
この記事は every Tech Blog Advent Calendar 2024(夏) 10 日目の記事です。
はじめに
こんにちは。DELISH KITCHEN 開発部の村上です。
エブリーでは4月に第4回挑戦weekを実施しました。挑戦week5日間の中で私たちのチームはナレッジ活用のために社内ChatAppに社内ドキュメントを参照できる仕組みづくりに取り組みを行いました。今回はその中でRAG基盤のPoCを行ったので、その取り組みについて紹介します。
挑戦weekについてはこれらの記事で初回の取り組みの様子やCTOの挑戦weekに対する考えが知れるのでぜひ読んでみてください。
https://everything.every.tv/20230428
PoCの背景
まずは、なぜ社内ナレッジ活用のためのRAG基盤のPoCを行うに至ったか、その背景について説明します。
エブリーでは社内のナレッジを蓄積する場所として、ConfluenceやGoogle Docs、Google Slideを活用しています。こうしたナレッジが溜まっていくこと自体は良いことですが、以下のような問題が社内でも起こることがありました。
- ドキュメント自体の量が多くなってきており、ある程度整理していても欲しい情報に簡単に辿りつけない
- 探す手間を省くために担当者への問い合わせが増え、コミュニケーションコストがかかってしまう
元々社内ではStreamlitを用いて作られたOpenAI APIベースの社内ChatAppがあり、業務効率化に活用されています。しかし、現状のChatAppは業務利用で安全に生成AIを活用するための基盤であり、社内ドキュメントに溜まったナレッジを外部データソースとして読み込んで、それらのデータに基づいて質問に回答することはできませんでした。
そこで今回はこうした課題を解決すべく、社内で溜まったナレッジに基づいて回答できる機能をChatAppに組み込むためのRAG基盤のPoCを実施することになりました。
RAGとは
RAGとはRetrieval Augmented Generativeのことで、Retrievalの『検索』工程とGenerativeの『生成』工程を組み合わせることによってLLMが内部では持たない外部の知識に基づいた回答の生成を行うことができます。Retrivalでは与えられた質問に対して外部データソースから関連する情報を取り出し、GenerativeではRetrivalで抽出したデータをpromptにコンテキストとして渡すことでその内容に沿った回答を生成します。
RAGの詳しい動作の解説に関しては以前エブリーのテックブログで紹介されたこちらの記事をみていただけると理解が進むと思います。
RAG基盤の検討
RAG基盤を構築していく中で4つの選択肢を検討し、比較を行いました。
Amazon Q Business
Amazon Q BusinessとはAWSが企業用に提供するフルマネージドな生成AIサービスで、RAG基盤の提供からセキュアなChatインターフェースの提供までを全てサポートしてくれます。
行ったこと
- data source connector機能でのConfluence Connectorを使った外部データソースの準備
- Amazon Q Businessのチャット画面での社内ドキュメントに関するQ&Aを実施
メリット
- RAG基盤の構築や独自のChatインターフェースの提供を行わなくても良いため、工数が削減できる
- 外部サービスとのデータコネクタが豊富で接続のための実装をせずに導入することが容易
デメリット
- 現状では日本語対応がされておらず、使用には翻訳工程を挟む必要がある
- フルマネージドなため、他の選択肢と比較してもカスタマイズの余地が少ない
結果
Amazon Q Businessでは特に日本語のサポートがされておらず、日本語でのデータ保存とそれに対する質問に正常に動作することが困難な点が採用するサービスとしては厳しかったです。
実際にこの状態で利用するためには以下の各パートで翻訳工程を独自に挟む必要があります。
- data enrichment機能によるデータコネクタから取得したデータの前処理
- 質問、回答の入出力
こうなるとAmazon Q Businessのメリットがなくなってしまいます。とはいえ、メリットとして挙げられるデータコネクタ機能は魅力的で40以上ものサービスをサポートしているので、今後の日本語対応にも期待したいです。
