
この記事は every Tech Blog Advent Calendar 2025 の 6 日目の記事です。
こんにちは、株式会社エブリーで Android アプリ開発を担当している岡田です。
弊社では開発スピード向上のための選択として、UseCase を削るアーキテクチャ改修を行いました。
こちらについて、少しお話しさせていただければと思います。
概要: 従来のアーキテクチャの紹介
弊社では Google Developers が提唱している、レイヤードアーキテクチャを採用しています。
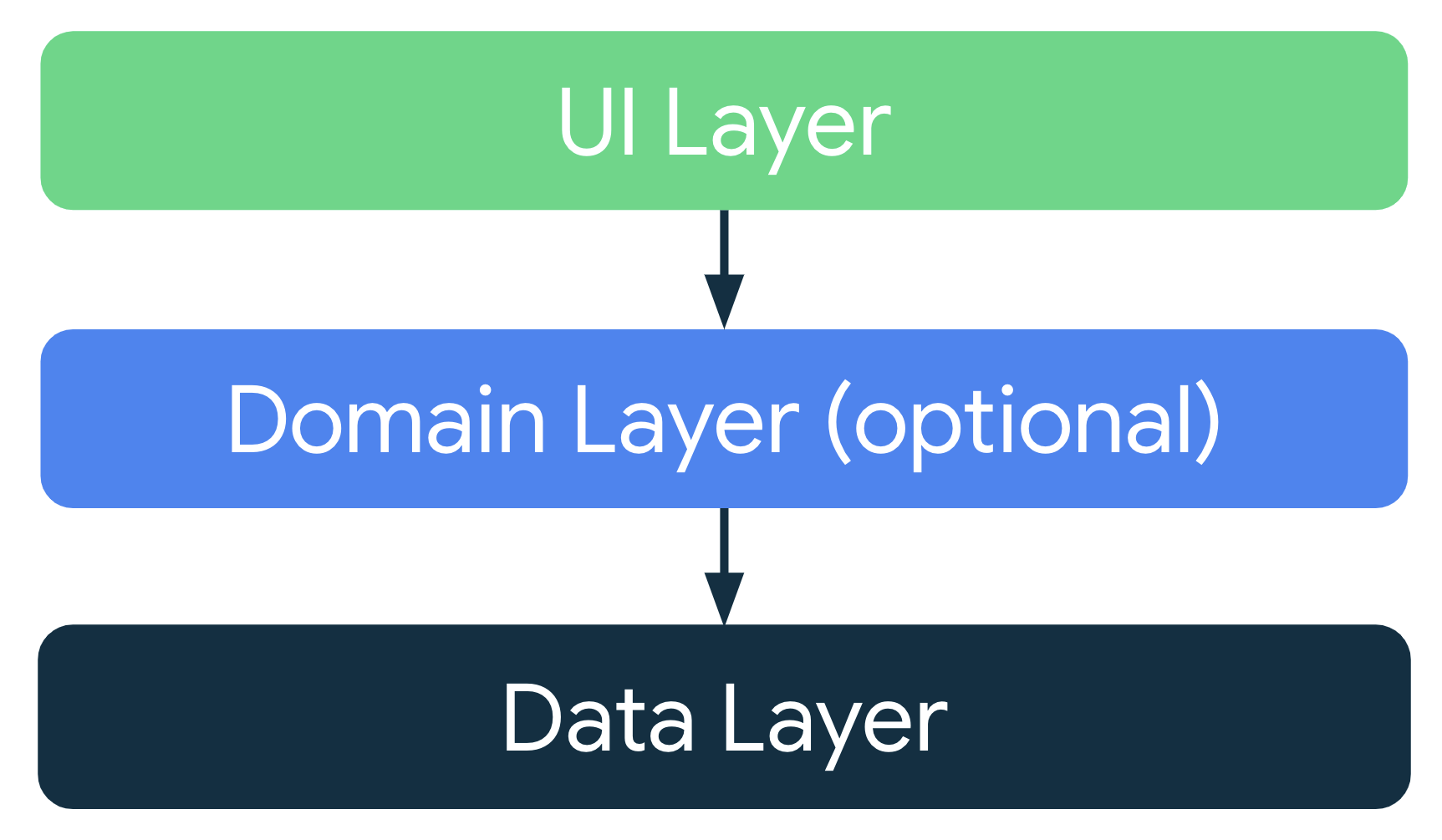
optional として紹介されている ドメイン層 も採用しています。ドメイン層 には主に UseCase を記述しています。
従来のアーキテクチャでは ViewModel が Repository を参照する場合、UseCase を介するような設計になっていました。
UI レイヤー が データ層 を直接参照してはいけないという、教科書的で厳格な「Clean Architecture」の解釈に沿った設計です。
一見するとこれは確からしい素敵なアーキテクチャに思えますが、実は Android アプリを開発する上では大きな課題を抱えています。
課題:冗長な UseCase の量産
従来のアーキテクチャでは、たとえ単純なデータ取得であっても、必ずUseCaseを作成していました。
例えば、ユーザープロフィールを表示するだけの機能でも、以下のようなコードが必要でした。
/** * 従来の UseCase */ class GetUserProfileUseCase @Inject constructor( private val userRepository: UserRepository ) { // Repositoryを呼ぶだけ(パススルー) suspend operator fun invoke(userId: String): User { return userRepository.getUser(userId) } } /** * 呼び出される側の Repository (インターフェース) */ interface UserRepository { // 戻り値も引数も UseCase と全く同じ suspend fun getUser(userId: String): User }
ご覧の通り、GetUserProfileUseCase の実装は、UserRepository のメソッドを右から左へ受け流すだけのパススルーな処理です。
アプリの機能を拡張するたびに、このような冗長な UseCase を作成しなければならないのは、単なる手間の問題にとどまりません。
クラスが増えれば、それに付随する Unit Test の記述も必要となり、プロジェクト全体のコード量は肥大化します。
特にマルチモジュール構成を採用している場合、こうしたファイル数の増加はビルド時間の悪化に直結します。
さらに、Pull Request の差分が本質的ではないコードで埋め尽くされることは、レビュワーの認知的負荷を高め、開発効率を低下させるという悪循環に陥っていました。
弊社のアプリはサーバーがビジネスロジックを持つケースが多く、上記の問題が顕在化していました。
この件については、Google Developers のドキュメント: ドメイン層 > データ層のアクセス制限でも触れられています。
ドメイン層を実装する際のもう 1 つの考慮事項は、UI レイヤーからデータ層への直接アクセスを許可するか、すべてをドメイン層経由で強制するかです。
この制限を設ける利点は、たとえばデータ層への各アクセス要求で分析ログを実行している場合など、UI がドメイン層 ロジックをバイパスするのを防ぐことができることです。
ただし、潜在的に重大な欠点は、データ層への単純な関数呼び出しであってもユース ケースを追加する必要があり、メリットがほとんどないにもかかわらず複雑さが増す可能性があることです。
