
開発本部のデータ&AIチームでデータサイエンティストをしている古濵です。
今回は、挑戦WEEKで実装した「レシピ材料の同義語辞書自動化」をLLMで実装した内容をまとめます。
挑戦WEEKに関しては、以下の記事をご覧ください。
背景
ユーザーのクエリによって、同じ意味を表す言葉でも異なる単語が使われることがあります。 デリッシュキッチンを題材に例を挙げると「鶏もも肉」「とりもも肉」「鳥もも肉」などです。 これらの単語同士を同義語(シノニム)、これらの同義語を対応づけたものを同義語辞書と呼びます。
デリッシュキッチンの検索機能では同義語辞書を人手で作成して対応しています。 これは先人たちの苦労が垣間見える瞬間でもあるのですが、検索機能以外で同義語辞書が必要になる場面が多数出てきており、検索機能と同様の運用を継続することは難しくなってきました。
そこで、以下の記事を参考に、同義語辞書の自動化を挑戦WEEKの題材として実装してみました。 約3年前の記事ですが、OpenAI APIなど容易にLLMが活用できる今日では、より簡易的に実装できるようになっていると思います。
手法
記事を参考に、以下のような手順で同義語辞書を作成しました。
- 検索結果に表示されているレシピをタップした時に得られる、その検索キーワードとレシピ材料のペアデータを抽出する。
