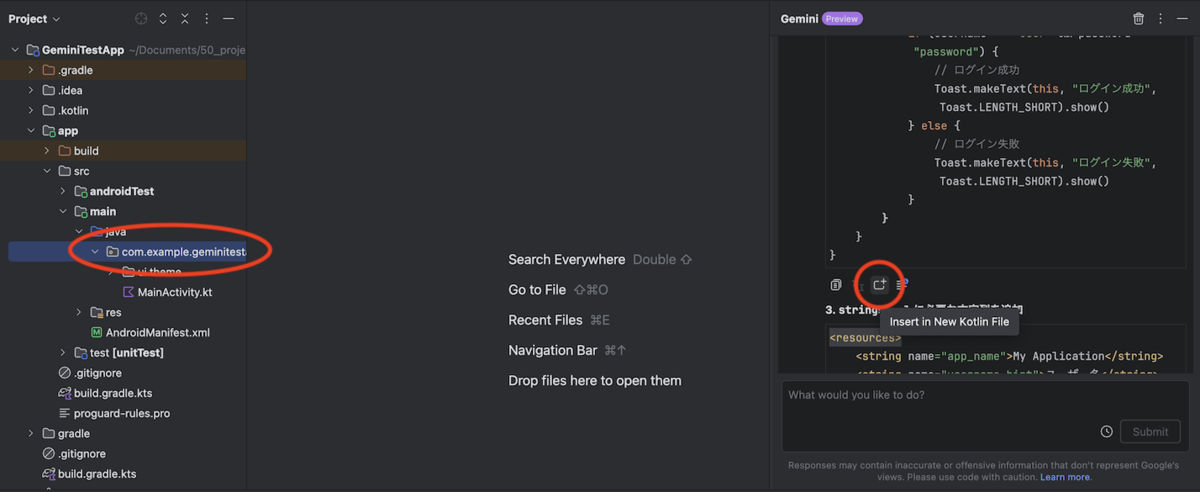
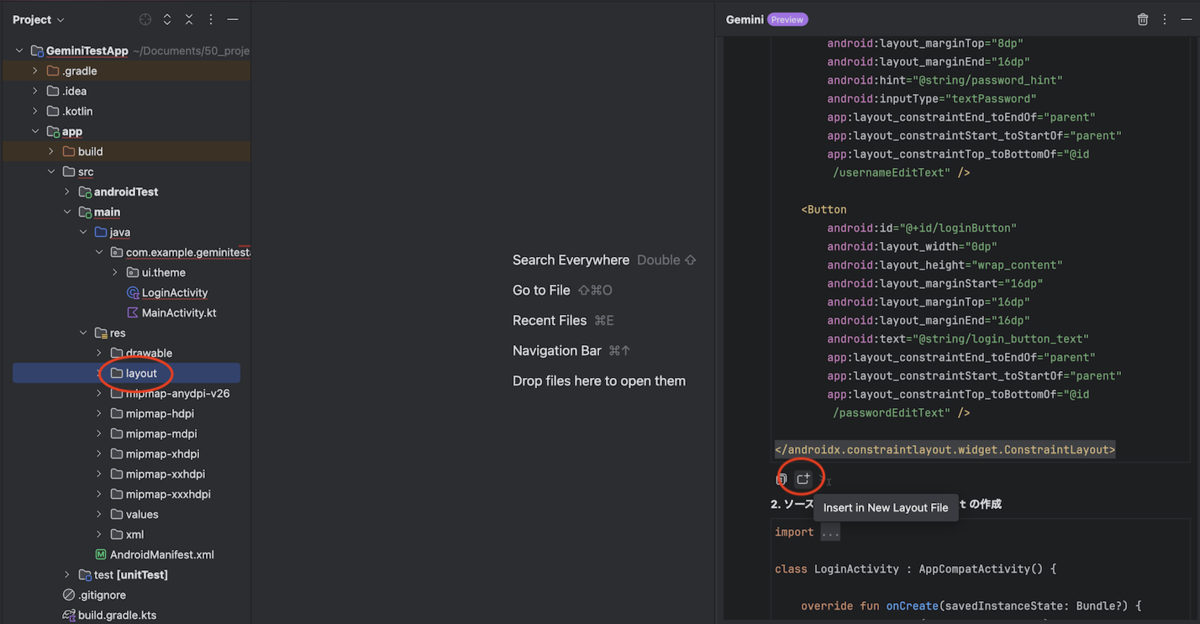
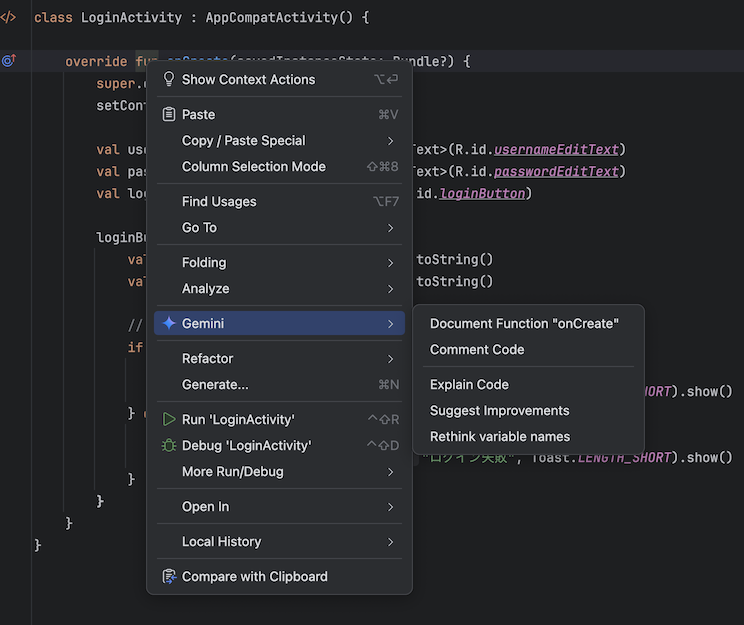
色々と試した中で一番便利に感じたのは、ファイル操作の「Insert at Cursor (カーソルの位置に自動挿入)」と「Insert in New Kotlin File (ファイル自動生成)」を組み合わせて使用する形でした。
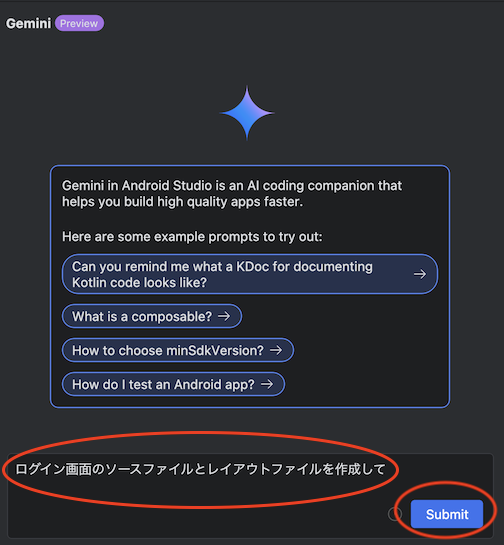
具体的な例を記載してみます。
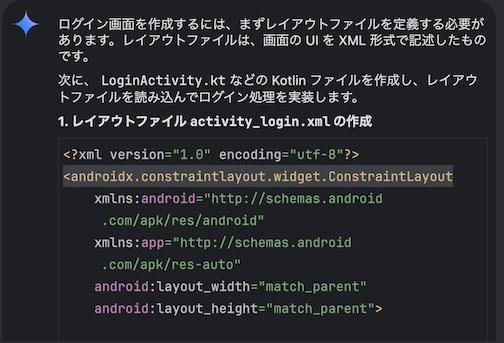
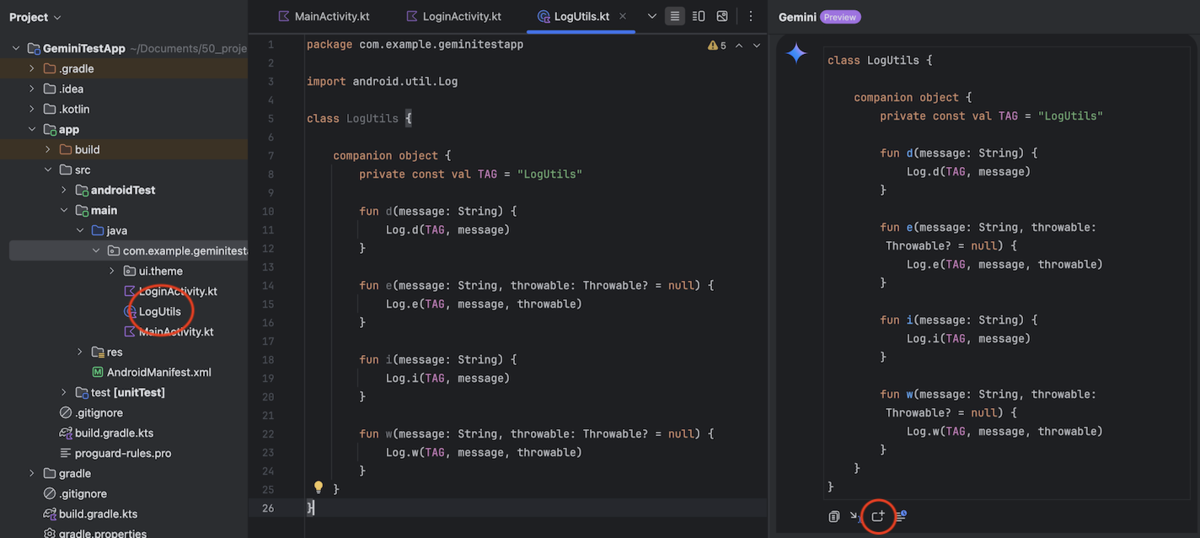
「ログを出力する Utility クラスを作成して」と質問し、出力結果で「Insert in New Kotlin File」を実行しファイルを自動生成する
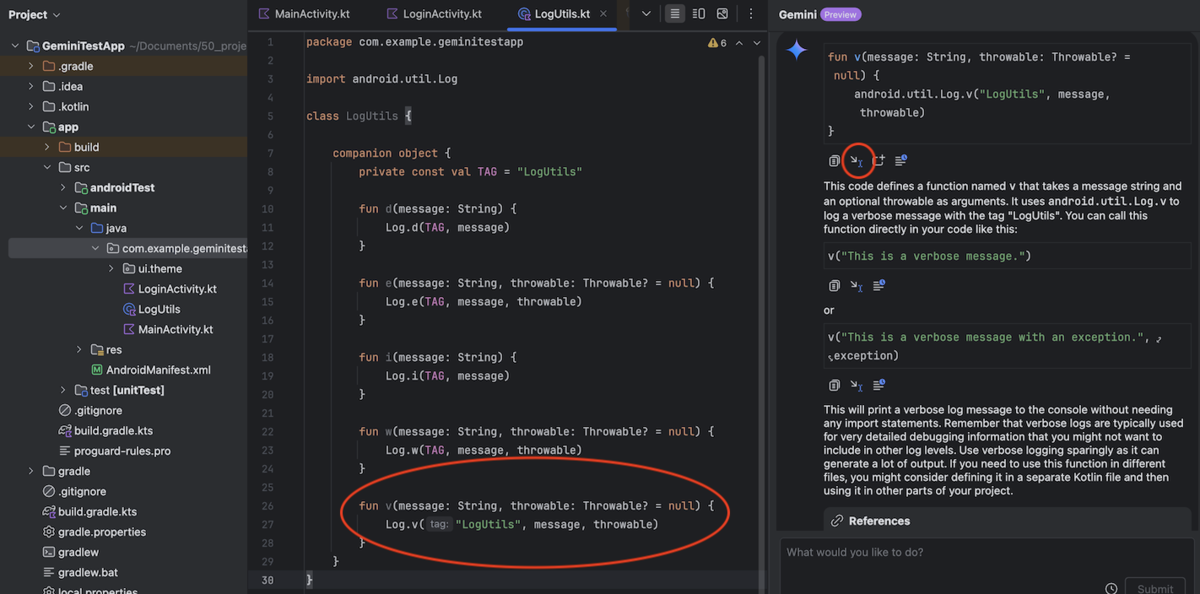
「verbose のログを出力するメソッドを作成して」と質問し、出力結果で「Insert at Cursor」を実行しクラスを拡張する
手動で実装することなくチャットによるやり取りのみでクラスの生成、クラスの拡張を行うことが出来ました。
ビジネスロジックを含むようなクラスの生成は難しいかもしれませんが、Utility クラスや data クラスなど単純なメソッドの組み合わせになるようなクラスであればこちらの方が速く実装できる可能性があります。
まとめ