必要な場合にのみユースケースを追加するのが良いアプローチです。UIレイヤーがほぼユースケースを通じてのみデータにアクセスしていることがわかった場合は、この方法でのみデータにアクセスするのが合理的かもしれません。
最終的に、データ層へのアクセスを制限するかどうかの決定は、個々のコードベースと、厳格なルールを好むか、より柔軟なアプローチを好むかによって決まります。
Google Developers としても、アプリによって使い分けた方が良いという見解のようです。
解決策:ドメイン層(UseCase)の使用をアプリがビジネスロジックを持つ場合にのみ限定する
最終的に、ドメイン層(UseCase)の使用をアプリがビジネスロジックを持つ場合にのみ限定することに決めました。
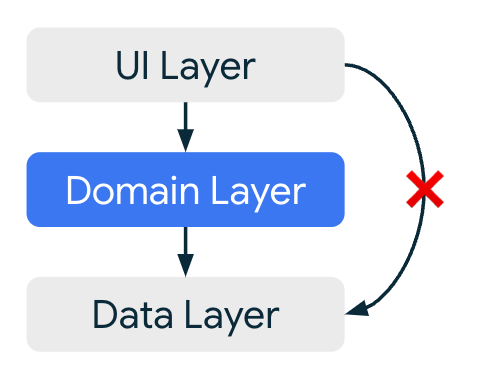
ビジネスロジックを持たない場合は、 ViewModel から Repository を直接参照することで、冗長な記述を排除できます。
このアーキテクチャは、Now In Androidと同様のものです。
docs/ArchitectureLearningJourney.mdを見ると、以下のような図があります。

UI レイヤー が データ層 を直接参照することを許容しています。
実際のコード MainActivityViewModel.kt を見ても、直接 Repository を Inject しています。
@HiltViewModel
class MainActivityViewModel @Inject constructor(
userDataRepository: UserDataRepository, // <= ここ
) : ViewModel() {
val uiState: StateFlow<MainActivityUiState> = userDataRepository.userData.map {
Success(it)
}.stateIn(
scope = viewModelScope,
initialValue = Loading,
started = SharingStarted.WhileSubscribed(5_000),
)
}
弊社のコードベースも上記のアーキテクチャを採用し、大幅なコード削減を達成しました。
おまけ: 公式 Android ガイダンスが提唱するアーキテクチャと、クリーンアーキテクチャの違い
公式 Android ガイダンスが提唱するアーキテクチャとクリーンアーキテクチャには違いが多いです。
Now In Android には過去このような Discussions があり、ここでクリーンアーキテクチャとの違いについて議論されています。
簡単にまとめると、以下になります。
依存関係の方向(Dependency Direction)
| クリーンアーキテクチャ | 公式 Android ガイダンス |
|---|---|
| データ層 が ドメイン層 に依存 | ドメイン層 が データ層 に依存 |
ドメイン層の扱い
| クリーンアーキテクチャ | 公式 Android ガイダンス |
|---|---|
| 必須 | 任意(Optional) |

クリーンアーキテクチャでは ドメイン層 を中心として設計されていますが、
公式 Android ガイダンス では データ層 を中心として設計する形になっています。
これは大抵の Android アプリはビジネスロジックをサーバーに任せるケースが多いためです。
まとめ
「Clean Architecture の純粋さ」を守ることよりも、「チームの開発生産性」と「コードの実用性」を優先する選択をしました。
最初は「レイヤーを飛ばすこと」に抵抗がありましたが、Google のガイドラインという後ろ盾と、実際のコードのスッキリ具合を見て、今ではチーム全体がこの変更をポジティブに捉えています。
もし、「UseCase を書くのが面倒だ」「コードが無駄に多い」と感じているなら、一度 「その UseCase は本当に必要か?」 をチームで話し合ってみてはいかがでしょうか。