
はじめに
こんにちは。デリッシュキッチンでデータサイエンティストをしている古濵です。 デリッシュAIを始め、約1年ほどAIエージェントの開発に取り組んできました。
今回は、個人的に感じたAIエージェント開発のアーキテクチャについて触れようと思います。 あくまで個人的意見という点にご留意ください。
背景
AIエージェントのようなシステムでも、明確な設計思想に基づいたアーキテクチャ選択が重要です。 しかし、AIエージェント開発における確立されたアーキテクチャパターンは、まだ十分に整理されていない状況です。
一般的にアーキテクチャを考える時、クリーンアーキテクチャ(レイヤードアーキテクチャ)などに代表されるような、依存関係を明確にしたり、責務を分離することなどがメイントピックだと思います。 AIエージェント開発でも、これらの観点は重要です。 ただ、AIエージェント固有の観点もあると感じており、それを考慮したアーキテクチャ設計が必要だと思っています。
アーキテクチャ文脈でのAIエージェント固有の観点
先に述べておくと、AIエージェント固有の観点は以下の2点だと考えました。
- 評価しやすいこと
- 処理を組み替えやすいこと
なぜそのように考えたかについて、以下にまとめていきます。
スコープ
ひとえにAIエージェントと言っても、Workflow型とAgent型に大別されます。 これらは区別されると言っても、一定のグラデーションを持つ性質もあります。
今回は、Workflow型を中心に考えていきます。 これは世の中のAIエージェントの中心は、まだWorkflow型だろうと考えているためです。 個人的にはLLMに全てを任せるよりも、実装側で手続的な処理を駆使した方がコントロールがしやすく、デバッグもしやすいと考えています。
RAGのアーキテクチャ
Workflow型のAIエージェントの代表格といえばRAGです。 デリッシュAIもRAGを中心としたシステム構成になっています。
Langchainは、RAGの構成を以下のようにまとめています。
- Query Translation
- Routing
- Query Construction
- Indexing
- Retrieval
- Generation
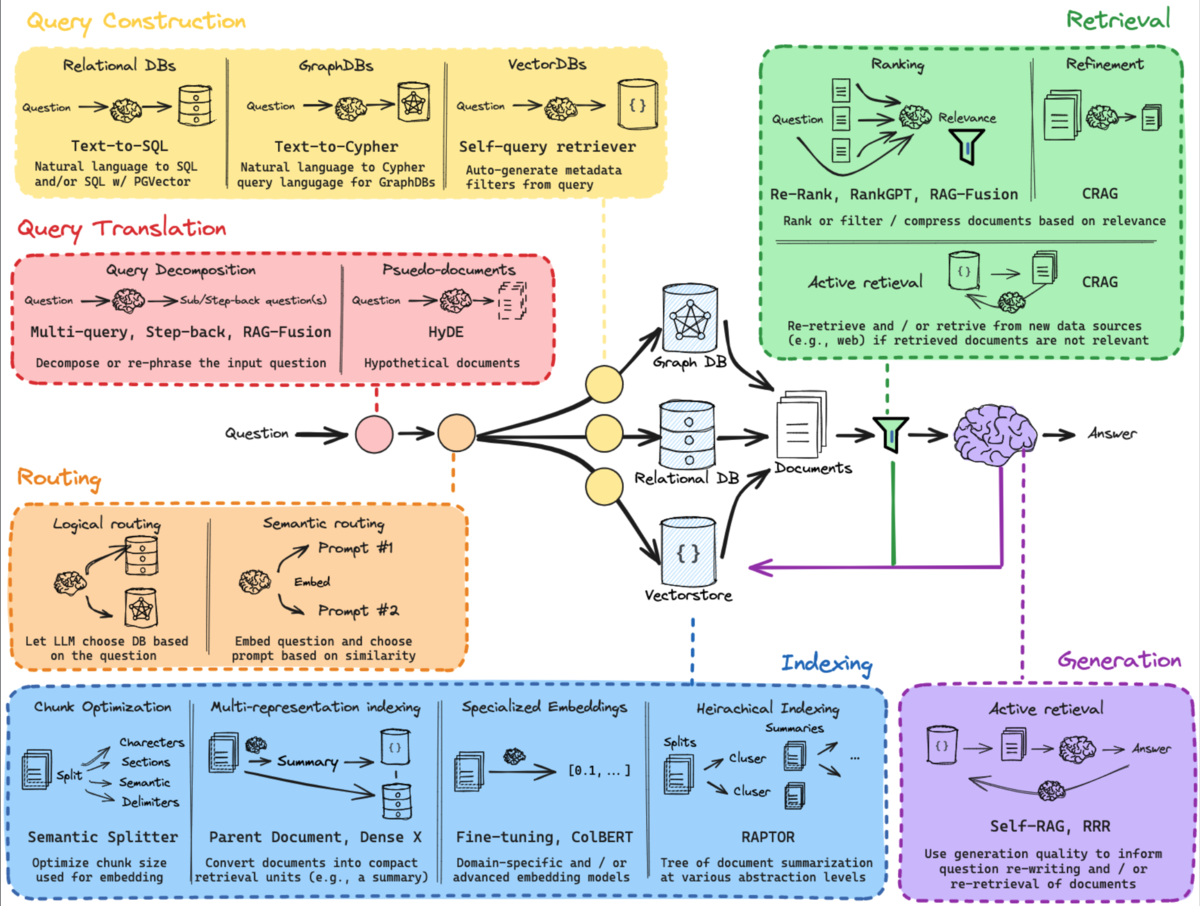
これは大きく分ければ、以下のように分けられます。
事前処理
- Indexing
前処理
- Query Translation
- Routing
- Query Construction
検索
- Retrieval
生成
- Generation
上記のように整理すれば、いわゆるFTI(Feature/Training/Inference)Pipelinesアーキテクチャのようにも見えてきます。
FeatureやTrainingが、事前処理や前処理にあたり、Inferenceが検索+生成にあたるという考え方です。 このような観点で整理すれば、従来のMLパイプラインと同様のアーキテクチャとして落とし込むこともできなくはありません。
とはいえ、LLMの入出力を数珠繋ぎ的に処理するWorkflow型AIエージェントの方が、従来のMLパイプラインより複雑な処理が多いと感じています。
複雑さの要因
なぜ複雑になるかは、一言で言えば「精度の向上、処理の高速化、汎用性の向上など動機がWorkflowをどう組むかに反映される」からです。 そして、変えた結果向上したかどうかを評価する必要もあります。
例えば、RAGの精度向上をさせるために、前処理で単体のLLMが処理する範囲を狭めて、複数のLLMで処理するように分けることがあります。 また、高速化するために、依存しないLLMのリクエストを並列(並行)処理して、APIの待機時間を効率的に扱えるようにすることもあります。
このように、LLMの処理で担当する範囲を狭めて並行処理することは、目的特化の処理であれば合理的です。 しかし、代償として汎用性は失われる側面もあります。 そこで、RoutingのようなWorkflowの処理自体を分岐する仕組みを作り、リクエストされたクエリに応じて呼び出すWorkflowを切り替えるというアプローチもあります。

以下の論文では、応答エージェント(質問応答エージェント、推薦応答エージェント、雑談応答エージェント)とどのエージェントで応答をするかを決める計画エージェントからなるAIエージェントを提案しています。 複数のエージェントを使い分けることで、ユーザーとコミュニケーションをとりながら、適切なアイテムを推薦するという目的を達成しています。
このように、工夫していけばいくほど処理が複雑になるのは避けられません。
その他にも、精度の向上や高速化を目的として、プロンプトを変更したい、新しいモデルを試してみたい、一部ルールベースに置き換えて結果が変わるか確認したい、Workflowの処理順序を変更してみたいなど、様々な変更点が出てきます。
実装のアプローチ
再掲ですが、以下を目指します。
- 評価しやすいこと
- 処理を組み替えやすいこと
1. 評価しやすい実装
評価しやすい実装の前に、評価項目について整理します。 RAGの場合は大きく以下のように分けられます。