Amazon Bedrock + Knowledge base
Amazon BedrockとはAWSが提供する基盤モデルを活用した生成AIアプリケーションを構築するサービスです。RAGを使わずとも基盤モデルを使うことはできますが、RAGの機能としてKnowledge baseがあり、今回は一緒に検証を行いました。
行ったこと
- 基盤モデルはClaude 3 Sonnetを採用
- Knowledge baseとしてデフォルト構成のS3 + OpenSearch Serverlessを採用
- API経由での社内ドキュメントに関するQ&Aを実施
メリット
- 自分で実装せずにRAGに関する様々な手法を簡単に組み込める
- 埋め込みモデルを使ったベクトル化
- ハイブリット検索の適用
- 参照ファイル名の返却
- AWS完結でリソース連携ができる
- 普段使ってるS3やOpenSearch、他サービスとの連携もスムーズ
デメリット
- RAGでの最新の手法を使いたい場合は精度向上でのカスタマイズの余地が限定的
- リージョンはオレゴン、バージニア北部限定
結果
Amazon Bedrockでは自由な基盤モデルの選択とKnowledge baseを活用することでRAGで試したい手法がすでに内部ロジックとして入っていたり、オプションとして用意されているのはかなりエンジニアの工数削減になりそうです。
例えば、直近ではAmazon Bedrockでハイブリット検索のサポートが発表されましたが、こういったRAG手法のアップデートにAWS側が追従してくれてすぐに使用可能な状態になるのは開発者としては嬉しいです。特にかなり早いスピードで手法が研究されているこの分野では日々世の中に出てくる新しい手法を自分たちで取り入れてついていくことはエンジニアのリソースが限られている場合には難しいので、Amazon Bedrockを使用する大きな理由になると感じました。
OpenAI Assistant API v2
Assistant APIはOpenAIが提供するアシスタント開発のためのRetrievalやCode Interpreterを利用できるAPIです。4月にはv2のリリースが行われ、RAGにおいてもfile_searchやvector_store機能の追加など大幅に強化されました。
https://platform.openai.com/docs/assistants/whats-newplatform.openai.com
行ったこと
- vector_storeへのデータ格納
- file_search機能を使ったRAGの処理を実装
- API経由での社内ドキュメントに関するQ&Aを実施
メリット
- OpenAIを利用したい場合のRAGの選択肢として一番工数が削減できる
- 埋め込みモデルを使ったベクトル化
- リランキング
- クエリRewrite
デメリット
- 後述する回答精度の検証においても精度が悪く、誤回答や参照ファイルの引用ができないケースが目立つ
- 1アシスタントにつき、1万件がファイル上限となる
- RAG周りの処理でのチューニングはかなり限定的
結果
Assistant APIを使うことでAmazon Bedrockと同じようにfile_searchを使うことでRAG周りの処理での最適化が行われるのは強みに感じました。ただ、Amazon Bedrockと比較するとファイルサイズでの制限事項があったり、オプションとして選択できる余地も限定的なため、その辺りは要件に合わせて判断する必要があります。
特に今回の検証で気になったのは精度面の部分です。他のRAG基盤と同じ質問をした場合にAmazon Qを除くと最も誤回答が多く、精度改善のためにはデータ投入の仕方などいくつか試しながら試行錯誤していくことになりそうです。
OpenAI Chat API + VectorDB(pinecone)
最後はOpenAIが提供するChatAPIとVectorDBを使った自前でのRAG基盤の構築になります。今回はVectorDBとしてpineconeを選択して検証を進めました。
https://platform.openai.com/docs/api-reference/chatplatform.openai.com
行ったこと
- ドキュメントデータをembeddings APIでベクトル化してpineconeに保存
- LangChainを使ったRAGの処理を実装
- 社内ドキュメントに関するQ&Aを実施