- 検索キーワードを単語に分割する。
- 検索キーワード中の単語とレシピの材料の出現回数と共起回数を計算する。
- それぞれの語の出現回数と共起回数をもとにNPMI(詳細は後述)を計算する。
- NPMIをもとに同義語ペアの候補を並びかえ、上位5万ペアを抽出する。
- OpenAIのEmbedding APIを用いて同義語ペア(検索キーワードと材料名)をそれぞれベクトルに変換する。
- コサイン類似度を計算し、コサイン類似度とNPMIをもとにそれぞれの閾値を設定して、同義語辞書を出力する。
1. 検索キーワードとレシピ材料のペアデータを抽出
まず、検索ログと視聴ログをJOINして、検索キーワードとそれに紐づくユーザーID, レシピIDを取得します。 検索ログには検索キーワードとユーザーID、視聴ログにはユーザーIDとレシピIDが記録されており、ユーザーIDと日付が一致するものをJOINしました。
厳密に検索→視聴の順にログが記録されたことを保証するには、unixtimeが検索<視聴になっている必要があります。 しかし、ここではユーザーが検索を利用する際は特定の目的を持っていると仮定し、検索→視聴、視聴→検索のどちらの順序でも、同一の興味を持ったユーザー行動として扱うことにしました。
つまり、同じ日のユーザー行動であれば、検索、視聴のどちらが先だったとしても、等しく共起したペアとみなし、そのペアを同義語ペアの候補として抽出しています。 あくまでユーザーの検索キーワードとレシピの材料の共起に関心があり、時系列を深く気にしない方針を取りました。
2. 検索キーワードの分割
以下の文字で、検索キーワードを分割しました。
- 半角スペース
- 全角スペース
- 読点
- カンマ
厳密に単語だけを抽出する場合は形態素解析するなどの前処理が必要ですが、デリッシュキッチンの検索キーワードの多くは単語区切りであることが多いため、これだけでも検証は進められました。
また、レシピの材料に関しては、マスターデータとして1レシピに対して複数の材料が紐づけられています。 材料データは原則単語でまとまっているため、ほとんど前処理することなくそのまま使用しました。
最終的に検索キーワードとレシピ材料のペアデータが以下のようになります。 例として、あるユーザーAとBによって、検索キーワードが「鳥もも肉 照り焼き」「とりもも肉 照り焼き」という検索がされ、そのレシピ結果で表示されたレシピが視聴されたとします。
| 検索キーワード | ユーザーID | レシピID | レシピ材料 |
|---|---|---|---|
| 鳥もも肉 | A | 9876543210 | 鶏もも肉 |
| 鳥もも肉 | A | 9876543210 | しょうゆ |
