
はじめに
はじめまして。DELISH KITCHEN 開発部でバックエンド開発を担当している池と申します。2021 年 9 月にエブリーに転職してバックエンドエンジニアとして働いています。入社して 3 ヶ月ですがサーバーサイド、フロントエンド、クラウド、CI/CD など多岐に渡る技術領域を触ることができ、とても有意義な毎日を送っています。
今回はこれまでに触ってきた技術の中から Datadog APM を試した際の内容についてご紹介したいと思います。
Datadog APM とは
ご存知の方も多いとは思いますが、Datadog は SaaS 型運用監視サービスです。様々なプラットフォームにおけるホストの監視、アプリケーション監視、ログ蓄積などシステム監視全般を Datadog 一つで行うことができます。その中で APM(Application Performance Management)は、名前の通りアプリケーションのパフォーマンスを監視する機能になります。
詳細は後述しますが、Datadog APM は分散トレーシングという監視の手法を用いており、マイクロサービスのような分散したアーキテクチャのフロントエンドからデータベースまで、エンドツーエンドのアプリケーション監視を行うことができます。
下記は具体的に計測できるメトリクスの一例です。
- 時系列でのリクエスト数・レイテンシー、エラー数
- エンドポイント毎のリクエスト数・レイテンシー、エラー率
- 各リクエストの処理時間・ボトルネック
分散トレーシングについて
分散トレーシングは分散されたアーキテクチャのアプリケーションを監視するための手法です。 マイクロサービスのような複数システムから構成されるアーキテクチャでは、複数のサービスをまたいで処理が動くため、全体の振る舞いを把握することが難しいという課題があります。 また、障害発生時に原因を特定することも困難です。 分散トレーシングの手法を用いることで、サービス間をまたいだ処理の計測や可視化が可能になり、それら課題の解決に繋がります。
簡単に用語を説明します。分散トレーシングの主要な用語としてトレース(Trace)とスパン(Span)があります。
※ 公式のAPM 用語集から抜粋
| 用語 | 意味 |
|---|---|