- 検索の評価
- 検索+生成の評価
- 単体のLLMの評価
ここで、検索の評価は、従来の検索システムのような評価指標を適用することができます。 また、検索+生成の評価は、LLM as a Judgeを使った評価を実装しています。 具体的には、以下のテックブログをご覧ください。
単体のLLMの評価は、どのようなタスクかによって評価の仕方が変わると考えています。 それは、回答を事前に定義できる場合とできない場合です。
できない場合は、例えば要約するタスクであれば、最終的にできる要約の内容をあらかじめ定義することは難しいです。 そのため、LLM as a Judgeを使って、回答のニュアンスとして合っているかを評価するアプローチになり、検索+生成と似たような評価をすることになると思います。
できる場合は、例えば特定のキーワードを抽出するタスクであれば、抽出したい対象を正解として定義することで正答率を出すことができます。 デリッシュAIでは、このような前処理がいくつもあります。
例として、調理時間を抽出する前処理では「10分以内で作れる副菜教えて」というユーザのクエリに対して、調理時間のカラム名、不等号、値を出力します。 これらの回答は一意に定まり、事前に正解を定義することができるため、容易に評価可能です。
以下は、調理時間を抽出する前処理のコード例です。
import os from enum import Enum from pydantic import BaseModel, Field from langchain_core.messages import MessageLikeRepresentation from langchain_core.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, ) from langchain_openai import ChatOpenAI os.environ["OPENAI_API_KEY"] = "your_api_key" class CookingTimeColumn(str, Enum): cooking_time = "cooking_time_min" class CookingTimeOperator(str, Enum): greater_than = ">" less_than = "<" greater_than_or_equal_to = ">=" less_than_or_equal_to = "<=" class CookingTimeFilter(BaseModel): column: CookingTimeColumn operator: CookingTimeOperator value: float class CookingTimeFilters(BaseModel): filters: list[CookingTimeFilter] def create_cooking_time_filter(messages: list[MessageLikeRepresentation]) -> CookingTimeFilters: system_prompt = f""" あなたは料理の知識が豊富なレシピ検索AIです。 ユーザーがレシピ検索のために入力したクエリを解読し、ユーザが**調理時間**でフィルタリングして検索したい場合は、フィルタリング条件を返してください。 ## 出力形式 * json形式で出力してください * columnにカラム名、operatorに不等号、valueにフィルタリング対象を入れてください """ prompt = ChatPromptTemplate.from_messages( [ SystemMessagePromptTemplate.from_template(system_prompt), MessagesPlaceholder(variable_name="messages") ] ) llm = ChatOpenAI(model="gpt-4o-mini") chain = ( prompt | llm.with_structured_output( schema=CookingTimeFilters, method="json_schema", ) ) return chain.invoke({ "messages": messages, })
print(create_cooking_time_filter([("user", "10分以内で作れる副菜教えて")])) # CookingTimeFilters( # filters=[ # CookingTimeFilter( # column=<CookingTimeColumn.cooking_time: 'cooking_time_min'>, # operator=<CookingTimeOperator.less_than_or_equal_to: '<='>, # value=10.0 # ) # ] # )
事前に期待する結果を定義して一致しているかどうかを評価するということは、pytestなどのツールを使って同じ枠組みとして評価することも可能になります。
