
はじめに
はじめまして。 データストラテジストの田中です。普段は『DELISH KITCHEN』レシピ視聴実態の可視化やオーディエンス配信のレポート作成、サービス好意度の分析などの業務を行っています。
サービス好意度など定性的な要素が多い分析ではWEBアンケート調査のデータを活用していますが、WEBアンケート調査のローデータは質問内容がカラムとして横持ちで存在することが多いのが特徴です。
今回はデータベースでも扱いやすいよう「Apache Spark環境下で横持ちのデータを縦持ちにする」TIPSをお伝えします。
stack関数を用いて縦持ちにする
Spark SQLにてデータを横持ちから縦持ちにするにはstack関数を使用します。
stack関数については、Apacheより公式ドキュメントが提供されていますので、詳細は下記リンクをご覧ください。
サンプルデータ
横持ちのサンプルデータとして、アンケートデータに近い形のものを用意しました。
+------+------+---+------+--+--+-----------+--+ |sample|gender|age| area|Q1|Q2| Q3|Q4| +------+------+---+------+--+--+-----------+--+ | AAA| 1| 40| Tokyo| 1| 5| 特になし| 0| | BBB| 2| 15| Shiga| 2| 6| アプリを見て| 1| | CCC| 1| 20| Osaka| 3| 7| 広告を見て| 0| | DDD| 1| 55|Nagoya| 4| 8| null| 1| +------+------+---+------+--+--+-----------+--+
各ユーザID(sample)毎に付帯情報(gender 〜 area)と質問内容(Q1 〜 Q4)の回答結果が1行ずつ積まれています。今回はユーザIDと付帯情報に紐づく形で、質問内容を縦持ちにしたい場合の実装例を提示いたします。
実装方法
ドキュメント通りですとstack関数はSELECT stack(n, col1, col2 ...)と記述し、「col1, col2 ...」を「n」行で分割するといった仕様になります。
サンプルデータではSELECT stack(4, Q1, Q2, Q3, Q4)と記述しても良いのですが、実際のケースシナリオを想定した場合、汎用的に使えるよう質問内容のカラム情報を動的に取得できることが望ましいです。汎用性を加味した実装例を以下に提示します。
実装例
import org.apache.spark.sql.functions._
val result = data.columns.filter(x => x.contains("Q")).map{
v =>
data.select($"sample", $"gender", $"age", $"area",expr(s"stack(1,'$v',$v) as (q_id, q_value)"))