| トレース(Trace) | トレースは、アプリケーションがリクエストを処理するのに費やした時間と、このリクエストのステータスを追跡するために使用されます。各トレースは、一つまたは複数のスパンで構成されます。 |
| スパン(Span) | スパンは、特定の期間における分散システムの論理的な作業単位を表します。複数のスパンでトレースが構成されます。 |
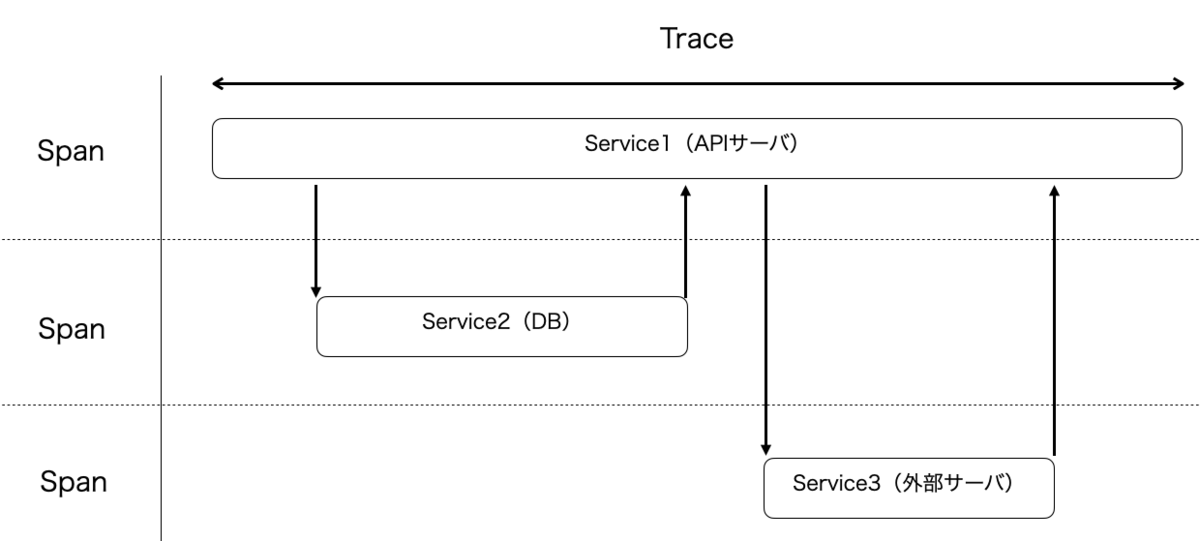
例えば、API サーバが一つのリクエストを受け取ってからレスポンスを返却する一連の処理を計測するとします。よくある API では、クライアントからリクエストが送られてきた後、DB や外部サーバなど複数のサービスと連携してデータを処理し、ビジネスロジックを経由して最終的にレスポンスが返却されると思います。
それらをトレースとスパンを用いて表すと次の図のようになります。各サービスにおける処理の単位がスパンで表され、複数のスパンで構成される一連の全体処理がトレースで表されます。
実装方法
前提
今回は下記の前提のもと、 Datadog APM の導入および、一つの API リクエストを受け取ってからレスポンスを返却するまでのトレース計測の実装を行います。
- Go で実装されている API サーバでトレース処理を実装する
- Web フレームワークには echo を利用
- API サーバは AWS ECS で管理
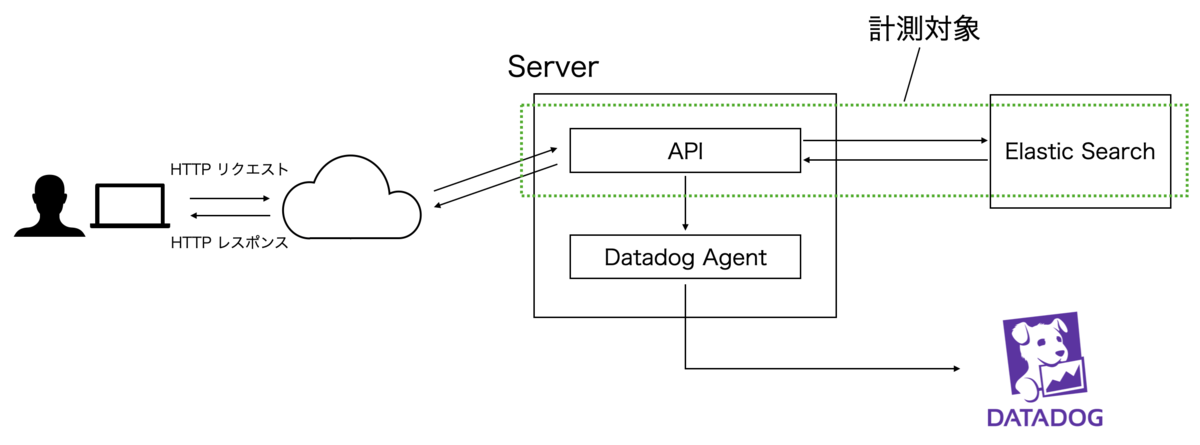
次の図は今回取り扱う全体のイメージ図です。Server へ Datadog Agent を導入し、API アプリケーション本体へトレース計測の処理を実装します。
datadog-agent の導入
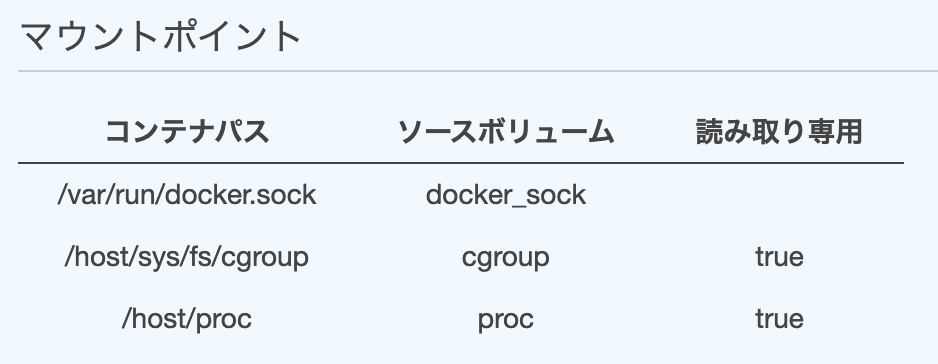
datadog-agent は計測対象の API が動作しているサーバーで起動される必要があります。公式の datadog-agent コンテナを AWS ECS のタスク定義から起動することで、簡単に導入することができます。
次のようにコンテナの定義をタスク定義に設定します。詳細なセットアップ方法は公式ページを参照ください。

トレースの実装
Datadog APM の trace ライブラリを導入します。
go get gopkg.in/DataDog/dd-trace-go.v1/...