もちろん、temperatureを0にしても同じ結果が得られるとは限らないため、必ずテストとして通るとは限りません。 また、テストのたびに少なからずAPIコストがかかります。 この問題をある程度許容しつつ、pytestで評価できることを目指します。 例えば、CIではLLM関連のpytestを実行しないように設定することで、APIコストを抑えることができます。
以下は、pytestで評価できるようにするためのコード例です。
pytestの設定ファイルにllmマーカーを定義します。
# pyproject.toml [tool.pytest.ini_options] markers = [ "llm: LLM評価系単体テスト", ]
llmマーカーを使って、LLMの評価に関する単体テストを書きます。
# test.py @pytest.mark.llm def test_create_cooking_time_filter(): actual = create_cooking_time_filter([("user", "10分以内で作れる副菜教えて")]) expected = CookingTimeFilters( filters=[ CookingTimeFilter( column="cooking_time_min", operator="<=", value=10.0 ) ] ) assert actual == expected
pytestのコマンドラインオプションを追加します。
これにより、デフォルトではLLM評価系単体テストはskipされ、pytest --run-llmでLLMの評価含めたテストを実行できます。
# conftest.py import pytest from _pytest.config import Config from _pytest.config.argparsing import Parser from _pytest.nodes import Item def pytest_addoption(parser: Parser): """ pytest に新しいコマンドラインオプション --run-llm を追加。 action="store_true" により、オプションが指定されれば True、指定されなければ False。 これで pytest --run-llm を実行できるようになる。 """ parser.addoption( "--run-llm", action="store_true", default=False, help="Run LLM evaluation tests", ) def pytest_collection_modifyitems(config: Config, items: list[Item]): """ 収集されたすべてのテスト関数 (items) を走査する。 各テスト関数が @pytest.mark.llm でマークされているかを判定。 --run-llm が 付いていない場合は、そのテストに skip マーカーを動的に追加。 結果として: - デフォルト (pytest) → LLM評価系単体テストは skip - 明示的に実行 (pytest --run-llm) → LLM評価系単体テストも実行 """ run_llm = config.getoption("--run-llm") skip_llm = pytest.mark.skip(reason="use --run-llm to run LLM tests") for item in items: if "llm" in item.keywords and not run_llm: item.add_marker(skip_llm)
このようにして、評価データセットを用意できれば、pytestの枠組みでLLMの出力を評価できると思います。 評価データセットを作るのは大変な側面もありますが、何らかの変更に対して挙動が変わっていないかを、ガードレール的に確認できるという点では大きなメリットがあると思います。
2. 処理を組み替えやすい実装
処理を組み替えやすい実装をするためには、シンプルに何らかのフレームワークに頼る方が良いと考えています。 例えば、LangGraphでは、LLMの処理をNodeと、LLMの処理同士をどう繋ぐかをEdgeで整理され、大域的に扱う変数をStateとして定義することで、Workflowを組むことができます。