}.reduce(_ unionByName _)
display(result)
質問内容がスケールすることを考慮し、columnsを使用しカラム名を取得、filterを使用し質問内容のカラム名のみ抽出を行っています。
抽出したカラム名の値をmapにて、1つずつ読み出し、縦積みにしています。$vのようにカラム名を指定すると回答結果だけが縦積されるため、カラム名も'$v'で取得する形にしています。
最後に質問内容のカラム情報を1つずつ縦積みしたものをreduce(_ unionByName _)で結合しています。
出力結果
各ユーザIDと付帯情報に紐づく、質問内容のカラム名q_idと回答結果q_valueの一覧を出力することができました。
+------+------+---+------+----+------------+ |sample|gender|age| area|q_id| q_value| +------+------+---+------+----+------------+ | AAA| 1| 40| Tokyo| Q1| 1| | BBB| 2| 15| Shiga| Q1| 2| | CCC| 1| 20| Osaka| Q1| 3| | DDD| 1| 55|Nagoya| Q1| 4| | AAA| 1| 40| Tokyo| Q2| 5| | BBB| 2| 15| Shiga| Q2| 6| | CCC| 1| 20| Osaka| Q2| 7| | DDD| 1| 55|Nagoya| Q2| 8| | AAA| 1| 40| Tokyo| Q3| 特になし| | BBB| 2| 15| Shiga| Q3| アプリを見て| | CCC| 1| 20| Osaka| Q3| 広告を見て| | DDD| 1| 55|Nagoya| Q3| null| | AAA| 1| 40| Tokyo| Q4| 0| | BBB| 2| 15| Shiga| Q4| 1| | CCC| 1| 20| Osaka| Q4| 0| | DDD| 1| 55|Nagoya| Q4| 1| +------+------+---+------+----+------------+
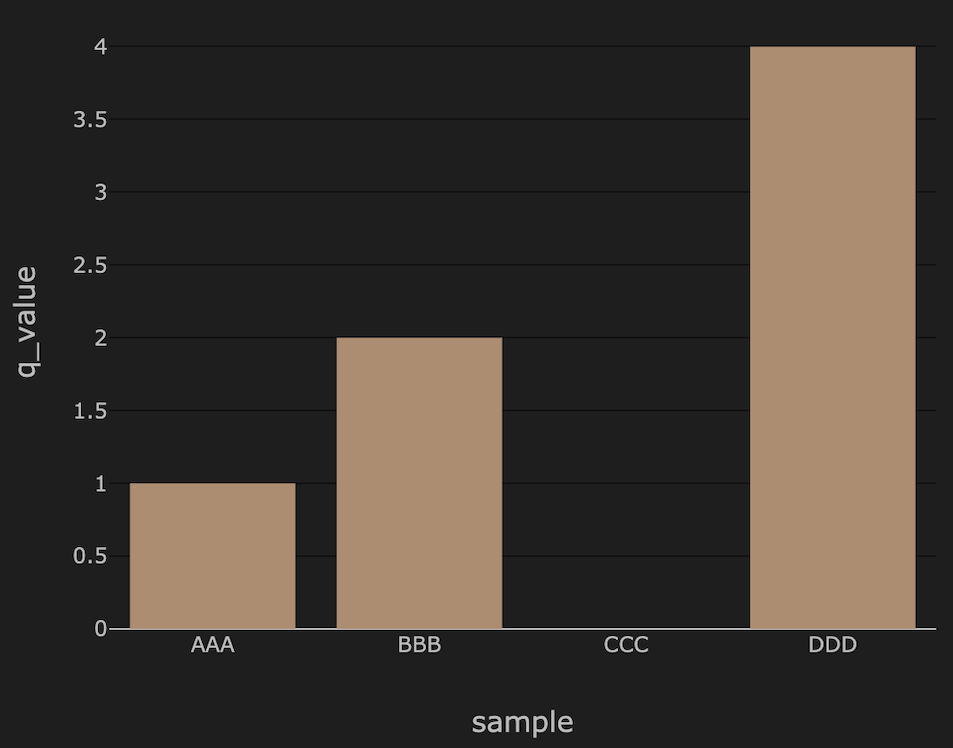
また別のサンプルデータを元に、Databricksのdisplay関数でプロットを作成しました。
縦持ちのテーブルのメリットは下記プロット結果のように質問全体での足し上げがしやすいことと、その他2軸以上のグラフを作成するときにも便利なことです。
サンプルデータ
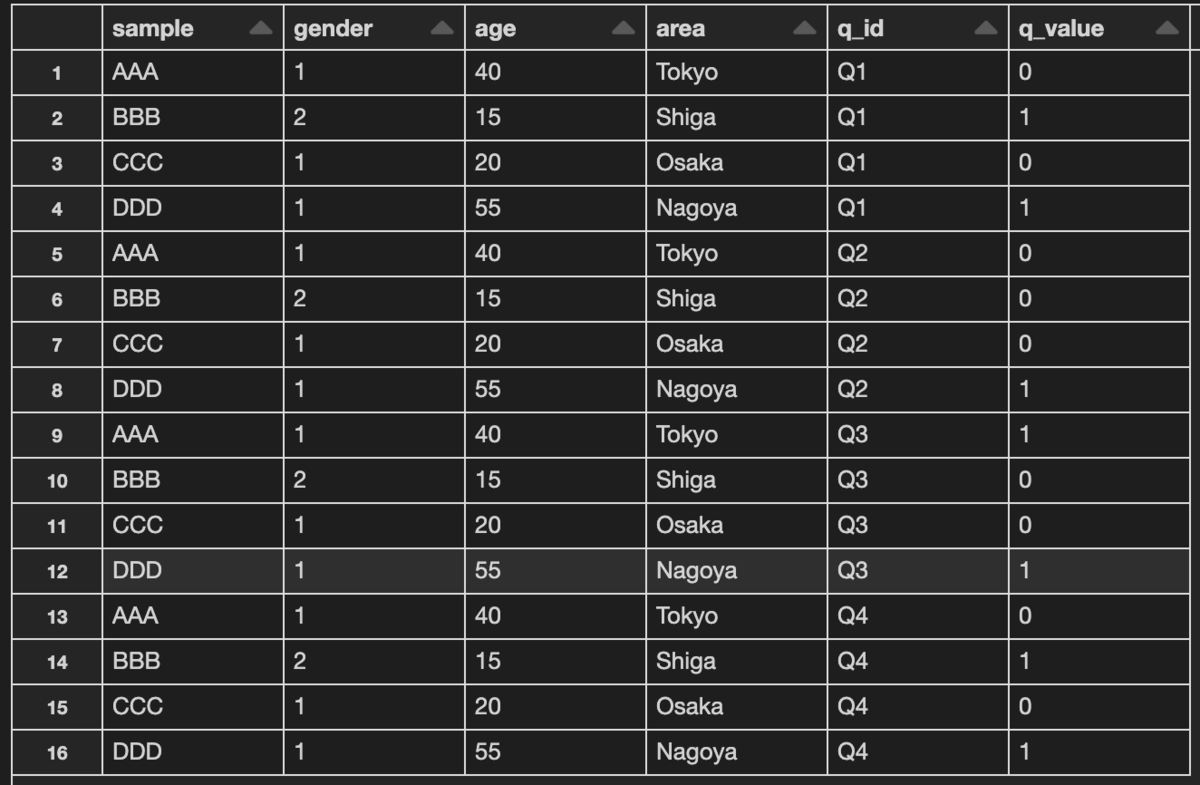
プロット結果
最後に
実装自体はシンプルですが、stack関数の実装例が少ないと感じたため取り上げてみました。
最後まで閲覧いただきありがとうございました。