トレースエージェントにホスト設定を伝えます。
import( "gopkg.in/DataDog/dd-trace-go.v1/ddtrace/tracer" // traceライブラリ追加 ... ) func main() { ... resp, err := http.Get("http://169.254.169.254/latest/meta-data/local-ipv4") bodyBytes, err := ioutil.ReadAll(resp.Body) host := string(bodyBytes) if err == nil { //set the output of the curl command to the DD_Agent_host env os.Setenv("DD_AGENT_HOST", host) // tell the trace agent the host setting tracer.Start(tracer.WithAgentAddr(host)) defer tracer.Stop() }
次にスパンを実装します。
スパンの実装には Datadog が公式でサポートしている専用の統合ライブラリを利用します。この専用の統合ライブラリは、一般的に広く用いられている Go の Web フレームワークや、データストア、ライブラリを Datadog APM に統合するために作られているライブラリで、それら Web フレームワークやライブラリと互換性を持っています。(一覧はこちらを参照ください。)
今回の例では、echo と olivere/elastic ライブラリを専用の統合ライブラリに置き換えます。
echo を専用の統合ライブラリに置き換える
import( ddEcho "gopkg.in/DataDog/dd-trace-go.v1/contrib/labstack/echo" //追加 "github.com/labstack/echo" ... ) func main() { ... e := echo.New() e.Use(ddEcho.Middleware(ddEcho.WithServiceName("echo-service-name-test")))
専用の統合ライブラリを import し、datadog echo で準備されている Middleware をecho.Useすることで統合することができます。
統合することで、datadog echo によって API リクエスト処理のスパンが計測されて datadog-agent に送られ、Datadog の UI 上で可視化されるようになります。
olivere/elastic を専用の統合ライブラリに置き換える
次に olivere/elastic を専用の統合ライブラリに置き換えます。
import() elastictrace "gopkg.in/DataDog/dd-trace-go.v1/contrib/olivere/elastic" ... ) func NewElasticSample() *ElasticSampleImpl { tc := elastictrace.NewHTTPClient(elastictrace.WithServiceName("my-es-service-test")) cli, _ := elastic.NewSimpleClient( ... elastic.SetHttpClient(tc), )
echo と olivere/elastic を同じトレースとして認識させるためには、同じ Context を利用する必要があります。
今回は簡易的に特定の elastic の呼び出し時に echo の Context を渡すように実装して動作を確かめました。
// SampleMethod func (s *ElasticSampleImpl) SampleMethod(c echo.Context) { svc := s.client.Search().Index("Sample") ctx = c.Request().Context() result, err := svc.Do(ctx) ...