from langgraph.graph import StateGraph, START, END from langgraph.graph.state import CompiledStateGraph from typing import Annotated, TypedDict from langchain_core.messages import MessageLikeRepresentation from langgraph.graph.message import add_messages class State(TypedDict): messages: Annotated[list[MessageLikeRepresentation], add_messages] node1_result: str node2_result: str node3_result: str final_result: str def node1(state: State) -> dict: return {"node1_result": "node1_result"} def node2(state: State) -> dict: return {"node2_result": "node2_result"} def node3(state: State) -> dict: return {"node3_result": "node3_result"} def build_graph_in_series() -> CompiledStateGraph: graph = StateGraph(State) graph.add_node("node1", node1) graph.add_node("node2", node2) graph.add_node("node3", node3) # 直列に繋ぐ場合 graph.add_edge(START, "node1") graph.add_edge("node1", "node2") graph.add_edge("node2", "node3") graph.add_edge("node3", END) return graph.compile() def build_graph_in_parallel() -> CompiledStateGraph: graph = StateGraph(State) graph.add_node("node1", node1) graph.add_node("node2", node2) graph.add_node("node3", node3) # 並行に繋ぐ場合 graph.add_edge(START, "node1") graph.add_edge(START, "node2") graph.add_edge(START, "node3") graph.add_edge("node1", END) graph.add_edge("node2", END) graph.add_edge("node3", END) return graph.compile()
処理を組み替えやすい実装をしたいというモチベーションがある時点で、複雑化を許容した上でWorkflowを組む必要が出ているということだと思います。 Workflowを組むための実装を自前で書くよりも、LangGraphを使う方が容易に実装できると考えています。
mermaidによる可視化も可能で、どんなWorkflowになったかを一目で見ることができます。
from IPython.display import Image, display def visualize_graph(graph: CompiledStateGraph): display(Image(graph.get_graph().draw_mermaid_png())) visualize_graph(build_graph_in_series()) visualize_graph(build_graph_in_parallel())

LangGraphの枠組みでcreate_cooking_time_filterを実装すると以下のようになります。
import os from typing import Annotated, TypedDict from langchain_core.messages import MessageLikeRepresentation from langchain_core.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, ) from langgraph.graph.message import add_messages from langchain_openai import ChatOpenAI os.environ["OPENAI_API_KEY"] = "your_api_key" class State(TypedDict): messages: Annotated[list[MessageLikeRepresentation], add_messages] cooking_time_filters: list[CookingTimeFilter] def create_cooking_time_filter(state: State) -> dict[str, CookingTimeFilters]: system_prompt = f""" あなたは料理の知識が豊富なレシピ検索AIです。 ユーザーがレシピ検索のために入力したクエリを解読し、ユーザが**調理時間**でフィルタリングして検索したい場合は、フィルタリング条件を返してください。 ## 出力形式 * json形式で出力してください * columnにカラム名、operatorに不等号、valueにフィルタリング対象を入れてください """ prompt = ChatPromptTemplate.from_messages( [ SystemMessagePromptTemplate.from_template(system_prompt), MessagesPlaceholder(variable_name="messages") ] ) llm = ChatOpenAI(model="gpt-4o-mini") chain = ( prompt | llm.with_structured_output( schema=CookingTimeFilters, method="json_schema", ) ) results = chain.invoke(state["messages"]) return {"cooking_time_filters": results}
このような実装で良さそうですが、これだと引数のStateは大域的に扱うため、テストコードの入力として使いたくありません。 動かすこと自体は可能かもしれませんが、Stateは機能開発すれば必ず変数が増えるため、ロジックの処理とLangGraphのワークフローは分離した方が良いと考えます。
上記を踏まえて以下のように定義しました。 ロジックの処理はcreate_cooking_time_filter、LangGraphのワークフローはcreate_cooking_time_filter_graphとして定義します。 そして、create_cooking_time_filterのみをpytestの枠組みでテストコードを書くことで評価します。
def create_cooking_time_filter(messages: list[MessageLikeRepresentation]) -> CookingTimeFilters: system_prompt = f""" あなたは料理の知識が豊富なレシピ検索AIです。 ユーザーがレシピ検索のために入力したクエリを解読し、ユーザが**調理時間**でフィルタリングして検索したい場合は、フィルタリング条件を返してください。 ## 出力形式 * json形式で出力してください * columnにカラム名、operatorに不等号、valueにフィルタリング対象を入れてください """ prompt = ChatPromptTemplate.from_messages( [ SystemMessagePromptTemplate.from_template(system_prompt), MessagesPlaceholder(variable_name="messages") ] ) llm = ChatOpenAI(model="gpt-4o-mini") chain = ( prompt | llm.with_structured_output( schema=CookingTimeFilters, method="json_schema", ) ) return chain.invoke({ "messages": messages, }) def create_cooking_time_filter_graph(state: State) -> dict[str, CookingTimeFilters]: messages = state["messages"] cooking_time_filters = create_cooking_time_filter(messages) return {"cooking_time_filters": cooking_time_filters}
おわりに
AIエージェント開発において「精度の向上、処理の高速化、汎用性の向上など動機がWorkflowをどう組むかに反映される」という課題感と、変えた結果向上したかどうかを評価する必要性を提示しました。
この課題を解決するために、以下の2点に焦点を当てた実装のアプローチについてまとめました。
- 評価しやすいこと
- 処理を組み替えやすいこと
評価しやすい実装については、事前に正解を定義できるタスクにおいて、pytestの枠組みを活用することで、LLMの出力を従来のソフトウェアテストと同様に扱えることを示しました。 これにより、何らかの変更による単体のLLMとして評価できるようになり、意図しない挙動変化を検知することができます。
処理を組み替えやすい実装については、LangGraphを活用したWorkflow管理により、複雑なAIエージェントの処理フローを柔軟に変更できることを示しました。 ロジック部分とワークフロー部分を分離することで、テスタビリティを保ちながら処理の組み替えを実現できます。
AIエージェント開発は、まだ発展途上の分野であり、最適解が見えていない部分も多いです。 しかし、従来のソフトウェア開発で培われた設計原則を適用しつつ、AIエージェント固有の課題に対応することで、保守性と拡張性を兼ね備えたシステムを構築できると考えています。
今後も、AIエージェント開発のベストプラクティスを模索しながら、より良いアーキテクチャの在り方を追求していきたいと思います。