| 鳥もも肉 | A | 9876543210 | みりん |
| 照り焼き | A | 9876543210 | 鶏もも肉 |
| 照り焼き | A | 9876543210 | しょうゆ |
| 照り焼き | A | 9876543210 | みりん |
| とりもも肉 | B | 9876543210 | 鶏もも肉 |
| とりもも肉 | B | 9876543210 | しょうゆ |
| とりもも肉 | B | 9876543210 | みりん |
| 照り焼き | B | 9876543210 | 鶏もも肉 |
| 照り焼き | B | 9876543210 | しょうゆ |
| 照り焼き | B | 9876543210 | みりん |
3. 検索キーワード中の単語とレシピの材料の出現回数と共起回数を計算
検証のため、2025年3月23日の1日のみのデータを使用しました。 1日の検索ログと視聴ログをペアデータとして、それぞれの出現回数と共起回数を計算します。
共起回数だけだと、どのレシピにも登場する調味料などが多く出現していまいます。 後続のNPMIの計算では、この性質を抑制するのに働きます。
なお、PMIが共起回数が少ないと比較的高い値になりやすいため、共起回数が100回以上のペアデータのみを抽出しました。 データのスケールは異なりますが、参考記事の工夫点を踏襲しています。
4. NPMIの値を計算
検索キーワードの出現確率をP(x)、レシピ材料の出現確率をP(y)、共起確率をP(x, y)とし、以下の式に従って、NPMIを計算します。
しかし、理論上では確率ですが、実務では出現回数と共起回数をもとに計算することが多いかと思います。
検索キーワードの出現回数をC(x)、レシピ材料の出現回数をC(y)、共起回数をC(x, y)、ペアデータの総数をNとし、以下の式に従って、NPMIを計算します。
PMIからNPMIを計算することで、値が-1~1の間に収まります。 これは直感的で解釈しやすくなることがわかると思います。
PMIでは集計するたびに変動があった場合、閾値を設定することが難しくなりますが、NPMIでは-1~1の間に収まるため、閾値を設定することが容易になります。 また、データのスケールが異なる場合(検証は1日のデータですが、実運用は1ヶ月分のデータにしたいなど)にも対応できます。
5. 同義語ペアの候補を抽出
NPMIの値をもとに、上位5万件を同義語ペアの候補として抽出しました。 この数値は、OpenAIのBatch APIの上限に合わせました。
6. 同義語ペアのベクトル化