以上の実装により、各サービス(echo、elasticsearch)の処理時間が計測されるようになりました。

また、ここに示すのは一部ですが、様々なパフォーマンスデータを UI 上で確認することができ、それらのデータに対してアラート設定や、リアルタイム検索の機能なども実行可能です。
- エンドポイント毎のリクエスト数
- 時系列毎のリクエスト数・レイテンシー
- レイテンシー分布



Continuous Profiler の導入
次に Datadog Continuous Profiler という機能を試します。この機能はアプリケーションの性能をプロファイリングする機能です。
APM と Continuous Profiler の双方を有効化することで、Code Hotspots という機能によりコードベースでパフォーマンスのボトルネックを特定することができると記載があったため、試してみました。
APM 分散型トレーシングと Continuous Profiler の双方が有効化されたアプリケーションプロセスは自動的にリンクされるため、Code Hotspots タブでスパン情報からプロファイリングデータを直接開き、パフォーマンスの問題に関連する特定のコード行を見つけることができます。
※ 引用元:https://docs.datadoghq.com/ja/tracing/profiler/connect_traces_and_profiles/
Go では下記のプロファイルタイプがサポートされています。(詳細はこちらを参照ください。)
- CPU Time
- Allocations
- Allocated Memory
- Heap Live Objects
- Heap Live Size
- Mutex
- Block
- Goroutines
プロファイリングの有効化は、次のように数行で実装できます。
import( "gopkg.in/DataDog/dd-trace-go.v1/profiler" ... ) func main() { ... if err := profiler.Start( profiler.WithService("profiler-service-name"), profiler.WithEnv("profiler-env-test"), profiler.WithProfileTypes( profiler.CPUProfile, profiler.HeapProfile, // The profiles below are disabled by // default to keep overhead low, but // can be enabled as needed. // profiler.BlockProfile, // profiler.MutexProfile, // profiler.GoroutineProfile, ), ); err != nil { log.Fatal(err) } defer profiler.Stop()
