
はじめに
エブリーでは日々大量のデータをDatabricksで処理し、MetabaseなどのBIツールで可視化や分析を行っています。
MetabaseとDatabricksのデータベースを接続する方法がまとまっている記事があまりなかったので、ここにまとめたいと思います。
手順
1.Databricks用のJDBCドライバー入りのMetabaseイメージを作成
2.MetabaseとDatabricksを接続する
1. databricks用のJDBCドライバー入りのMetabaseイメージを作成
こちらのフォークリポジトリを使って、ローカルにDatabricks用のJDBCドライバー入りのMetabaseイメージを作成します。
git clone https://github.com/rajeshkumarravi/metabase-sparksql-databricks-driver.git cd metabase-sparksql-databricks-driver curl -L "https://github.com/rajeshkumarravi/metabase-sparksql-databricks-driver/releases/download/v1.2.0/sparksql-databricks.metabase-driver.jar" -o sparksql-databricks.metabase-driver.jar
Dockerfileの一部を修正します。
FROM metabase/metabase:v0.37.0.2 ENV MB_DB_CONNECTION_TIMEOUT_MS=60000 #コメントアウトor削除 #COPY ./target/uberjar/sparksql-databricks.metabase-driver.jar /plugins/ COPY sparksql-databricks.metabase-driver.jar /plugins/
「metabase-blog」と名前をつけたMetabaseイメージを作成します。