メリット
- 自前実装のため、ブラックボックス化されているところが少なくチューニングの自由度が高い
- すでにChatAPIを使用している基盤がある場合は追加実装で導入可能
デメリット
- 専属でメンテナンスできるチームがいない場合には、実装・運用コストが高い
結果
自前でVectorDBと組み合わせて実装を行う場合、その工夫の余地は大きいのが強みです。一方でその実装の自由度の高さはチーム状況によって大きなメリットになるか、デメリットになるか大きく分かれていきそうに感じました。Amazon Bedrockでも記載の通り、RAG周りでの手法の研究が急速に進展する中で、高精度を求めてチューニングできるチーム体制があれば非常に有効ですが、そうではない場合にはAmazon Bedrockのサービスでのサポートの方が自分たちが対応するより早いという結果になり、採用するメリットが薄れると思います。
各基盤の比較
ここまでそれぞれの選択肢のメリット、デメリットを記載してきましたが、最後に回答精度の検証も含めた比較を行いました。
質問と模範回答からなるテストデータを準備
社内のドキュメントデータとしてConfluenceの特定のワークスペースをHTMLで保存する形で用意しました。精度評価に関してはより厳密にやるのであればベクトル変換した結果の意味の近さで判定する手法もありますが、今回に関してはそれぞれのConfluenceページに対する質問とそれに対して回答する場合に正しくそのページIDを引用できたかを精度の指標としています。下記のようなデータセットを50問ほど用意しました。
[ { "question": "Google アカウントにログインできない場合、どうすればいいですか?", "answerID": "1990623256" }, { "question": "Zoom Roomを利用する具体的な手順を教えてください。", "answerID": "2027815464" }, { "question": "ビルの入館証を発行するにはどうすればいいですか", "answerID": "2182709419" }, ... ]
特に今回の社内独自で溜まった知識をもとに答えさせるような場合に間違った情報をさも正しい回答かのように振る舞ってしまうハルシネーションは極力避けたいですし、回答文言が間違えていたとしても参照するページを正しく引用できていれば利用者は自分でその回答の正しさを評価できるので重要な比較基準になります。
2024年4月時点での回答精度も含めたそれぞれのRAG基盤の比較を表にしてまとめました。
| RAG基盤 | カスタマイズ性 | 実装の容易さ | 正答率 |
|---|---|---|---|
| Amazon Q Business | × | △/× | - |
| Amazon Bedrock + Knowledge base | △ | ○ | 90% |
| Assistant API v2 | × | ○ | 50% |
| OpenAI API + pinecone | ○ | △ | 85% |
※Amazon Q Businessは日本語未対応のため、精度評価は実施していません
Amazon BedrockとOpenAI API + pineconeでは正答率に大きい差は今回では生まれず、どちらもほとんどチューニングをせずともある程度高い回答精度が出る結果となりました。一方で前述したようにAssistant API v2にはまだ回答精度面でいい結果が出ず、うまく参照ファイルを引用できないものも多かったです。
こうした比較検討の結果、現状の選択肢としては以下2点になりそうです。
- RAG基盤のメンテナンスにリソースを十分に取れる場合にはOpenAI API + VectorDBを使った自前開発
- AWSリソースとの連携を重視したり、RAG基盤開発でのリソースが十分に取れない場合にはAmazon Bedrock
Amazon Bedrockと社内ChatAppの繋ぎこみ
これまでの検討からエブリーでRAG基盤を構築する場合、Amazon Bedrockの導入の可能性が高い一方で社内での知見も少なかったため、Amazon Bedrockを選択した場合の社内ChatAppへの繋ぎこみを検証しました。
質問への回答テキストの生成
回答テキストの生成部分は以下のようにKnowledge baseとモデルを指定することで参照ファイルと回答を同時に取得することができます。参照ファイルが1件も見つからない場合には回答文言があってもそれを引用せずに固定文言を返すことで回答できない場合の案内も誘導できます。
