
この記事は every Tech Blog Advent Calendar 2025 の 21日目の記事です。
はじめに
こんにちは。
開発本部 開発1部 デリッシュリサーチチームでデータエンジニアをしている吉田です。
今回はコンピュートシステムテーブルとDatabricks Genie Research Agentを利用して、Jobのコンピュートリソースの最適化を試みた事例をご紹介します。
背景
これまで、Databricks Jobに割り当てるコンピュートリソースの最適化は、実際の実行メトリクスをUI上で確認しながら手動で調整を行う必要があり、手間のかかる作業でした。
しかし、system.compute.node_timeline テーブルが追加されたことにより、コンピュートリソースの利用状況に関する詳細なメトリクスをSQLで直接取得できるようになりました。
このテーブルをGenieに連携させることで、メトリクスに基づいた分析が可能になり、Genieを活用して最適なコンピュートリソース構成の提案を受けることができるようになります。
system.compute.node_timelineテーブル
system.compute.node_timeline テーブルは、Databricks上のコンピュートリソース(All-Purpose Compute, Jobs Compute等)におけるノードレベルのリソース使用状況を記録するシステムテーブルです。
各ノード(ドライバーおよびワーカー)について、1分粒度でCPU使用率、メモリ使用率、ディスクI/O、ネットワークトラフィックなどの主要なメトリクスが格納されています。
主なスキーマは以下の通りです(一部抜粋)。
| カラム名 | 説明 |
|---|---|
cluster_id |
クラスターID |
instance_id |
インスタンスID |
node_type |
ノードタイプ(例: i3.xlarge) |
driver |
ドライバーノードか否か (boolean) |
cpu_user_percent |
ユーザーランドでのCPU使用率 (%) |
mem_used_percent |
メモリ使用率 (%) |
start_time / end_time |
計測期間(1分間隔) |
これまでGangliaなどのUIでグラフとして確認していた情報が、SQLで直接クエリ可能なテーブルとして提供されるようになった点が特徴的です。 これにより、特定のJob実行時のリソース使用率の平均やピーク値を集計したり、リソース余剰が常態化しているクラスターを抽出したりといった分析が容易になります。
今回はこのテーブルのデータをGenie(DatabricksのAIアシスタント機能)に参照させることで、人間がグラフを目視で確認する代わりに、AIに最適なリソース構成を提案してもらうフローを構築してみます。
Genie Research Agentとは
Databricks Genie Research Agent(以下、Research Agent)は、従来のGenieの機能を拡張し、多段階の推論と仮説検証を用いて複雑なビジネス上の質問に取り組むことができるAIエージェントです。
通常のGenieがユーザーの質問に対して単発のSQLクエリを生成・実行して回答するのに対し、Research Agentは以下のような高度なプロセスを実行します:
- 調査プランの作成: 質問に対する最適なアプローチや検証すべき仮説を立案します。
- 反復実行: 複数のSQLクエリを実行し、その結果(中間データ)を分析して、必要に応じて次のクエリを調整するループ処理を行います。
- 包括的なレポート: 最終的に、調査結果のサマリー、根拠となるデータ、可視化グラフ、そして具体的な推奨事項を含む詳細なレポートを生成します。
今回の「Jobのリソースを最適化するにはどうすればよいか?」という問いは、単一のクエリで解決する問題ではなく、「CPUの使用状況はどうだったか?」「メモリに余裕はあるか?」「ボトルネックはどこか?」といった複数の観点での深掘りが必要となるため、Research Agentの強みが活かせます。
Research Agentを利用する
今回、以下のテーブルを登録したGenie Spaceを利用します。
system.lakeflow.jobs- Jobの実行履歴
system.billing.usage- 課金リソースの使用状況
system.billing.prices- SKU価格
system.compute.node_timeline- ノードレベルのリソースメトリクス
実際に以下の質問を投げてみます。
〇〇Jobについて、コンピュートリソースを最適化したいです 現在のリソース使用量からドライバーノードとワーカーノードそれぞれに最適なインスタンスタイプを教えて下さい また、ストレージが付属しないインスタンスタイプの場合、最適なEBSボリュームの容量も教えて下さい
するとResearch Agentは以下のように、複数のクエリを実行し探索的なデータ分析を行います。
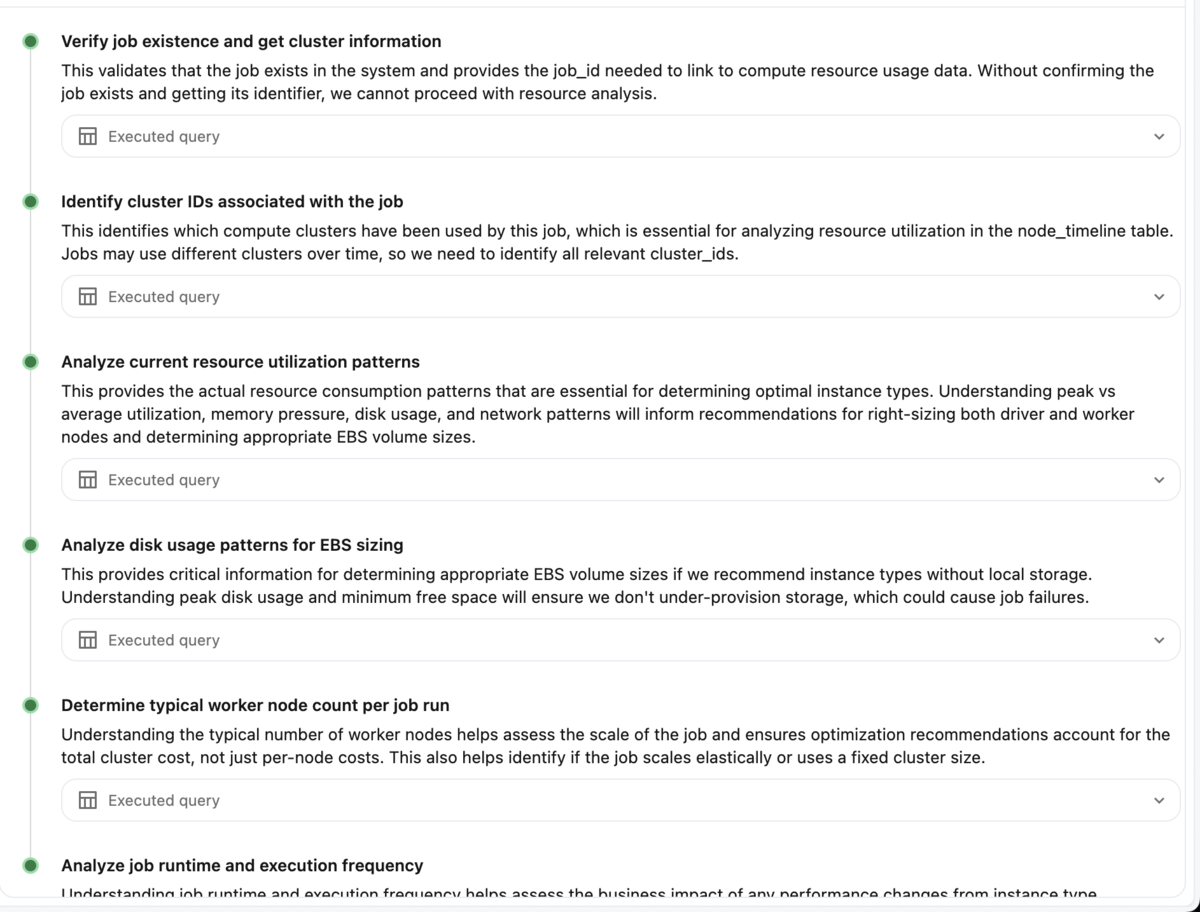
内容をみると、まずはJobの実行IDを特定し、次にその実行におけるクラスターIDを取得、そしてnode_timelineからCPU/メモリ使用率を集計する、といった多段階の推論が行われていることがわかります。
最終的に以下のような詳細なレポートと提案が出力されました。

レポートによると、対象Jobはメモリ使用率が平均25%程度と低く、CPUリソースも余裕があることが判明しました。 この結果に基づき、Research Agentからは以下のような具体的な構成変更が推奨されました:
- インスタンスタイプの変更: メモリ最適化インスタンス(
r5d.largeなど)から、より安価な汎用インスタンス(m5d.large)への変更 - ワーカー数の削減: オートスケーリングの最大数を8台から4台へ縮小
特筆すべきは、単に「使用率が低い」という指摘にとどまらず、実際のAWSインスタンスタイプ名を挙げて具体的な代替案を提示してくれる点です。
まとめ
system.compute.node_timeline の登場により、Databricks上のコンピュートリソースの実際の利用状況が詳細に可視化されるようになりました。
さらに、Genie Research AgentのようなAIエージェントを活用することで、膨大なメトリクスデータの中から「どこを改善すべきか」というインサイトを自動で抽出し、具体的なアクションプランにまで落とし込むことが可能になります。
これまでUIを確認する必要があったリソース調整を、効率的に最適化できるこの手法は、コスト削減と運用効率化の両面で非常に有用であると感じました。