docker build -t metabase-blog .
コンテナを作成し、http://localhost:3000/ にアクセスしてMetabaseの画面が表示されれば成功です。
docker run -d -p 3000:3000 --name metabase metabase-blog
2. MetabaseとDatabricksを接続する
Metabaseの管理画面から「データベース」→「データベースを追加」をクリックします。
DatabricksからMetabaseと接続したいクラスターの「configuration」に進み、「Advanced Options」から「JDBC/ODBC」に表示される値を確認します。
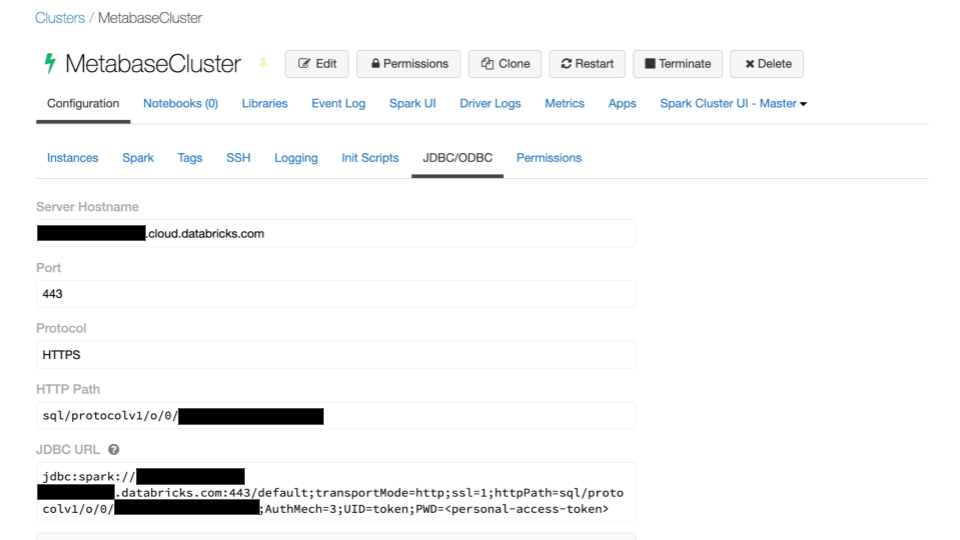
これらをMetabaseに入力していきます。
「データベースのタイプ」→ Spark SQL (Databricks)
「ホスト」→ databricks画面の「Server Hostname」
「データベース名」→ default
「ユーザー名」→ token
「パスワード」→ Databricksのアクセストークン
「追加のJDBC接続文字列オプション」→ Databricks画面の「JDBC URL」の <personal-access-token> を1つ上の「パスワード」に置き換えたもの
「簡単なフィルタリングと要約を行うときに自動的にクエリを実行する」→ False
「データベースが大きいため、Metabaseの同期とスキャンのタイミングを選択します」→ True
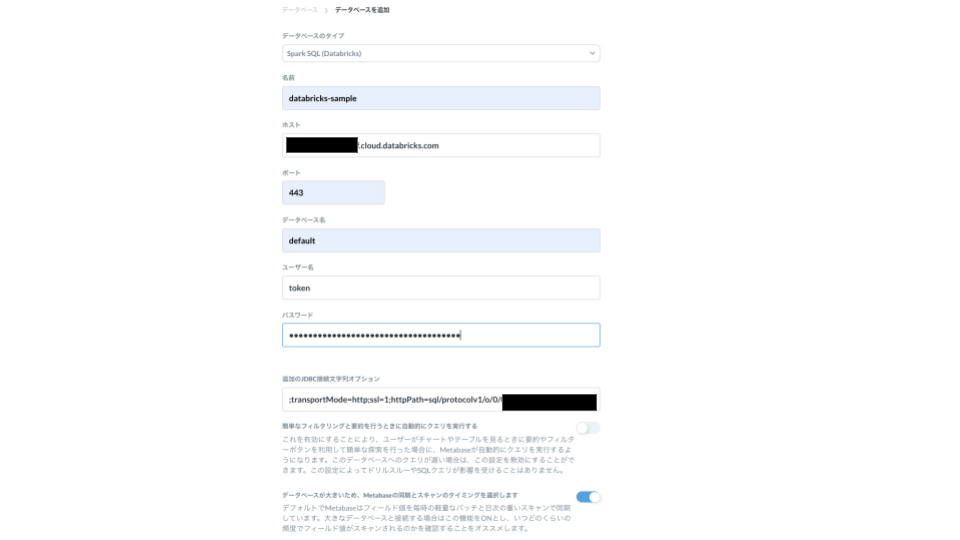
これでデータベースとの接続は完了です。
3. 確認する
最後にDatabricksのサンプルデータベース「default」にあるテーブル「smsdata」にクエリを投げてみます。
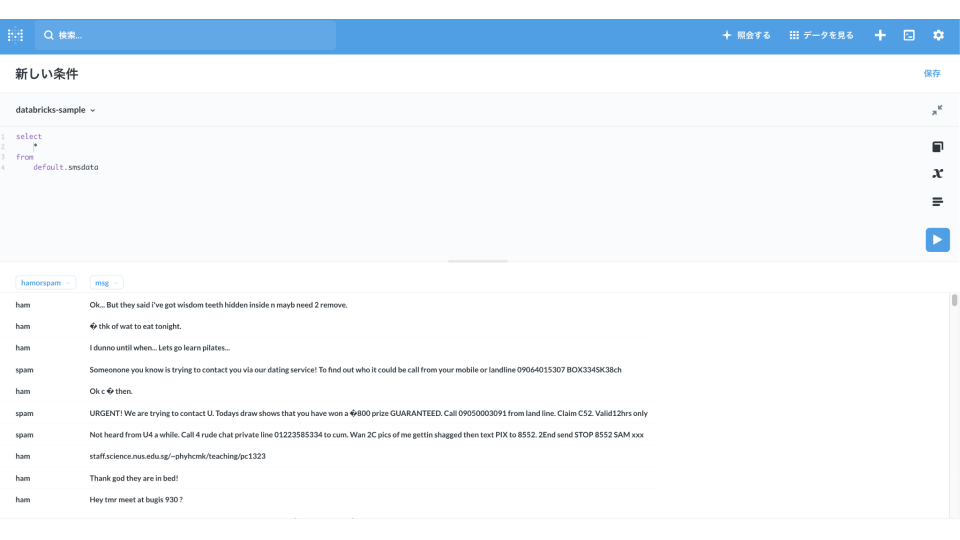
ちゃんと接続されているようです。
以上です。最後まで閲覧いただきありがとうございました。