def generate_text_from_knowledge_base(self, query): response = self.bedrock_client.retrieve_and_generate( input={'text': query}, retrieveAndGenerateConfiguration={ 'type': 'KNOWLEDGE_BASE', 'knowledgeBaseConfiguration': { 'knowledgeBaseId': self.kb_id, 'modelArn': self.model_arn, } } ) text_response = response['output']['text'] urls = set() # セットを使ってURLの重複を防ぐ # citationsからretrievedReferencesを処理する if 'citations' in response: for citation in response['citations']: if 'retrievedReferences' in citation: for ref in citation['retrievedReferences']: if 'location' in ref and 's3Location' in ref['location']: uri = ref['location']['s3Location']['uri'] file_name = urlparse(uri).path.split('/')[-1] # .html拡張子を削除 file_name = file_name.replace('.html', '') url = "https://xxxxxx.atlassian.net/wiki/spaces/hr/pages/" + file_name urls.add(url) # 重複しないようにセットに追加 if len(urls) > 0: text_response += "\n\n参考URL:\n\n" + "\n".join(urls) else: text_response = """ 申し訳ありません。入力した質問に関する回答が見つかりませんでした。質問内容を変えるか、#all_citで担当者に問い合わせてください。 """ return text_response
社内ドキュメントのKnowledge baseへのデータ投入
今回はConfluenceのAPIを使って、特定のワークスペースの全ページのHTMLをS3に保存する形で検証を行いました。Knowledge baseではS3に投入しただけでは反映されないので同期処理を実行する必要があります。データ取得の詳細は省きますが、以下のような処理を定期実行することによって、常に最新の情報を更新することができます。
def resource_data_sync(bedrock_data_source_id, bedrock_knowledge_base_id): try: boto3.client('bedrock-agent').start_ingestion_job( dataSourceId=bedrock_data_source_id, knowledgeBaseId=bedrock_knowledge_base_id ) except ClientError: print("Couldn't resource data sync") raise def main(): try: # データ更新に必要な値をセット confluence_user = os.environ.get("CONFLUENCE_USER") confluence_api_token = os.environ.get("CONFLUENCE_API_TOKEN") confluence_domain = os.environ.get("CONFLUENCE_DOMAIN") confluence_export_root_page_id = os.environ.get("CONFLUENCE_EXPORT_ROOT_PAGE_ID") s3_bucket = os.environ.get("S3_BUCKET") s3_bucket_prefix = os.environ.get("S3_BUCKET_PREFIX") bedrock_data_source_id = os.environ.get("BEDROCK_DATA_SOURCE_ID") bedrock_knowledge_base_id = os.environ.get("BEDROCK_KNOWLEDGE_BASE_ID") # 既存で投入済みのs3データを全て削除 clear_files(s3_bucket, s3_bucket_prefix) # コンフルのページをs3にアップロード download_page(s3_bucket, s3_bucket_prefix, confluence_export_root_page_id, confluence_domain, confluence_user, confluence_api_token) # bedrockの同期を呼び出す resource_data_sync(bedrock_data_source_id, bedrock_knowledge_base_id) except Exception as e: print(f"An error occurred: {e}")
デモページ
以上のような基盤を整えつつ、社内ChatAppにデモページの作成を行いました。RAG基盤でのチューニングやデータ前処理が中心で導入自体はそこまで手間ではなく簡単に行うことができます。
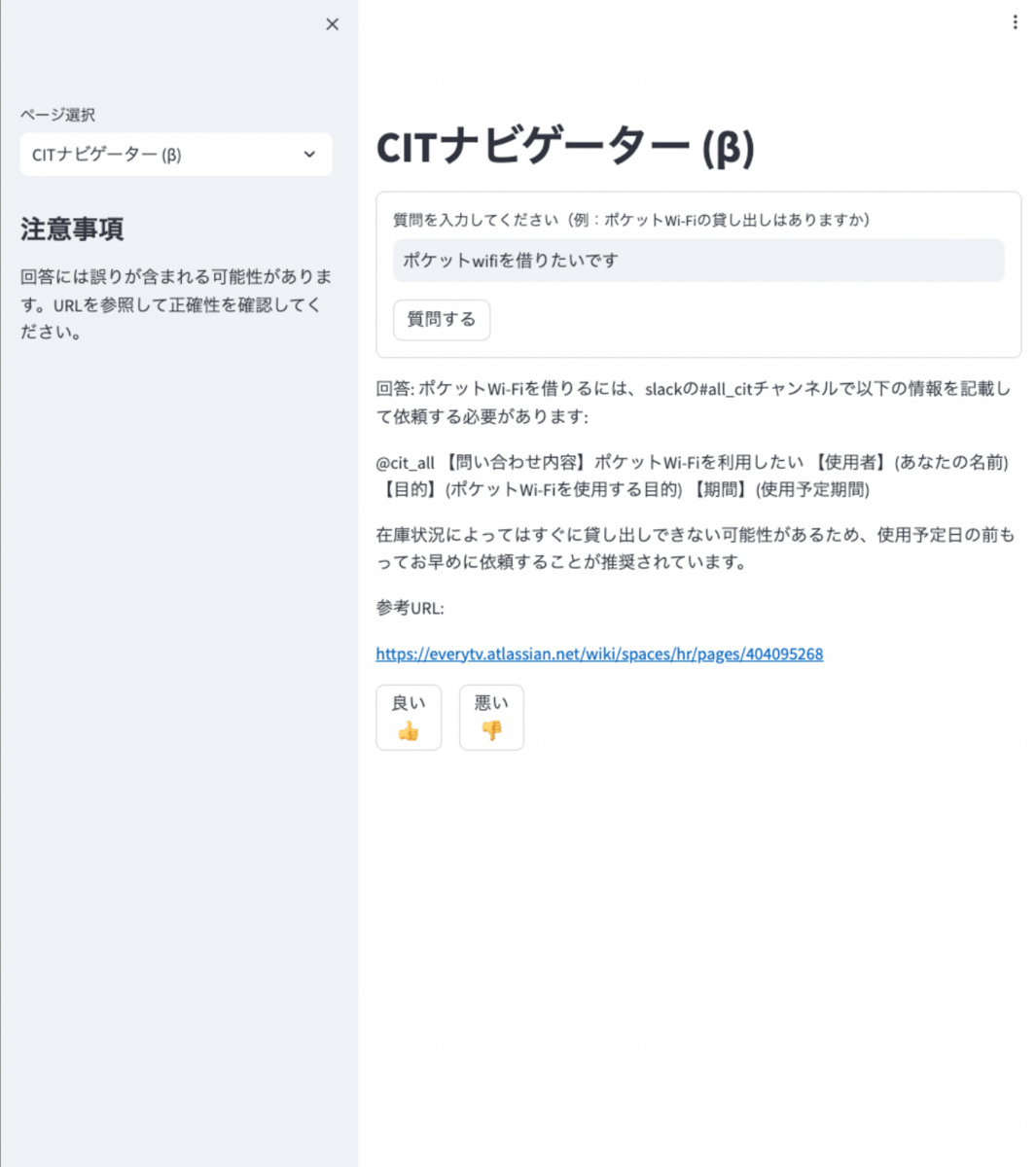
導入上の注意点
Knowledge baseはデフォルトでOpenSearch Serverlessを使用しますが、最低スペックであってもデータ量に関わらず、月200ドル以上がコストとしてかかってきます。エブリーで今後、本格導入を検討する際には、このコストに見合うように社内の課題を整理し、費用対効果を十分に考慮した導入を進める必要があります。また、Knowledge baseでは他のベクトルDBも選択肢として利用可能なので、コスト面も含めて比較検討を進めていきたいです。
RAG基盤開発での課題
Amazon Bedrockに限らず、今回RAG基盤のPoCを行った中で以下の点は開発する中で課題と感じました。
社内ドキュメントに埋め込まれたスライドや画像などテキスト以外の部分の回答精度
テストデータでの検証を行っていく中で誤回答をするケースで一番問題だったのが、ドキュメント内にテキスト以外の埋め込みスライド、画像があるページに基づいた回答でした。今回のConfluence APIでのデータ取得ではデータをHTMLとして保存しましたが、そのままだとテキスト以外の情報のリンクまで辿って解釈できるわけではありません。実際により精度を高めるとなると前処理として参照スライドや画像情報も読み取って保存する必要が出てきそうです。
回答結果の評価
適切な質問と回答のテストデータを用意するのにまず労力がかかります。今回は工数を削減するために、社内ドキュメント情報から生成AIを活用してそれぞれのページごとに想定質問を作成しましたが、それでも適切な質問ではないものもあり、人間が評価しながら修正する必要があります。
また生成された回答の評価もより細かく行うのであればベクトル的な意味の近さで評価するといった工夫も考えないといけません。
精度改善のフィードバックループを回しにくい
精度改善するためには1パラメータでも変更したらテストを回していくようなフィードバックループを回していきたいところですが、それを実行すること自体でも基盤モデルの利用料がかかるため、積み重なると大きなコストになります。
ただ、この問題は直近のGPT-4oの登場でも起こっているように、今後より高精度で安価に利用できるモデルが次々出てくることを考えると無視できる問題になるかもしれません。
終わりに
今回の挑戦weekではチームを組んで、社内ナレッジ活用のためのRAG基盤のPoCを行いました。RAG基盤の構築はすでにいくつもの選択肢があり、専門的な知識が十分になくとも導入自体は簡単に行うことができそうです。
一方でこういったRAG基盤自体も手段の一つでしかなく、とりあえず導入してみるだと結果的に使われずにコストだけかかるものになっていたというケースも少なくなさそうです。今後は前述した通り、こうした技術検証を参考にしつつ、実際に本格導入して社内で使われるツールにするためにしっかりと課題や解決方法を整理して作業の効率化を考えていきたいです。