強い共起があったとしても、その検索キーワードとレシピの材料が似ているとは限りません。 例えば、検索キーワードが「ホットケーキミックス」、レシピの材料が「無塩バター」など、お菓子作りの王道パターンのような組み合わせもNPMIは高くなります。 このような場合では、単語同士がどれだけ似ているかも考慮したくなります。
そこで、OpenAIのEmbedding APIを用いて、検索キーワードとレシピの材料それぞれに対してベクトルを取得します。
7. 同義語辞書の出力
それぞれベクトルをもとに、コサイン類似度を計算します。 これにより、NPMIとコサイン類似度の結果をもとに、それぞれの閾値を決めることで同義語ペアを抽出できます。
ここで抽出した同義語ペアを最終的に同義語辞書として記録します。
以降、この処理を動かし続ければ、日々のユーザー行動を元に同義語辞書を更新できるといった流れです。
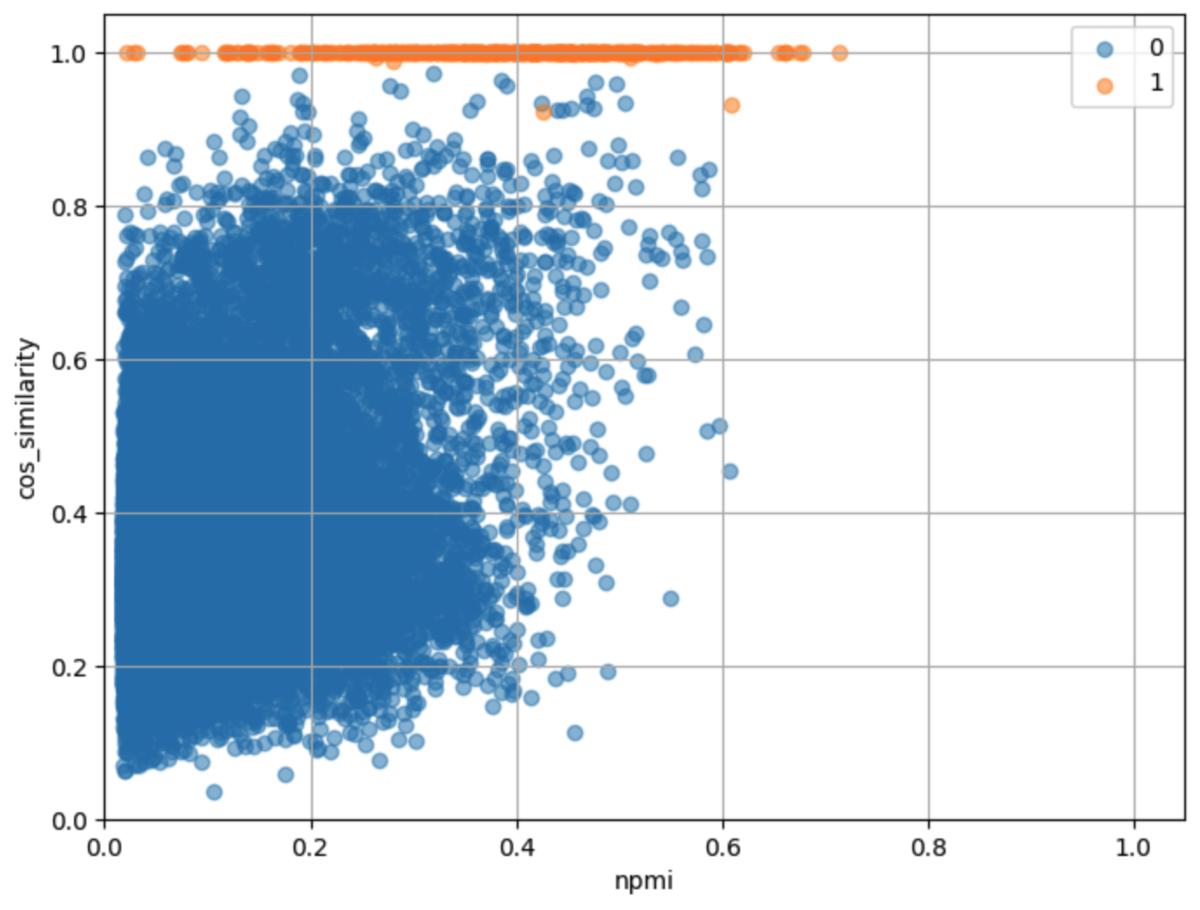
結果
NPMIとコサイン類似度を散布図として可視化しました。 検索キーワードとレシピの材料が完全一致するものを1、それ以外を0としてラベル付けしました。
以降、ラベルが0のデータを結果の対象にします。
NPMIを0.2に固定し、コサイン類似度を変化させた時の結果を以下に示します。 閾値は赤い点線として表現しました。 検索キーワードと材料は閾値付近ものを20件ずつ抽出しています。