上記の実装を行うだけで、プロファイリング結果が Datadog の UI 上で可視化されます。
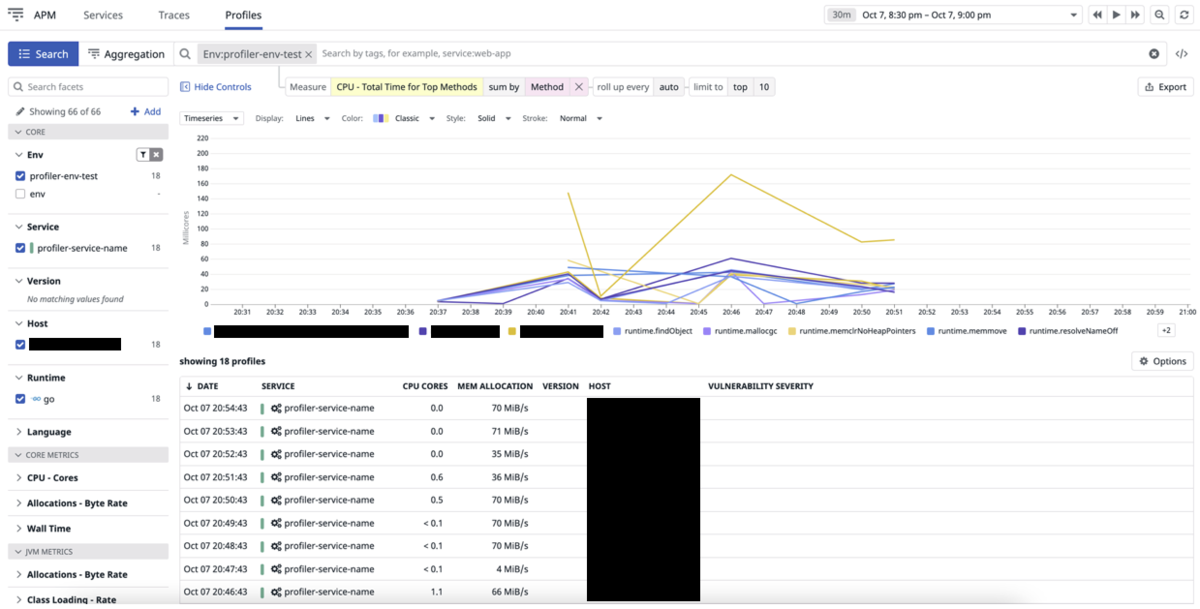
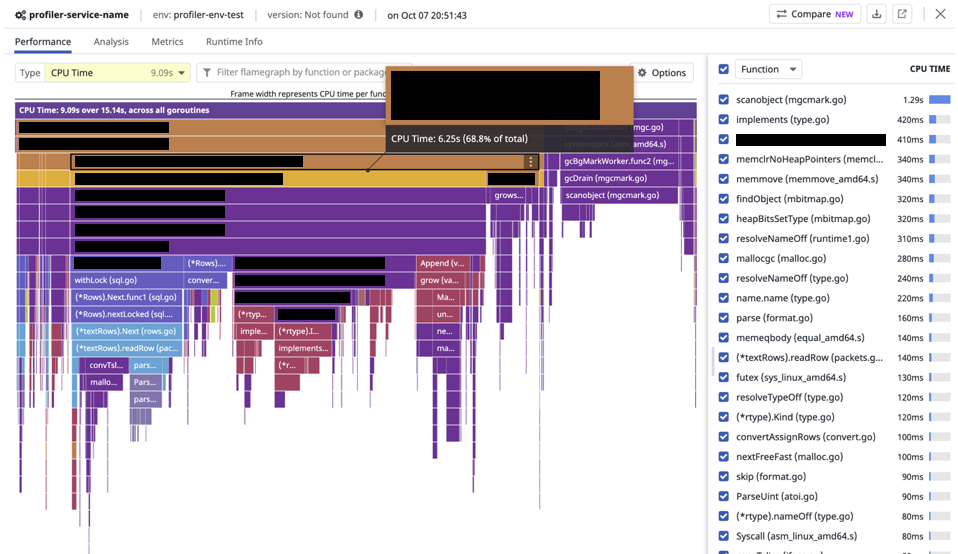
Code Hotspots
残念ながら Code Hotspots 機能はまだ Go に対応していませんでした。

dd-trace-go の github を見ると Code Hotspots に関する PR が出ているので開発中であることがわかります。 アップデートに期待します。
料金 / サンプリング
最後に料金とサンプリングについてご紹介します。 (※2021/10 時点での料金体系です。)
料金
公式の料金ページから最小料金と加算費用を抜粋しました。
| 年払い | |
|---|---|
| 最小料金(1 ホスト、1 か月あたり) | $31(オンデマンド払いは$36) |
| プラス料金:スパンの取り込み | APM ホストあたり 150GB (すべての APM ホスト平均)無料、その後 $0.10 /GB |
| プラス料金:スパンの保存 | APM ホストあたり Indexed Span 100 万件 (すべての APM ホスト平均)、その後 ・保存期間 7 日、$1.27 / 100 万スパン / 月 (年払いまたはオンデマンド払いで $1.91) ・保存期間 15 日、$1.70 / 100 万スパン / 月 (年払いまたはオンデマンド払いで $2.55) ・保存期間 30 日、$2.50 / 100 万スパン / 月 (年払いまたはオンデマンド払いで $3.75) |
| プラス料金:アドオン AWS Fargate | $2 / タスク |
簡単にですが、以下の仮定をもとにざっくりと料金を試算します。
仮定
- 月の総リクエスト数:1 億リクエスト(1 日あたり約 333 万リクエスト)
- ホスト数:10 ホスト
- 1 リクエスト:3 スパン
- スパンの保存期間:7 日
- 年払い
- スパンの取り込みは試算が難しいため除く
- AWS Fargate アドオンのプラス料金は掛からない
- $1 = 113 円換算
料金試算
- 最小料金:$31 × 10 ホスト = $310
- スパン数:1 億リクエスト × 3 スパン = 3 億スパン
- スパンの保存料金:(3 億スパン - 100 万スパン) ÷ 100 万スパン × $1.27 ≒ $380
- 総料金:$310 + $380 = $690 ≒ 77,970 円
本来はここに、スパンの取り込みに応じたプラス料金と、もし利用があれば AWS Fargate アドオンのプラス料金が加算されます。 この試算のように全トレースデータを取り込んで保存すると大きな費用がかかるため、実際には一部のデータを取り込むようにサンプリングすることで費用を抑えつつ運用する形が現実的だと考えられます。