今回 Android Studio の Gemini 機能を使用してみましたが、ブラウザと Android Studio を行き来する手間もなくなり、ファイルの自動生成など Android Studio の操作の手間をかなり軽減し、
また最低限の知識さえあればソースコードをほぼ書かずに実行ができる状態まで作れるため、開発のサポートとしては非常に強力だと感じました。
JSON形式ログの方は、Dynamic Partitioning(動的パーティショニング)を使えばJSONパースが行われてS3のプレフィックスにパーティションされます。この際、1ログごとに付与される改行コードがなくなってしまいます。そこで改めてDestination(送信先)データに改行コードを付与するためにProcessorsのAppendDelimiterToRecord typeを設定する必要があります。Terraformで適用するとコンソール上では「New line delimiter(改行の区切り文字)」がenabled(有効)になります。一方で、スペース区切り形式ログの方はDynamic Partitioningを使う必要がないのでTransform and convert records(レコードを変換および転換)機能を行うだけで改行コードが付与されているので改めてAppendDelimiterToRecordを設定する必要はありません。
"errorCode":"DynamicPartitioning.MetadataExtractionFailed","errorMessage":"partitionKeys values must not be null or empty"
問題2
Firehose自体のエラーログに以下のエラーメッセージが出てS3保存に失敗していた
errorCode":"DynamicPartitioning.MetadataExtractionFailed","errorMessage":"Non UTF-8 record provided. Only UTF-8 encoded data supported"
問題3
terraform applyを実行すると以下のエラーメッセージが出て適用に失敗した
operation error Firehose: UpdateDestination, https response error StatusCode: 400, RequestID: d7b3d246-ecb3-a51f-88ba-1557ca6eae2a, InvalidArgumentException: Enabling source decompression is not supported for existing stream with no Lambda function attached.
具体的には、コンソールで言うところの特定Data Firehoseのconfigurationページを開いて「Transform and convert records」→「Decompress source records from Amazon CloudWatch Logs」と「Extract message fields only from log events」をONにします。