| NPMI>=0.2 コサイン類似度>=0.6 |
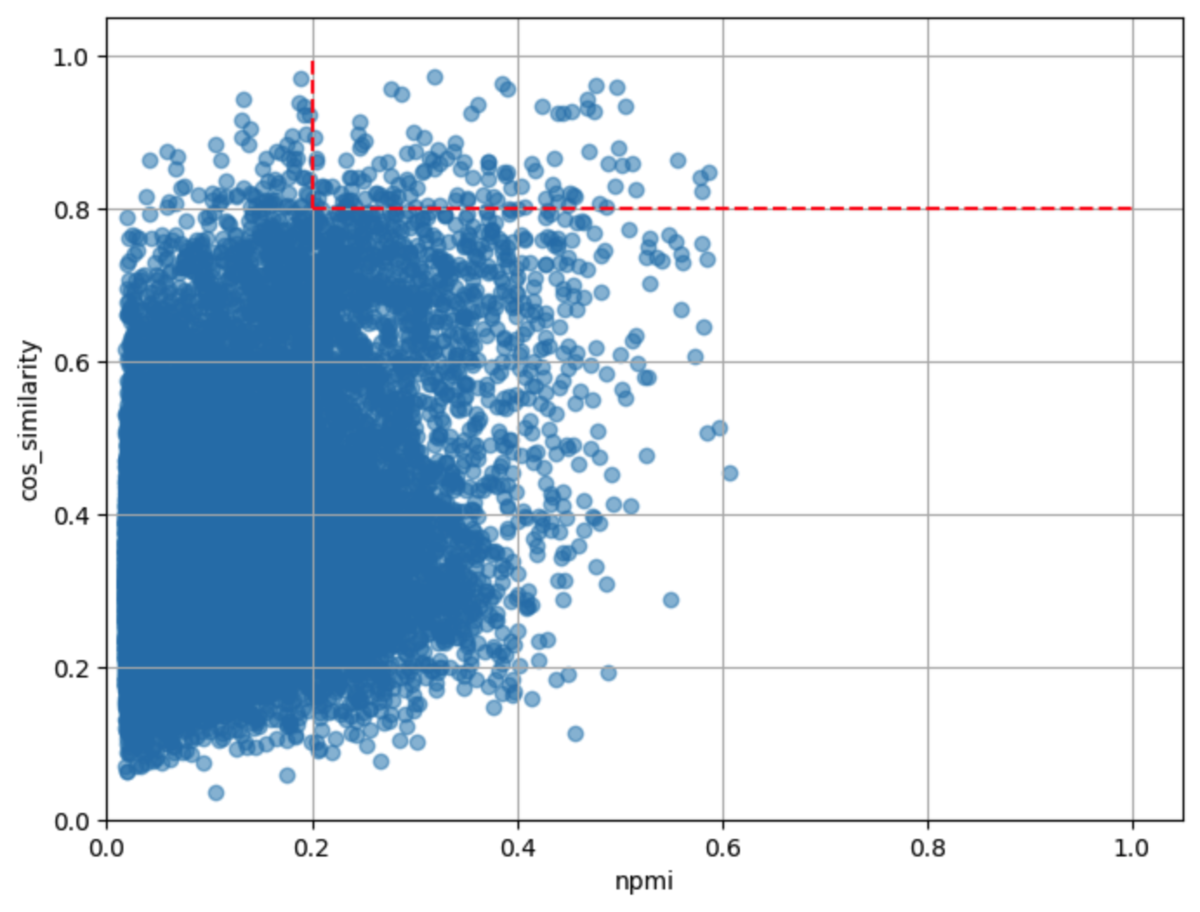
NPMI>=0.2 コサイン類似度>=0.8 |
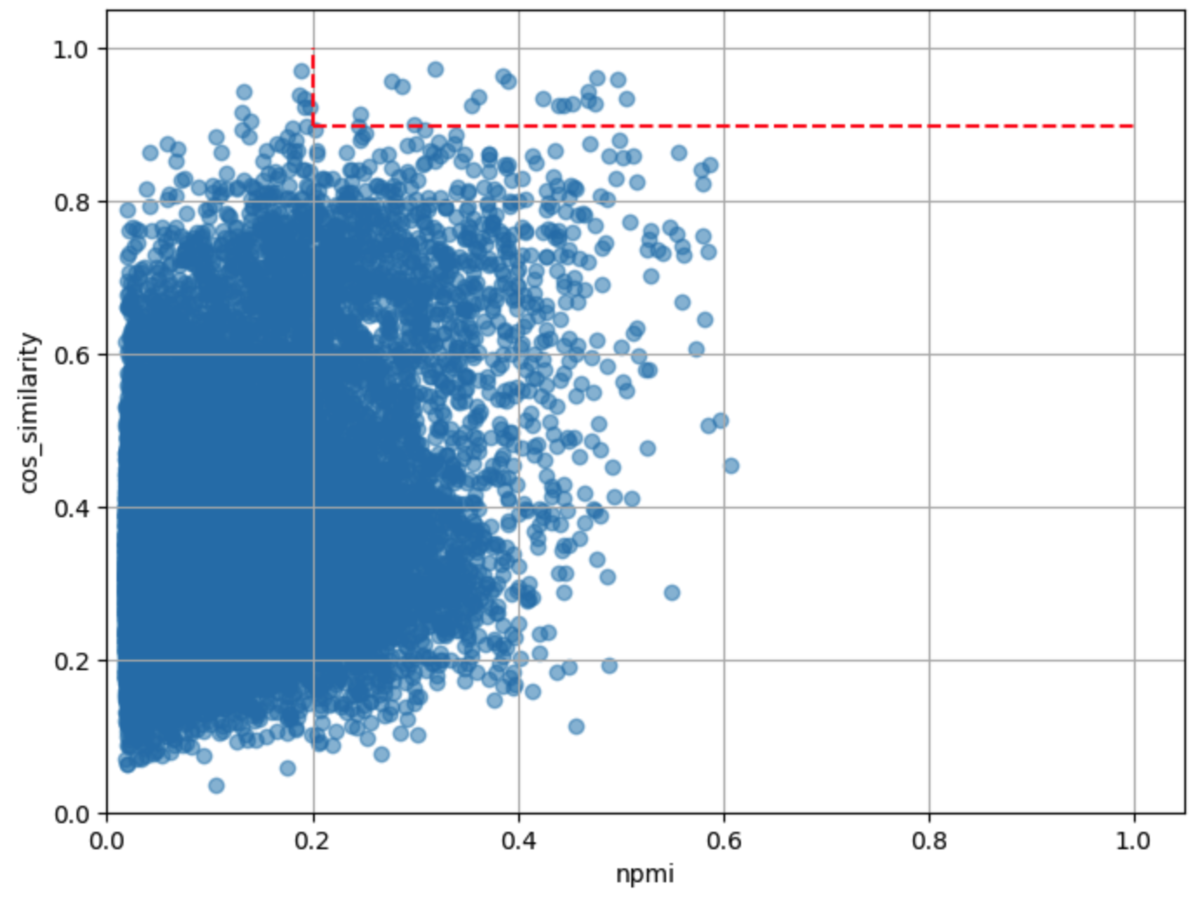
NPMI>=0.2 コサイン類似度上位20件 |
|
|---|---|---|---|
| 散布図 | 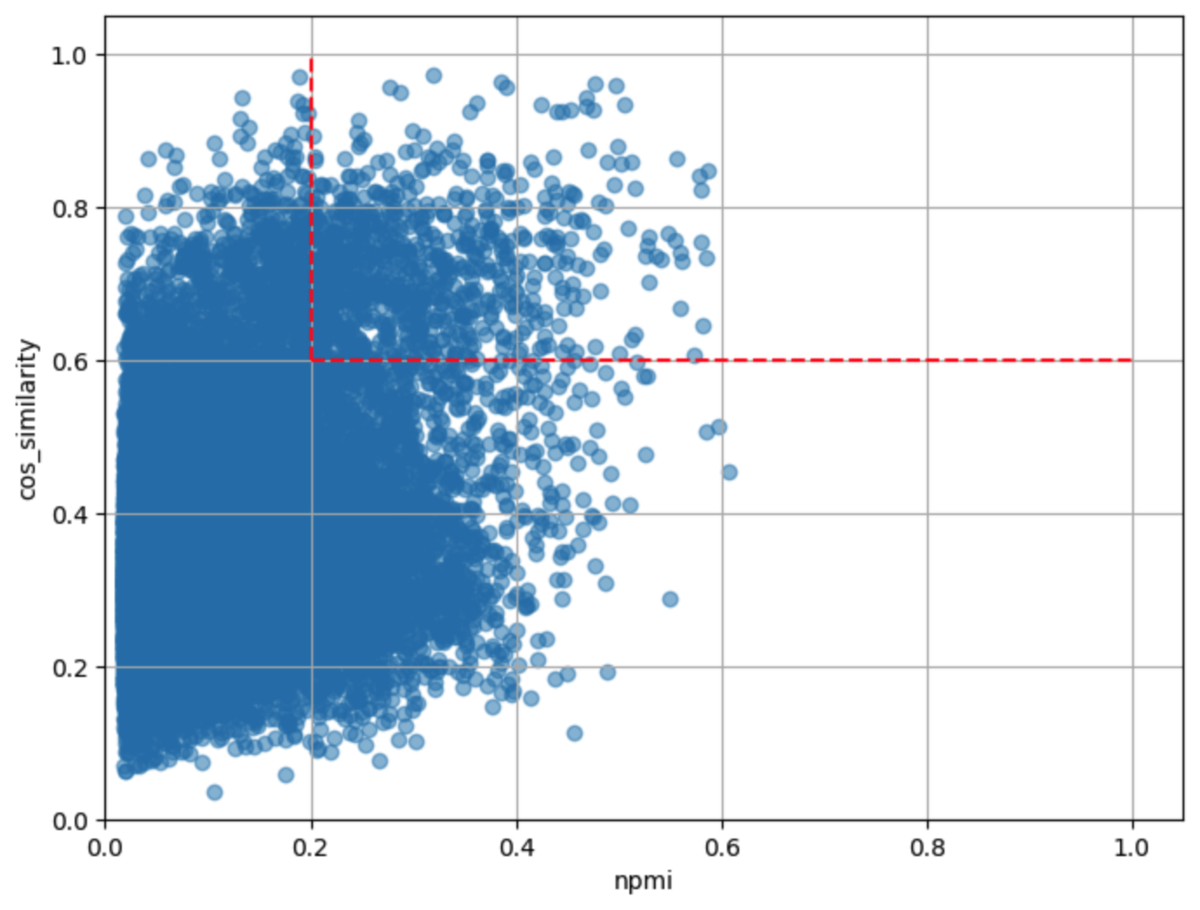 |
 |
 |
| 同義語ペア | 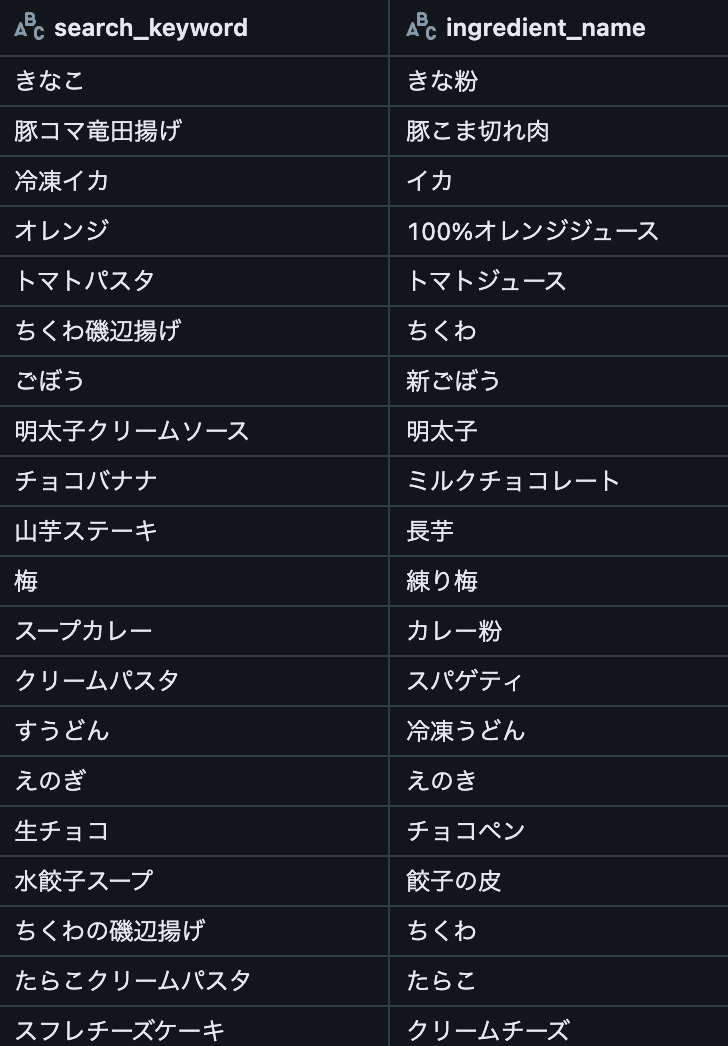 |
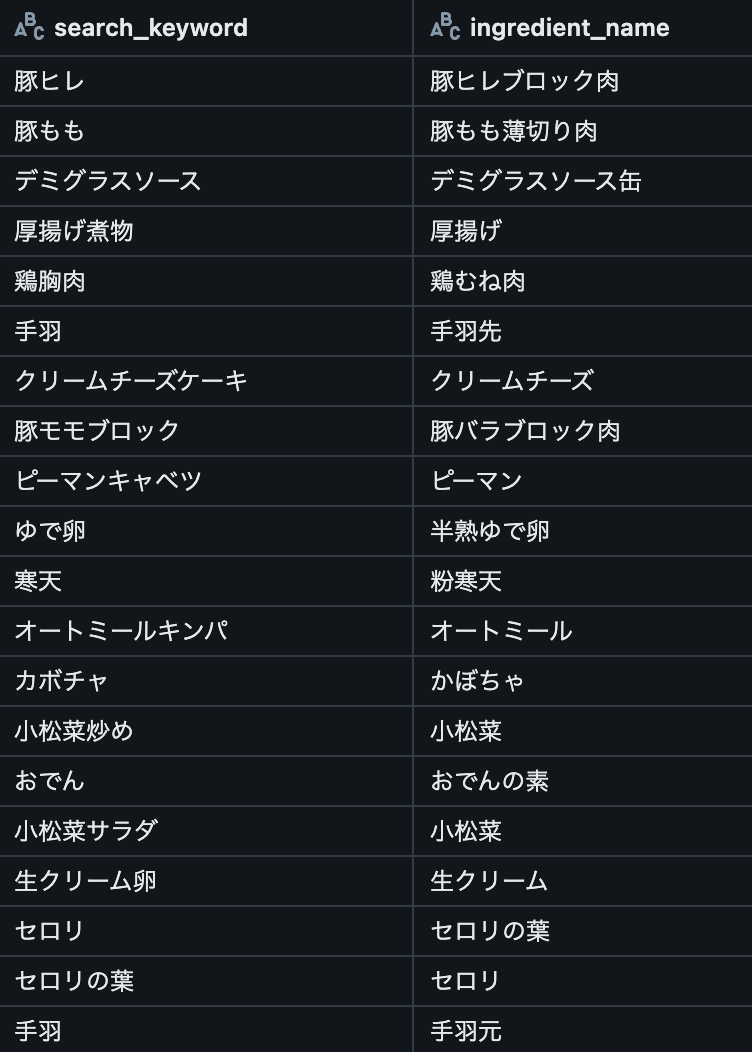 |
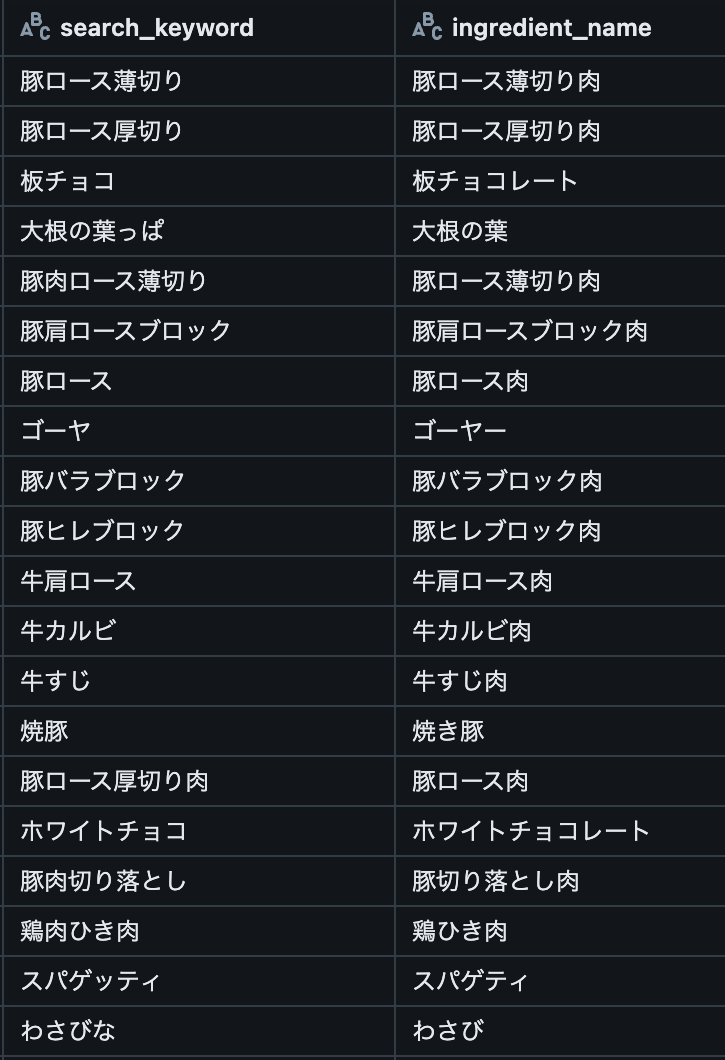 |
| 結果 | 「きなこ」と「きな粉」は問題なさそうですが、「トマトパスタ」と「トマトソース」のようにレシピ名の検索キーワードと材料が同義語ペアにになりました。 | 閾値が高いほどマシになりました。しかし、「小松菜炒め」と「小松菜」のようにレシピ名と材料が同義語ペアになる問題はここでも解決しません。 | 「わさびな」と「わさび」など、食材としては別物でも名前は似ていることが原因で同義語ペアに含まれるケースがあることがわかりました。 |
まとめ
同義語辞書を自動化する仕組みを検証しました。 1日のデータのみを使用した検証ですが、OpenAI APIをフル活用することで、短期間で定性的な検証ができたと思います。
検索機能のロジックに依存する問題(極端に言えば、検索ロジックがランダムに返す場合に破綻するなど)はありますが、ユーザーが入力する検索キーワードをもとに、ある程度の同義語辞書であれば自動化可能なことが確認できたのは良かったです。
今後の課題としては、検索キーワードがレシピ名のときに、材料と同義語ペアになる問題の解消があります。 今回は検索キーワードと材料の共起に着目しましたが、レシピ名もマスターデータとして管理されているため、検索キーワードとレシピ名の共起も考慮する必要があると考えています。例えば、レシピ名との共起性が強い検索キーワードは、材料との同義語ペアにしないなどの工夫ができるかもしれません。
検証全体を通して、完璧な同義語辞書を自動化するまでは難しいなという所感です。 「わさびな」と「わさび」のケースが今回見つかりましたが、似たようなケースが他にも存在するかもしれません。 ただし、完璧な同義語辞書でなくても問題なく運用できる場合もあると思いますので、そのようなケースにおいてこの手法をブラッシュアップし、プロダクトに導入できればと考えています。