サンプリング
サンプリングは次の図の「Your instrumented applications」と「Intelligent retention & custum filters」の 2 箇所で設定することができます。前者はサーバで設定する Datadog に送るトレースのサンプリング設定です。後者は送られてきたトレースに対して Datadog の UI 上で設定するトレース保存のフィルター設定になります。
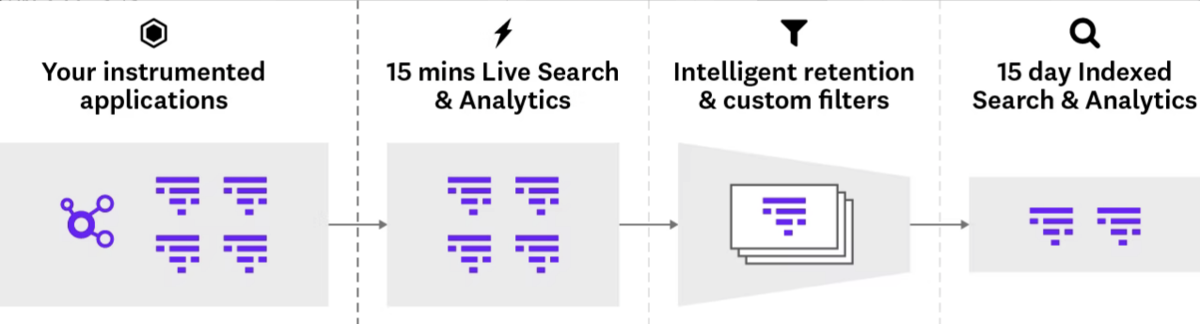
※引用元:https://docs.datadoghq.com/ja/tracing/trace_retention_and_ingestion
本記事ではサーバ側のサンプリング設定についてご紹介します。
サーバ側のサンプリングは、デフォルト設定で 50 トレース / 1 秒まで 100%のトレースを取り込まれる設定になっています。超えた分は Datadog Agent によって自動的に選択/削除されて Datadog へ送られます。
このデフォルトのサンプリング率は、下記の環境変数を設定することで変更できます。
DD_TRACE_SAMPLE_RATE = 1.0
基本的にはDD_TRACE_SAMPLE_RATEに基づいて Datadog Agent が自動的にサンプリングしてくれるのですが、Span にMANUAL_KEEP、MANUAL_DROP タグを追加することで、優先的に 100%保持・削除するように設定できます。
// 100%削除 span.SetTag(ext.ManualDrop, true) // 100%保持 span.SetTag(ext.ManualKeep, true)
ここまでがサーバ側で設定できるサンプリング設定になります。
最終的には Datadog の UI 上で設定するフィルターを通して保存されるトレースが決定されるので、そちらの詳細はこちらを参照ください。
まとめ
今回 Datadog APM を触ってみて、公式のドキュメントが豊富だったため、大きく迷わずに導入を進めることができました。一方、既に運用されている複数のサービスにおいて導入・整備を進める作業にコストがかかることもわかりました。特に、サービス間のスパンを紐付けるために同一の Context を用いる設計にする必要があることや、専用の統合ライブラリに未対応のライブラリも多くあることから、既存システムへの導入の難しさを感じました。
しかし、本記事では紹介できていない機能もとても数多くあり、導入して環境整備さえできてしまえば、Datadog 一つにシステム監視ツールを統一でき、相応のメリットがあると思います。
また、CodeHotspots が Go に対応されれば、コードベースのパフォーマンス分析が可能になってメリットも増えるため、アップデート情報を待ちたいと思います。
最後まで閲覧いただきありがとうございました。少しでも参考になれば幸いです。