ちなみに、 Firehose新機能の内部構造は結局Lambda関数を使っているようです(メッセージ抽出機能自体は追加料金はありませんがおそらくCloudWatch Logsからのソースレコード解凍機能部における追加料金はLambda関数料金分なのではないかと推測)。Amazon Data Firehose Firehose streams Configuration
Amazon Data Firehose解凍機能のみを使ってCloudWatch LogsのログメッセージをS3に転送すること自体は他の記事でもありました。しかし、本記事のようにJSON形式ログの変換を追ってTerraformを使ってまとめている記事はなかったように思います。
Amazon Data Firehose解凍機能を使うべき理由は、公式DOCによるLambdaで提供しているblueprints関数テンプレートが非推奨(deprecated)となっていることにあります。ただし、2024年9月執筆時点では、未だLambda関数を作成するコンソールで該当のblueprintsを選択および作成できます。
Amazon Data Firehose解凍機能をTerraformで適用する場合、注意点があることがわかりました。
現状の課題
Amazon Data Firehose解凍機能が有償である点ですが、blueprintsのLambdaを設置した時の料金と比較しても大差がないくらい安い点で現状は採用しております。もし完全に無償でこの辺りを構築する場合は、そもそもECS FargateでFluentdなどの外部ログエージェントを使って直接S3に転送するアーキテクチャを採用することになると思います。